







 反向传播算法(BP)在多层神经网络中通过更新权重和偏置以最小化输出误差。本文介绍了BP算法为何能最小化代价函数,以及如何更新权重和偏置。误差的反向传播允许从输出层到输入层逐层更新,从而优化网络性能。通过实例展示了BP算法在三层神经网络中的应用,揭示了其工作原理。
反向传播算法(BP)在多层神经网络中通过更新权重和偏置以最小化输出误差。本文介绍了BP算法为何能最小化代价函数,以及如何更新权重和偏置。误差的反向传播允许从输出层到输入层逐层更新,从而优化网络性能。通过实例展示了BP算法在三层神经网络中的应用,揭示了其工作原理。
在一个多层的神经网络中,反向传播算法就是不断的学习这个网络的权值和偏值,采用梯度下降法使得该神经网络的输出值与真实的目标值之间的误差最小。
1,那么为什么更新权值和偏值可以使得代价函数最小化呢? 2,以及如何更新权值和偏值呢?
由于该算法使用了很多的符号,这里需要解释一下各个符号的意义。
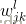
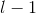
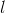

我们的权值为什么要这么标记呢,那是因为我们神经网络中每一层的权值都是以矩阵的方式存储的,那么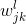
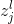
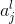
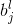
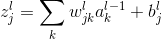
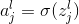
其中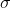
1,那么为什么更新权值和偏值可以使得代价函数最小化呢?
我们训练神经网络的目的就是使得代价函数(比如二次代价函数)最小化,我们其实不必在意代价函数的具体形式,不影响我们对BP算法的理解。但是还是要啰嗦一下,以便说明为什么要对权值和偏值进行更新,比如一个单独的训练样本x,其二次代价函数为:
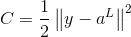
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4676
4676

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









