






 本文详细解析了SQL Server内部实现的三种内连接运算类型及其应用条件,包括连接操作的执行逻辑、优化器的选择机制以及不同场景下的连接类型优选。通过测试环境验证了连接类型与表大小、索引存在与否之间的关系。
本文详细解析了SQL Server内部实现的三种内连接运算类型及其应用条件,包括连接操作的执行逻辑、优化器的选择机制以及不同场景下的连接类型优选。通过测试环境验证了连接类型与表大小、索引存在与否之间的关系。
SQL server 内部实现了三种类型的内连接运算,大多数人从来没有听说过这些连接类型,因为它们不是逻辑连接也很少被用于代码中。那么它们什么时候会被用到呢?答案是要依情况而定。这就意味着要依赖于记录集和索引。查询优化器总是智能的选择最优的物理连接类型。我们知道SQL优化器创建一个计划开销是基于查询开销的,并依据此来选择最佳连接类型。
那查询优化器究竟是怎样从内部选择连接类型的呢?
SQLServer在内部为查询优化器对连接类型的选择实现了一些算法,让我们来看下面的一些练习示例,最后来做总结。
首先我给出一些基本的思想,连接是怎样工作什么时候工作,优化器又是怎样决定使用哪种类型的内连接。
· 取决于表大小
· 取决于连接列是否有索引
· 取决于连接列是否排序
测试环境:
内存:4GB
数据库服务器:SQLServer 2008 (RTM)
create table tableA (id int identity ,name varchar(50))
declare @i int
set @i=0
while (@i<100)
begin
insert into tableA (name)
select name from master.dbo.spt_values
set @i=@i+1
end
--select COUNT(*) from dbo.tableA --250600
go
create table tableB (id int identity ,name varchar(50))
declare @i int
set @i=0
while (@i<100)
begin
insert into tableB (name)
select name from master.dbo.spt_values
set @i=@i+1
end
-- select COUNT(*) from dbo.tableB --250600
select * from dbo.tableA A join tableB B
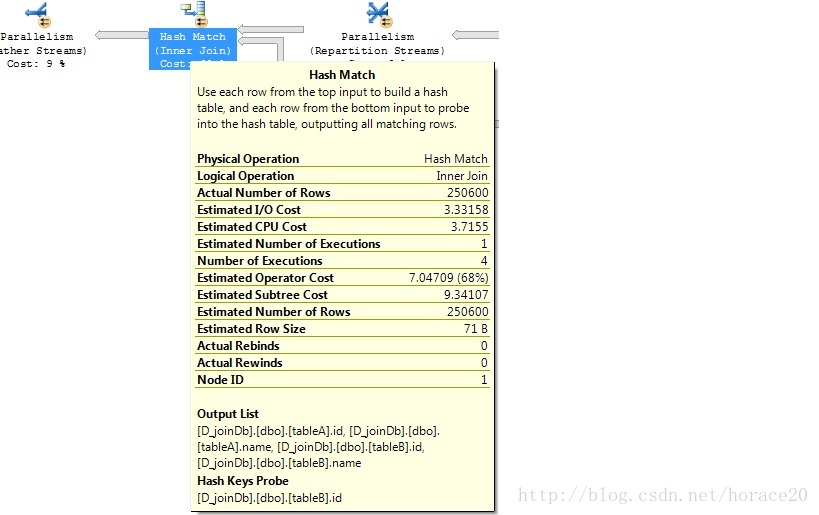
on (a.id=b.id)测试1:大表,没有索引
现在来创建一个聚族索引:
create unique clustered index cx_tableA on tableA (id)
create unique clustered index cx_tableB on tableB (id)测试1:大表,有索引
如果连接中的任何一个表有索引那么将采用Hash Join。我并没有贴上所有结果截图,如果你感兴趣你可以删除任何一个表中的索引来做测试。
测试2:中表,没有索引
首先创建表:
create table tableC (id int identity,name varchar(50))
insert into tableC (name)
select name from master.dbo.spt_values
-- select COUNT(*) from dbo.tableC --2506
create table tableD (id int identity,name varchar(50))
insert into tableD (name)
select name from master.dbo.spt_values
select * from dbo.tableC C join tableD D
on (C.id=D.id)
-- select COUNT(*) from dbo.tableD --2506
测试2:中表,有索引
首先还是创建一个聚族索引:
create unique clustered index cx_tableC on tableC (id)
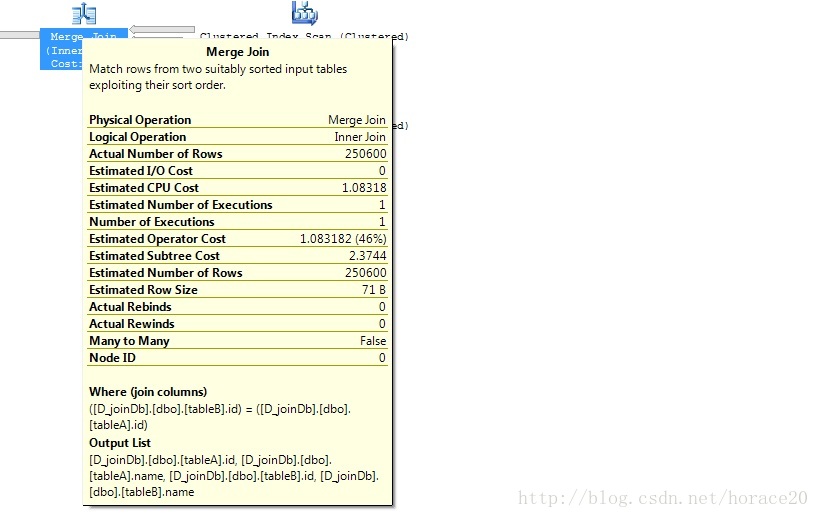
create unique clustered index cx_tableD on tableD (id)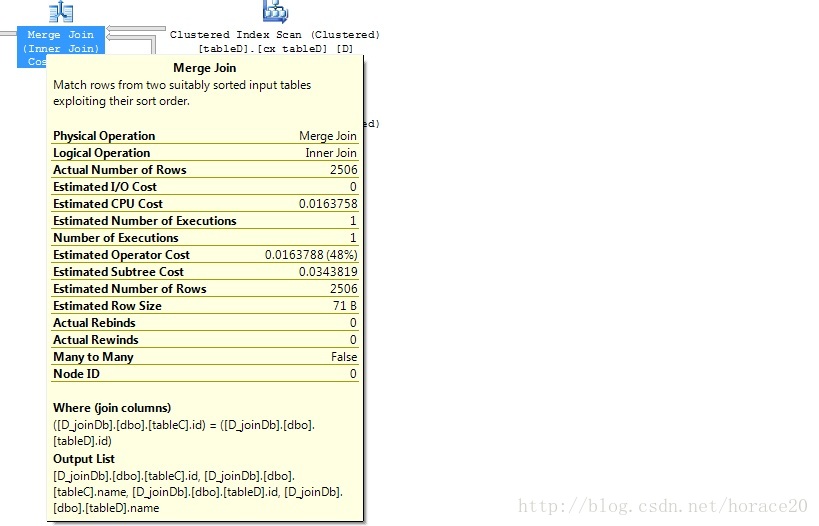
对于中等大小的表,如果连接中的任何一个表有索引,那么将采用Merge Join。
测试3:小表,没有索引create table tableE (id int identity,name varchar(50))
insert into tableE (name)
select top 10 name from master.dbo.spt_values
-- select COUNT(*) from dbo.tableE --10
create table tableF (id int identity,name varchar(50))
insert into tableF (name)
select top 10 name from master.dbo.spt_values
-- select COUNT(*) from dbo.tableF --10
测试3:小表,有索引
创建聚族索引:
create unique clustered index cx_tableE on tableE (id)
create unique clustered index cx_tableF on tableF (id)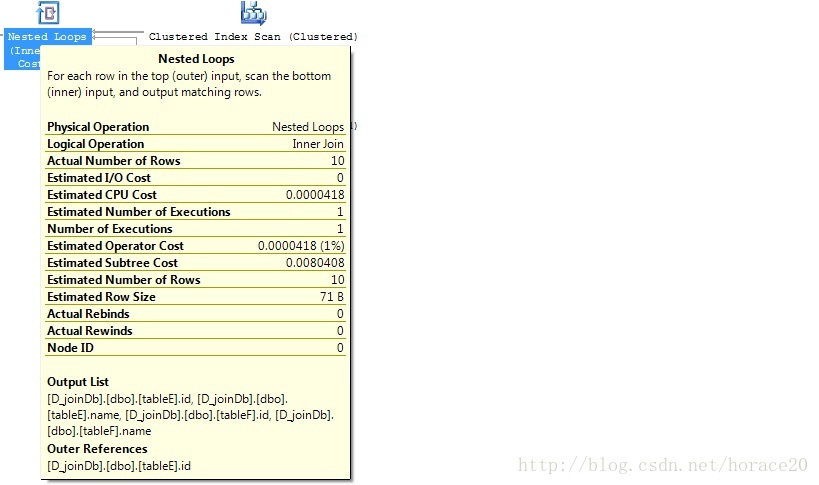
对于小表,如果任何一个表中有索引,那么将采用Nested Loop Join。
同样也可以从另一个方向来做比较,比如大表对比中表对比小表。
select * from dbo.tableA A join tableC C
on (a.id=C.id)
select * from dbo.tableA A join tableE E
on (a.id=E.id)
select * from dbo.tableC C join tableE E
on (C.id=E.id)在这种情况下若所有或部分表都有索引则采用Nested Loop Join,如果都没有则使用HashJoin。
当然你也可以强制优化器使用任何一种连接类型,但这并不是一种值得推荐的做法。查询优化器很智能,能够动态的选择最优的一个。这里我只是显示调用了MergeJoin,所以优化器使用MergeJoin替代本来应使用HashJoin (测试1没有索引)。
select * from dbo.tableA A join tableB B
on (A.id=B.id)option (merge join)
select * from dbo.tableA A inner merge join tableB B
on (A.id=B.id)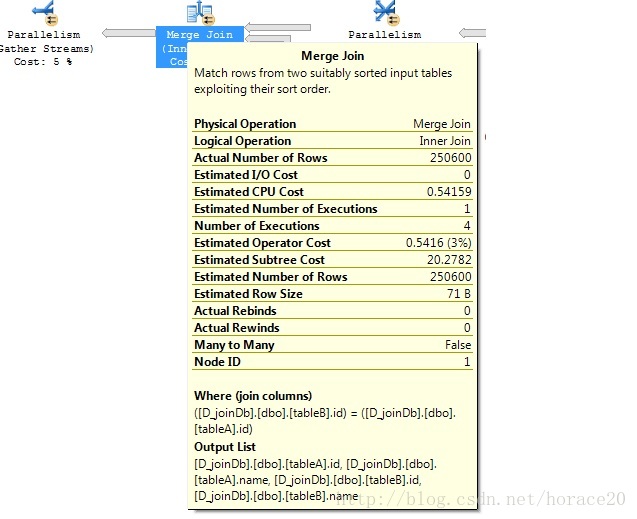
表1 测试唯一聚族索引
根据上表:
Ø 如果两个表都没有索引则查询优化器内部会选择Hash Join
Ø 如果两个表都有索引则内部会选择Merge Join(大表)/NestedLoop Join(小表)
Ø 如果其中的一个表有索引则查询优化器内部会选择Merge Join(中表)/HashJoin(大表)/NestedLoop Join(小表&大表 vs 小表)
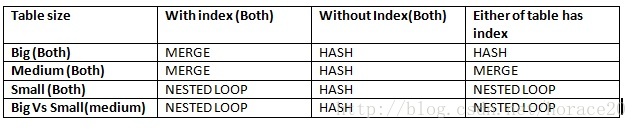
表2 测试聚族索引(createclustered indexcx_tableA ontableA (id))
|
| |||||
| Table size | With index (Both) | Without Index(Both) | Either of table has index |
| |
| Big (Both) | HASH | HASH | HASH |
| |
| Medium (Both) | HASH | HASH | HASH |
| |
| Small (Both) | NESTED LOOP | NESTED LOOP | HASH |
| |
| Big Vs Small(medium) | HASH | HASH | HASH |
| |
根据上表:
这个测试是在没有使用唯一聚族索引下完成,可以知道如果创建索引的时候没有使用UNIQUE关键字则无法保证SQLServer会知道这是UNIQUE数据,所以它默认会创建4字节整数来作为唯一标识符。
根据上表如果创建聚族索引没有使用Unique关键字则不会使用MergeJoin。
谢谢@Dave的邮件,现在加上第二个图表了。
总结:
Merge Join
Merge Join是为那些在连接列上有索引的表,索引可以是聚族索引或者非聚族索引。Merge是这种情况最好的Join类型,需要两个表都有索引,所以它已经排好序并更容易匹配和返回数据。
Hash Join
Hash Join是为那些没有索引或者其中任一个有索引的大表。对于这种情况它是最好的Join类型,为什么呢?因为它能够很好的工作于没有索引的大表和并行查询的环境中,并提供最好的性能。大多数人都说它是Join的重型升降机。
Nested Loop Join
Nested Loop Join是为那些有索引的小表或其中人一个有索引的大表。它对那些小表连接,需要循环执行从一个到另一个表的按行比较的情况下工作最好的。
我希望你现在能理解查询优化器是如何选择最优的查询类型。
原文地址:Merge join Vs Hash join Vs Nested loop join

















 2450
2450

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









