






 本文详细解析了Unicode编码与GBK编码的区别、实现方式及其在不同场景下的应用,包括UTF-8、UTF-16编码原理,以及如何在iOS上实现显示汉字的Unicode和UTF8代码。同时讨论了GBK作为国家标准的背景与特点,对比了其与Unicode编码的兼容性和占用空间。文章还提供了完整的Unicode对照表和实际应用案例。
本文详细解析了Unicode编码与GBK编码的区别、实现方式及其在不同场景下的应用,包括UTF-8、UTF-16编码原理,以及如何在iOS上实现显示汉字的Unicode和UTF8代码。同时讨论了GBK作为国家标准的背景与特点,对比了其与Unicode编码的兼容性和占用空间。文章还提供了完整的Unicode对照表和实际应用案例。
-------------------------------------------欢迎查看字符编码【专栏】------------------------------------------------------------------
汉字编码之GBK编码【点击】 判断汉字正则表达式更严谨方法【点击】
记事本输入“联通”俩字,关闭再打开乱码 【点击】 iPhone emoji问题牵出的Unicode代理区的思考【点击】
Unicdoe【真正的完整码表】对照表【点击】 开源工程ZipArchive,压缩中文文件名乱码问题【点击】
base64加密,解密,encode,decode,编码详解+实现【点击】
网络传输文本,urlEncode和urldecode的iOS实现【点击】 字符编码的奥秘utf-8, Unicode【点击】
--------------------------------------------------------------------------------------------------------------------------------------------------
起初由于计算机在美国发明,自然大家考虑的是英语如何表示,英语字母总共26个,加上特殊字符,128个字符,7位既一个byte即可表示出来。这个就是大家所熟知的ascill编码。对应关系很简单,一个字符对应一一个byte。
但很快发现,其他非英语国家的文字远远超过ascill码,这时候大家当然想统一字符编码,不同国家出了自己不同的编码方式,中国的gb2312就是自 己做出来的编码方式,这样下去每个国家都有自己的编码方式,来回转换太麻烦了。这时候出现了新的编码方式,unicode编码方式,想将编码统一,所以规 定了每个字符对应的unicode码。
摘自这里
Unicode概述
Unicode(统一码,万国码)是基于通用字符集(Universal Character Set)的标准发展。它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足语言、跨平台进行文本转换、处理的要求。
Unicode是1988年由Apple和Xerox共同建立的一项标准。1991年,成立专门的协会来开发和推动Unicdoe。
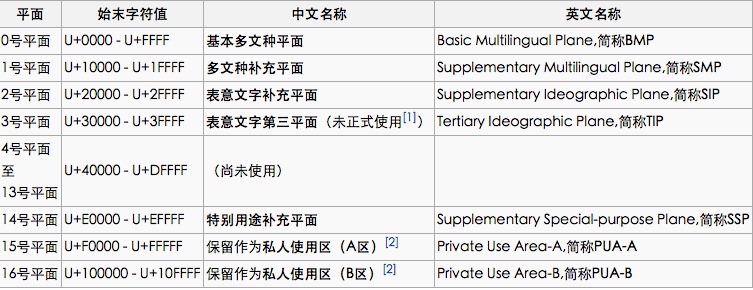
Unicode用数字0到0X10FFFF来映射这些数字,最多容纳1114112个字符。1114112是怎么计算出来的?将0X10FFFF分成0X10和0XFFFF两部分。我们知道0XFFFF是65535,那么 [0,65535] 左右闭区间,总共是65536个。同理,0X10用10进制表示为16,那么 [ 0,16 ] 左右闭区间,总共是17个。所以17乘以65536=1114112.
这里需要注意:大家着重关心第0平面,因为后面第1,2...16所有平面都是通过第0平面中的一个代理区表示的(详见图4)。
世界上各种字符,用Unicode排布
下面讲有些不好理解的东西。
当我们看到0X10FFFF的时候,应该产生一个疑问。就是怎么是三个字节呢?现代计算机都是32位或者64位了吧。如果是32位的话,第一个字节干什么用,是全用0填充么?怎么第二个字节也就用到0x10?
前面我们提到“通用字符集”,简称UCS。目前世界上有两个标准UCS-2用两个字节编码和UCS-4用4个字节编码。那么0X10FFFF当然是UCS-4了,由于现在世界上的文字达不到0X10FFFF的数量,所以通常用UCS-2就足够了。
把0x10FFFF用二进制表示: 0000-00000001-00001111-11111111-1111(只是示意图,请忽略0和1)
如上图,UCS-4根据最高位为0的最高字节分成2^7=128个group。每个group再根据次高字节分为256个平面(plane)。每个平面根据第3个字节分为256行 (row),每行第4字节有256个码位(cell)。每个平面有2^16=65536个码位。如图1,图2所示:一个grouop下的6个平面。

(上图1)
上面我们讲过,14-15-16平面基本都是PUA,最重要的是下面的0-1-2三个平面,特别是第0个平面,也就是下图中色彩斑斓的平面。

(上图2)
图片中每片代表一个平面(这里共6个)。Unicode计划使用了17个平面,一共有17*65536=1114112个码位。在Unicode 5.0.0版本中,已定义的码位只有238605个,分布在平面0、平面1、平面2、平面14、平面15、平面16。其他平面都干嘛了,保留?不清楚。
其中,平面15和16上只是定义了两个各占65534个码位的专用区(Private Use Area),分别是0xF0000-0xFFFFD和0x100000-0x10FFFD。所谓专用区,就是保留给大家放自定义字符的区域,可以简写为PUA。
下面的图片来自维基百科:
(图3)
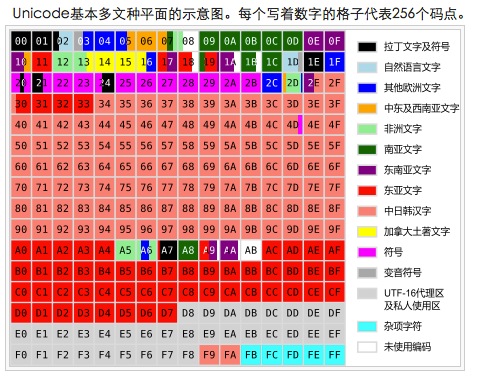
汉字的Unicode位置
我们71226个汉字分别分布在第0个平面,常用27973个,第2个平面43253个,你会发现第2个平面上清一色都是汉字(自豪一下,哈哈)。
Unicode实现方式之【UTF-8】
这里主要讲解UTF-8方式。utf-8是Unicode 的一种存储、传输方式
很多人不知道这两者的关系:UTF是"Unicode/UCS Transformation Format"的首字母缩写,即把Unicode字符转换为某种格式之意。用两个比喻吧:
● 第一个比喻,Unicode就是一个类,UTF-8就是这个类的一个对象。
● 第二个比喻,Unicode是本科高等教育,UTF-8就是一本,UTF-16就是二本,UTF-32就是三本等等。
Unicode是一个标准,UTF-8是实现;UTF-8以字节为单位对Unicode进行编码。它是可变长的编码方式的从表1中也能开出来。从Unicode到UTF-8的编码方式如下:
Unicode编码(16进制) | UTF-8字节流(2进制) | 所在平面 |
0x0000 - 0x007F | 0xxxxxxx | 第0平面 |
0x0080 - 0x07FF | 110xxxxx 10xxxxxx | 第0平面 |
0x0800 - 0xFFFF | 1110xxxx 10xxxxxx 10xxxxxx | 第0平面 |
0x010000 - 0x10FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx | 第1,2,14,15,16平面 |
*以上资源部分摘自百度百科 http://baike.baidu.com/view/40801.htm
Unicode实现方式之【UTF-16】
更详细表述,点击这里UTF-8和GBK的关系
这两个其实没什么关系,没什么瓜葛。
GBK是国家标准GB2312基础上扩容后兼容GB2312的标准。GBK的文字编码是用双字节来表示的,即不论中、英文字符均使用双字节来表示,为了区分中文,将其最高位都设定成1。GBK包含全部中文字符,是国家编码,通用性比UTF8差,不过UTF8(汉字三个字节)占用的数据库比GBD大。
GBK的文字编码是双字节来表示的,即不论中、英文字符均使用双字节来表示,只不过为区分中文,将其最高位都定成1
GBK、GB2312等与UTF8之间都必须通过Unicode编码才能相互转换:
GBK、GB2312 ——> Unicode ——>UTF-8
UTF8——>Unicode ——>GBK、GB2312
对于英文字符较多的网站则用UTF-8节省空间。
ios上实现显示汉字的Unicode和UTF8代码
主要思想:
NSString有个函数是dataUsingEncoding
参数可以选择NSUnicodeStringEncoding 和 NSUTF8StringEncoding然后得到NSData
如果用GBK需要自己生成一个NSStringEncoding,代替NSUTF8StringEncoding
NSStringEncoding gbkEncoding =CFStringConvertEncodingToNSStringEncoding(kCFStringEncodingGB_18030_2000);
NSData包含了首地址和长度。比如“联通”经过Unicode后是4个字节,UTF-8之后是6个字节,都可以从NSData中得到。
然后,用char*指向NSSdata后,一个个将char打印出来就行。如图3所示:

(上图3)
注意:由于intel cpu是采用小端,所以如果不进行大端转换,视觉上是颠倒的,这里我已经给转成大端的了,大端即正常视觉模式。
参考:
base64 解析 http://blog.csdn.net/hherima/article/details/8718050
完整unicode对照表 http://blog.csdn.net/hherima/article/details/9045765

















 547
547

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









