






 本文介绍了隐语义模型(LFM)在Top-N推荐系统中的应用原理及实现过程。LFM能自动聚类物品并计算用户对各类别的兴趣度,通过优化参数提升推荐准确性。
本文介绍了隐语义模型(LFM)在Top-N推荐系统中的应用原理及实现过程。LFM能自动聚类物品并计算用户对各类别的兴趣度,通过优化参数提升推荐准确性。
最近在拜读项亮博士的《推荐系统实践》,系统的学习一下推荐系统的相关知识。今天学习了其中的隐语义模型在Top-N推荐中的应用,在此做一个总结。
隐语义模型LFM和LSI,LDA,Topic Model其实都属于隐含语义分析技术,是一类概念,他们在本质上是相通的,都是找出潜在的主题或分类。这些技术一开始都是在文本挖掘领域中提出来的,近些年它们也被不断应用到其他领域中,并得到了不错的应用效果。比如,在推荐系统中它能够基于用户的行为对item进行自动聚类,也就是把item划分到不同类别/主题,这些主题/类别可以理解为用户的兴趣。
对于一个用户来说,他们可能有不同的兴趣。就以作者举的豆瓣书单的例子来说,用户A会关注数学,历史,计算机方面的书,用户B喜欢机器学习,编程语言,离散数学方面的书, 用户C喜欢大师Knuth, Jiawei Han等人的著作。那我们在推荐的时候,肯定是向用户推荐他感兴趣的类别下的图书。那么前提是我们要对所有item(图书)进行分类。那如何分呢?大家注意到没有,分类标准这个东西是因人而异的,每个用户的想法都不一样。拿B用户来说,他喜欢的三个类别其实都可以算作是计算机方面的书籍,也就是说B的分类粒度要比A小;拿离散数学来讲,他既可以算作数学,也可当做计算机方面的类别,也就是说有些item不能简单的将其划归到确定的单一类别;拿C用户来说,他倾向的是书的作者,只看某几个特定作者的书,那么跟A,B相比它的分类角度就完全不同了。
显然我们不能靠由单个人(编辑)或team的主观想法建立起来的分类标准对整个平台用户喜好进行标准化。
此外我们还需要注意的两个问题:
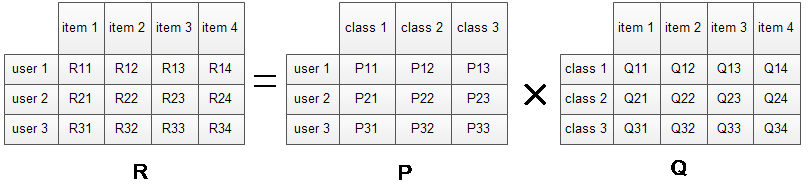 R矩阵是user-item矩阵,矩阵值Rij表示的是user i 对item j的兴趣度,这正是我们要求的值。对于一个user来说,当计算出他对所有item的兴趣度后,就可以进行排序并作出推荐。LFM算法从数据集中抽取出若干主题,作为user和item之间连接的桥梁,将R矩阵表示为P矩阵和Q矩阵相乘。其中P矩阵是user-class矩阵,矩阵值Pij表示的是user i对class j的兴趣度;Q矩阵式class-item矩阵,矩阵值Qij表示的是item j在class i中的权重,权重越高越能作为该类的代表。所以LFM根据如下公式来计算用户U对物品I的兴趣度
R矩阵是user-item矩阵,矩阵值Rij表示的是user i 对item j的兴趣度,这正是我们要求的值。对于一个user来说,当计算出他对所有item的兴趣度后,就可以进行排序并作出推荐。LFM算法从数据集中抽取出若干主题,作为user和item之间连接的桥梁,将R矩阵表示为P矩阵和Q矩阵相乘。其中P矩阵是user-class矩阵,矩阵值Pij表示的是user i对class j的兴趣度;Q矩阵式class-item矩阵,矩阵值Qij表示的是item j在class i中的权重,权重越高越能作为该类的代表。所以LFM根据如下公式来计算用户U对物品I的兴趣度
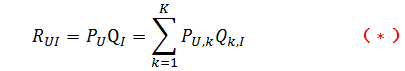 我们发现使用LFM后,
我们发现使用LFM后,
数据集应该包含所有的user和他们有过行为的(也就是喜欢)的item。所有的这些item构成了一个item全集。对于每个user来说,我们把他有过行为的item称为正样本,规定兴趣度RUI=1,此外我们还需要从item全集中随机抽样,选取与正样本数量相当的样本作为负样本,规定兴趣度为RUI=0。因此,兴趣的取值范围为[0,1]。
采样之后原有的数据集得到扩充,得到一个新的user-item集K={(U,I)},其中如果(U,I)是正样本,则RUI=1,否则RUI=0。损失函数如下所示:
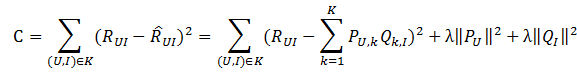 上式中的
上式中的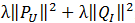 是用来防止过拟合的正则化项,λ需要根据具体应用场景反复实验得到。损失函数的优化使用随机梯度下降算法:
是用来防止过拟合的正则化项,λ需要根据具体应用场景反复实验得到。损失函数的优化使用随机梯度下降算法:
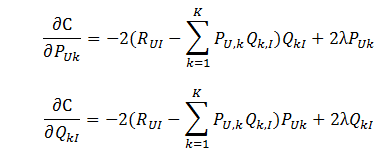
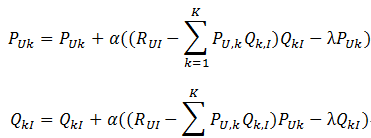
其中,α是学习速率,α越大,迭代下降的越快。α和λ一样,也需要根据实际的应用场景反复实验得到。本书中,作者在MovieLens数据集上进行实验,他取分类数F=100,α=0.02,λ=0.01。
【注意】:书中在上面四个式子中都缺少了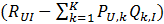
综上所述,执行LFM需要:
本人对书中的伪代码追加了注释,有不对的地方还请指正。
当估算出P和Q矩阵后,我们就可以使用(*)式计算用户U对各个item的兴趣度值,并将兴趣度值最高的N个iterm(即TOP N)推荐给用户。
总结来说,LFM具有成熟的理论基础,它是一个纯种的学习算法,通过最优化理论来优化指定的参数,建立最优的模型。
隐语义模型LFM和LSI,LDA,Topic Model其实都属于隐含语义分析技术,是一类概念,他们在本质上是相通的,都是找出潜在的主题或分类。这些技术一开始都是在文本挖掘领域中提出来的,近些年它们也被不断应用到其他领域中,并得到了不错的应用效果。比如,在推荐系统中它能够基于用户的行为对item进行自动聚类,也就是把item划分到不同类别/主题,这些主题/类别可以理解为用户的兴趣。
对于一个用户来说,他们可能有不同的兴趣。就以作者举的豆瓣书单的例子来说,用户A会关注数学,历史,计算机方面的书,用户B喜欢机器学习,编程语言,离散数学方面的书, 用户C喜欢大师Knuth, Jiawei Han等人的著作。那我们在推荐的时候,肯定是向用户推荐他感兴趣的类别下的图书。那么前提是我们要对所有item(图书)进行分类。那如何分呢?大家注意到没有,分类标准这个东西是因人而异的,每个用户的想法都不一样。拿B用户来说,他喜欢的三个类别其实都可以算作是计算机方面的书籍,也就是说B的分类粒度要比A小;拿离散数学来讲,他既可以算作数学,也可当做计算机方面的类别,也就是说有些item不能简单的将其划归到确定的单一类别;拿C用户来说,他倾向的是书的作者,只看某几个特定作者的书,那么跟A,B相比它的分类角度就完全不同了。
显然我们不能靠由单个人(编辑)或team的主观想法建立起来的分类标准对整个平台用户喜好进行标准化。
此外我们还需要注意的两个问题:
- 我们在可见的用户书单中归结出3个类别,不等于该用户就只喜欢这3类,对其他类别的书就一点兴趣也没有。也就是说,我们需要了解用户对于所有类别的兴趣度。
- 对于一个给定的类来说,我们需要确定这个类中每本书属于该类别的权重。权重有助于我们确定该推荐哪些书给用户。
- 我们不需要关心分类的角度,结果都是基于用户行为统计自动聚类的,全凭数据自己说了算。
- 不需要关心分类粒度的问题,通过设置LFM的最终分类数就可控制粒度,分类数越大,粒度约细。
- 对于一个item,并不是明确的划分到某一类,而是计算其属于每一类的概率,是一种标准的软分类。
- 对于一个user,我们可以得到他对于每一类的兴趣度,而不是只关心可见列表中的那几个类。
- 对于每一个class,我们可以得到类中每个item的权重,越能代表这个类的item,权重越高。
那么,接下去的问题就是如何计算矩阵P和矩阵Q中参数值。一般做法就是最优化损失函数来求参数。在定义损失函数之前,我们需要准备一下数据集并对兴趣度的取值做一说明。
数据集应该包含所有的user和他们有过行为的(也就是喜欢)的item。所有的这些item构成了一个item全集。对于每个user来说,我们把他有过行为的item称为正样本,规定兴趣度RUI=1,此外我们还需要从item全集中随机抽样,选取与正样本数量相当的样本作为负样本,规定兴趣度为RUI=0。因此,兴趣的取值范围为[0,1]。
采样之后原有的数据集得到扩充,得到一个新的user-item集K={(U,I)},其中如果(U,I)是正样本,则RUI=1,否则RUI=0。损失函数如下所示:
是用来防止过拟合的正则化项,λ需要根据具体应用场景反复实验得到。损失函数的优化使用随机梯度下降算法:- 通过求参数PUK和QKI的偏导确定最快的下降方向;
- 迭代计算不断优化参数(迭代次数事先人为设置),直到参数收敛。
其中,α是学习速率,α越大,迭代下降的越快。α和λ一样,也需要根据实际的应用场景反复实验得到。本书中,作者在MovieLens数据集上进行实验,他取分类数F=100,α=0.02,λ=0.01。
【注意】:书中在上面四个式子中都缺少了
综上所述,执行LFM需要:
- 根据数据集初始化P和Q矩阵(这是我暂时没有弄懂的地方,这个初始化过程到底是怎么样进行的,还恳请各位童鞋予以赐教。)
- 确定4个参数:分类数F,迭代次数N,学习速率α,正则化参数λ。
LFM的伪代码可以表示如下:
def LFM(user_items, F, N, alpha, lambda):
#初始化P,Q矩阵
[P, Q] = InitModel(user_items, F)
#开始迭代
For step in range(0, N):
#从数据集中依次取出user以及该user喜欢的iterms集
for user, items in user_item.iterms():
#随机抽样,为user抽取与items数量相当的负样本,并将正负样本合并,用于优化计算
samples = RandSelectNegativeSamples(items)
#依次获取item和user对该item的兴趣度
for item, rui in samples.items():
#根据当前参数计算误差
eui = eui - Predict(user, item)
#优化参数
for f in range(0, F):
P[user][f] += alpha * (eui * Q[f][item] - lambda * P[user][f])
Q[f][item] += alpha * (eui * P[user][f] - lambda * Q[f][item])
#每次迭代完后,都要降低学习速率。一开始的时候由于离最优值相差甚远,因此快速下降;
#当优化到一定程度后,就需要放慢学习速率,慢慢的接近最优值。
alpha *= 0.9
本人对书中的伪代码追加了注释,有不对的地方还请指正。
当估算出P和Q矩阵后,我们就可以使用(*)式计算用户U对各个item的兴趣度值,并将兴趣度值最高的N个iterm(即TOP N)推荐给用户。
总结来说,LFM具有成熟的理论基础,它是一个纯种的学习算法,通过最优化理论来优化指定的参数,建立最优的模型。

















 1528
1528

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









