








现在看文件的读取、写入和编解码问题
读写文件
python的读写文件相当简单,比C和Java都要方便。
下面举个栗子:
#!/usr/bin/python
# Filename: using_file.py
poem = '''\
Programming is fun
When the work is done
if you wanna make your work also fun:
use Python!
'''
f = file('poem.txt', 'w') # open for 'w'riting
f.write(poem) # write text to file
f.close() # close the file
f = file('poem.txt')
# if no mode is specified, 'r'ead mode is assumed by default
while True:
line = f.readline()
if len(line) == 0: # Zero length indicates EOF
break
print line,
# Notice comma to avoid automatic newline added by Python
f.close() # close the file 输出:
$ python using_file.py
Programming is fun
When the work is done
if you wanna make your work also fun:
use Python! 首先,我们把字符串poem写如一个poem.txt中,若不写明绝对路径,则放在当前python的运行路径下。另外,这里也没有指明编码格式,那写入的时候就以系统编码为准。读取的时候,也没有指定绝对路径和解码格式,所以也是按照系统默认的编码来。
上面line=f.readline()是读取下一行的意思,若要读取指定行,可以使用readcache模块中的getline(filename,linenum)函数。
如果要读入指定编码的格式呢?若读入时解码错误,则会是乱码,甚至读入报错。
指定编解码格式的读写文件
读文件:
若读入一个gbk格式的中文文件,我们可以使用下面的语句代替上面的line=f.readline()。其中str是一个专用标识符,表示字符串类。不要在程序中使用以str为名的变量即可。其中的gbk,还可以换成gb2312,utf8等,根据文件编码格式而定。
line = str.decode(f.readline(), 'gbk')注意,gb2312为常用中文和英文的编码,是gbk的子集,字集中没有繁体和生僻字。若有生僻字要使用gbk,否则出现字集中没有的会报错
写文件:
若要用指定格式写文件,则在写内容的时候就用Unicode格式,在写入文件的时候指定编码。因为python程序中默认使用的ASCII编码(并不支持中文),而utf8,gbk等字符都是unicode字符,在程序中应该这样表示:
poem=u'''\
写程序让我很兴奋
但是出bug会很坑
想要少坑用python!
'''
f = file('poem.txt', 'w') # open for 'w'riting
f.write(poem.encode('gbk')) # write text to file using 'gbk' encoding
f.close() # close the file在写入的时候通过poem.encode(‘gbk’)来转化为gbk编码的字符串。
这样输出是正常的,虽然写的时候用了gbk编码,但是读的时候用了gbk解码。
输出:
写程序让我很兴奋
但是出bug会很坑
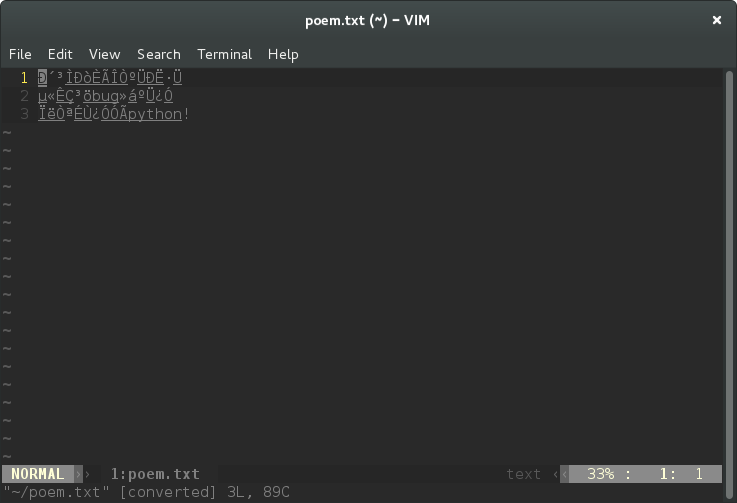
想要少坑用python!再看poem.txt源文件,因为我的机器用的是utf8编码,现在看是乱码(用gbk打开就是正常的了)说明这些字符串已经用gbk进行编码了。















 294
294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









