







在一个多层的神经网络中,反向传播算法就是不断的学习这个网络的权值和偏值,采用梯度下降法使得该神经网络的输出值与真实的目标值之间的误差最小。
1,那么为什么更新权值和偏值可以使得代价函数最小化呢? 2,以及如何更新权值和偏值呢?
由于该算法使用了很多的符号,这里需要解释一下各个符号的意义。
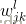
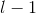
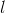

我们的权值为什么要这么标记呢,那是因为我们神经网络中每一层的权值都是以矩阵的方式存储的,那么
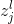
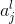
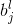
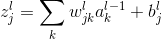
其中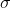
1,那么为什么更新权值和偏值可以使得代价函数最小化呢?
我们训练神经网络的目的就是使得代价函数(比如二次代价函数)最小化,我们其实不必在意代价函数的具体形式,不影响我们对BP算法的理解。但是还是要啰嗦一下,以便说明为什么要对权值和偏值进行更新,比如一个单独的训练样本x,其二次代价函数为:
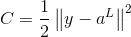
由此,可以看出来这个函数还依赖于实际的目标值y,但是为什么不把它看成y的函数呢?因为一旦一个训练样本被给定,那么他的实际目标值也已经确定了,所以把它看成神经网络输出值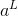
2,以及如何更新权值和偏值呢?
接下来就要介绍BP算法了,首先介绍一个很重要的概念误差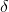
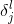

这个调皮鬼在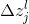
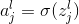
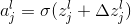
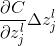
现在这家伙变好了,那么他现在要做的就是,试着找到一个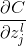
如上所述,
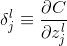
由:
我们可得输出层的误差方程为:
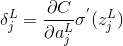
根据下一层神经元的输入是上一层神经元输出的线性组合,那么我们是不是可以由下一层神经元的误差来表示当前层的误差呢?可以,由链式法则可得:

因为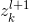
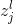
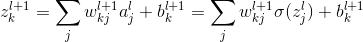
我们对
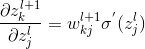
故而可得:
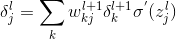
由此我们可以知道第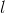
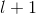
第
那么权值如何更新呢?由于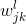
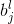
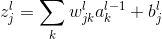
则:
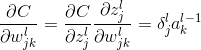
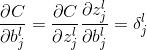
由梯度下降法可得更新规则为:
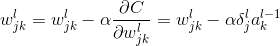
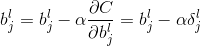
由此我们可以看出,反向传播过程,就是更新神经元误差值的,然后再根据所求出每个神经元的误差值,再正向更新权值和偏值,到此 我们的理论推导已经完事。
网上有个例子,说的很清楚,不过符号标记简化了,但是不耽误理解BP算法的思想,现copy如下:
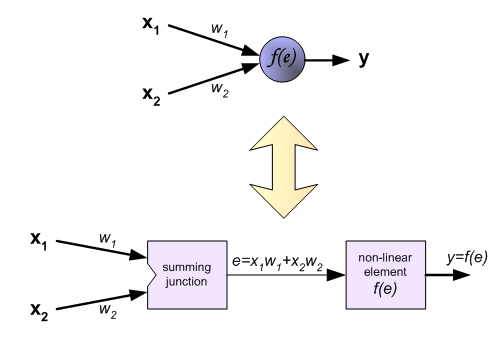
有一个三层的神经网络,两个输入,一个输出,如下所示:
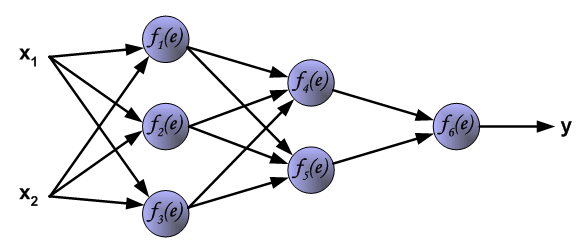
每个神经元分为两个模块,第一个用来处理,输入信号与相应权重的乘积之和,第二个模块依赖于激活函数f,e是一个中间变量,相当于我们上述的每个神经元的输入z,但是在这里他用z标记为实际的目标值。y是每个神经元的输出信号,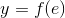
首先我们根据输入信号,来描述前向传播的过程,首先看隐藏层的第一层,如下图:
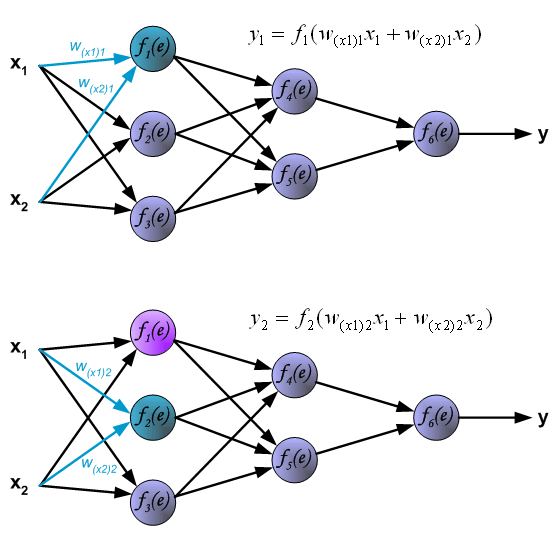
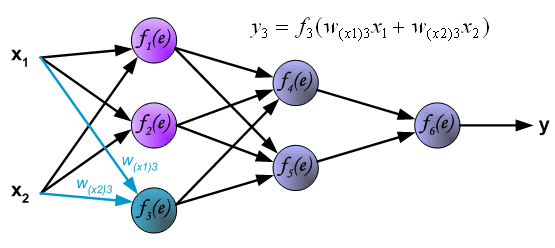
计算隐藏层的第二层,其中
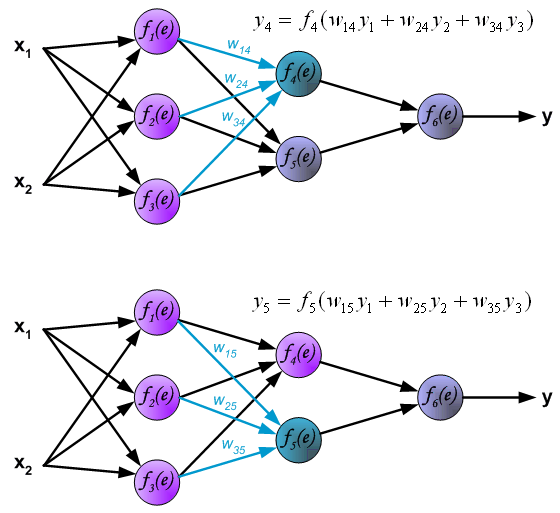
计算输出层,如下:
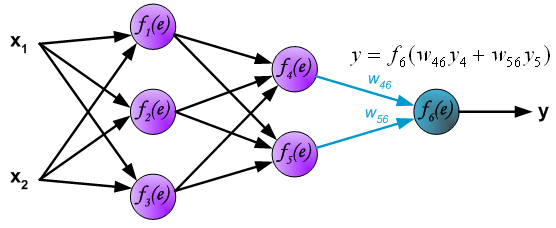
我们到此根据输入信号计算出了输出值,那么与实际的目标值相比较如何呢?我要计算输出层的误差,进而利用反向传播算法不断地更新权值,使得代价最小。再次说明一下,这里的z表示的是实际的目标值。如下图:
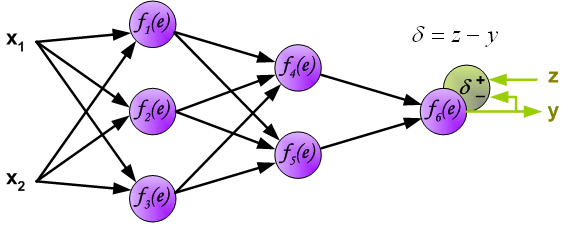
由上述我们的推导可知,我们需要先求出每个神经元的误差值,然后才能更新权值,求误差的过程也是就是反向传播的过程。根据公式,如下图所示:
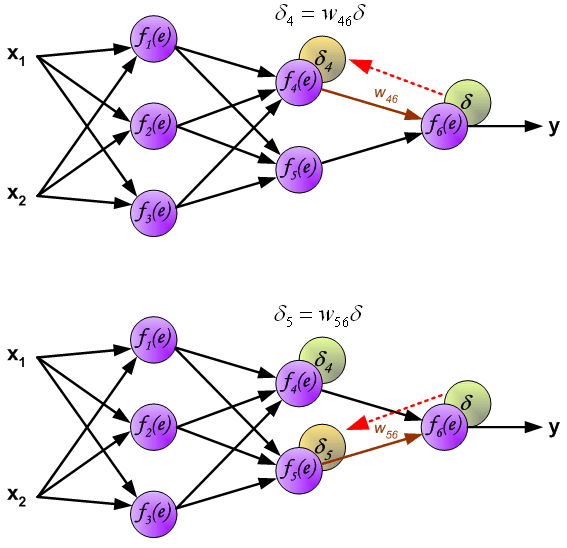
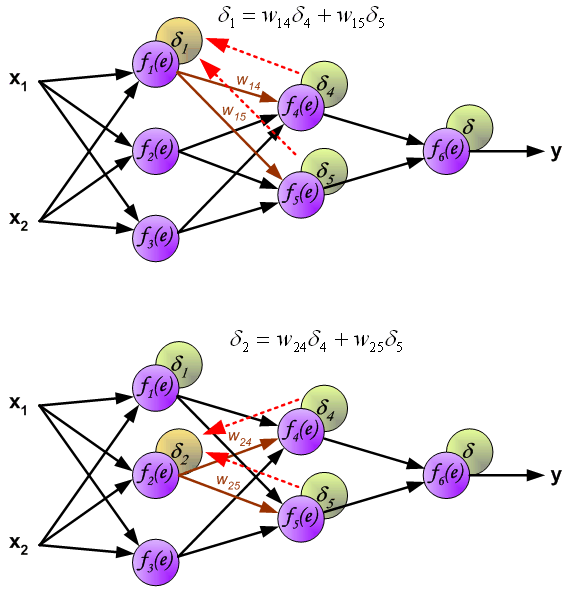
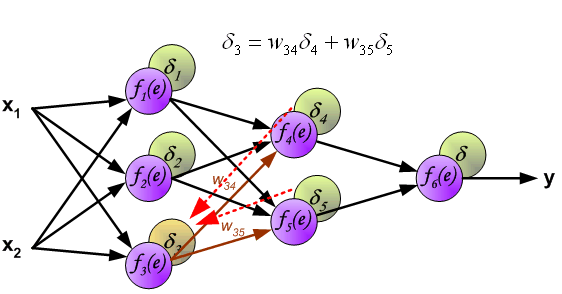
到此我们计算完每个神经元的误差值之后,我们就可以根据误差值来正向更新权值了,交代一下,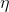
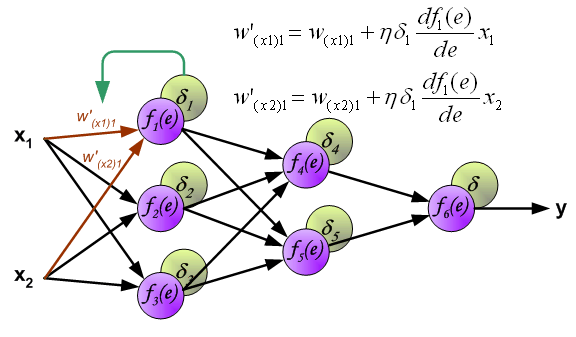
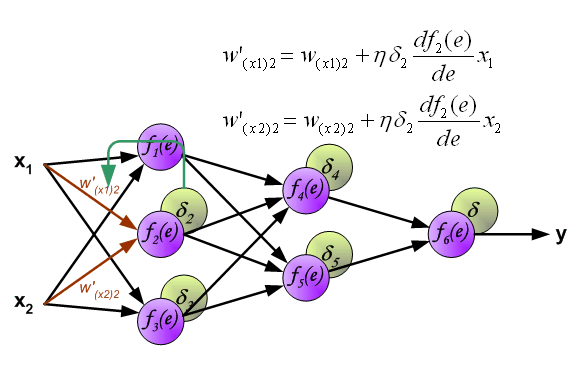
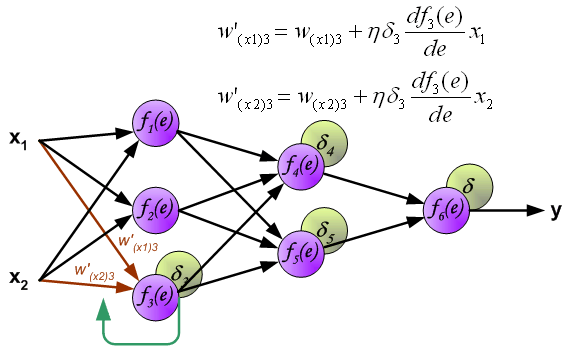
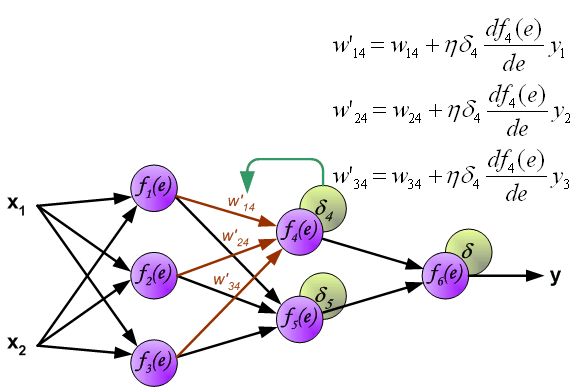
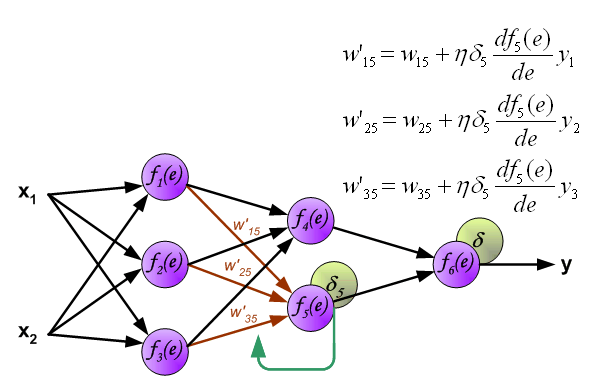
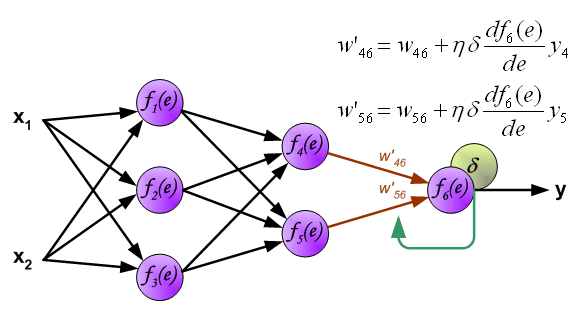
这是一个循环,如果代价函数没有达到我们的要求,就要以此继续下去,直至达到我们的要求。
参考:《Neural Network and Deep Learning》














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









