









这篇文章讲述关于如何在windows7下搭建hadoop的开发环境,本人亲测可行,祝你好运!
(发表之后才发现,直接剪切粘贴的图片最后都没有了,这算是CSDN的不足之处啊。不得已又重新剪辑图片保存到本地上传。我也是理解网络上那么多无私奉献者,写博客也是蛮辛苦的,要好好感谢他们啊!)
一、前提条件
1、安装好java8,安装java8的时候最好不要采用默认路径,因为默认路径在“Program Files”目录包含空格,我这里安装路径是D:\appdevelop\jdk1.8
2、安装好eclipse,我这里是Neon Release (4.6.0)
3、把下载的hadoop2.7.3解压到自己要运行的目录,我这里解压目录为D:\appdevelop\deploy\hadoop273
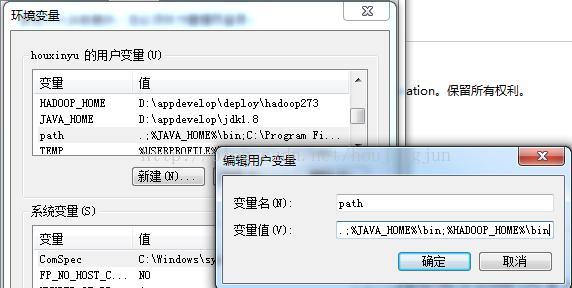
3、设置好环境变量,这里主要有两个:JAVA_HOME,HADOOP_HOME,并设置好path路径,这个很重要,如果不设置HADOOP_HOME启动时会报找不到hadoop,如下图:
二、配置并启动hadoop
1、下载windows下启动hadoop需要依赖的工具和库文件,把hadoop.dll放到c:\windows\System32目录下一份,其他的解压后放到HADOOP_HOME\bin目录下,为了保险起见,我在HADOOP_HOME\sbin目录下也放了一份,可能不需要,我偷懒没测试。
下载地址:http://download.csdn.net/detail/n1007530194/9221605
2、几个配置文件,其中这里只有core-site.xml中配置了一个hdfs文件系统的端口号,其他的都采用默认值
=====core-site.xml=====
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
=====hdfs-site.xml=====下面的路径根据自己需要进行配置,我是在HADOOP_HOME目录下新建的data目录
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/appdevelop/deploy/hadoop273/data/dfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/appdevelop/deploy/hadoop273/data/dfs/datanode</value>
</property>
</configuration>
=====yarn-site.xml=====
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
=====mapred-site.xml=====,该文件默认可能不存在,把mapred-site.xml.template文件拷贝一份,去掉.template后缀后进行配置
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
3、打开cmd命令提示符,进入HADOOP_HOME\bin目录,格式化namenode,运行如下命令

4、如果上面格式化成功,没有报错,则可以启动hadoop了,进入HADOOP_HOME\sbin目录,运行如下命令:
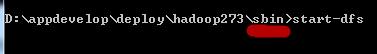
注意两个命令目录位置不同,该命令运行后,会打开两个cmd窗口,分别启动datanode进程和namenode进程(如果要关闭hadoop则运行stop-dfs命令,我们这里要进行测试,暂时保持运行状态)
三、配置eclipse
1、下载hadoop的eclipse插件,并解压到eclipse的plugins目录
插件下载地址:http://download.csdn.net/download/stylereport/9696609
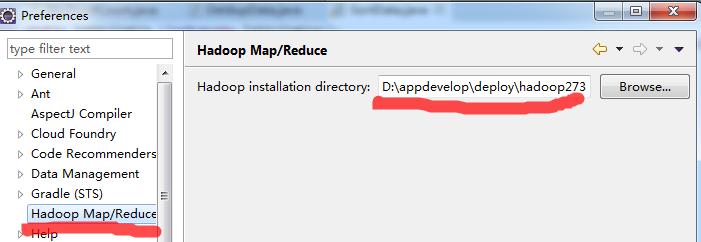
2、重启eclipse,并设置hadoop安装路径
eclipse的Window->Preferences进入进行设置,如下图:
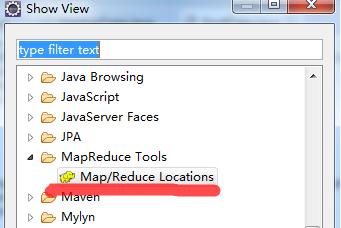
3、把map\reduce设置窗口调出显示,方便设置Window->Show View->Other找到Map/Reduce Locations,单击确定。
经过上面步骤后,在eclipse下面会显示如下(默认是没有下面那行hadoop localhost的,我这里因为已经设置了):
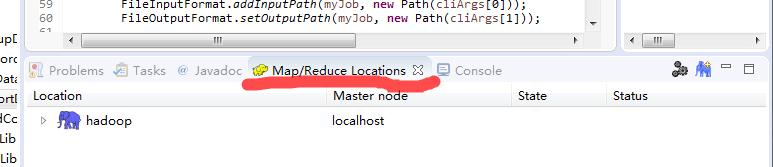
单击带+号的大象图标,就可以进入设置界面了
这一步的设置是最容易出错的地方,我在前面配置文件中提到,只有hdfs文件系统的端口设置为9000了,其他的都是默认的,那么怎么知道我上面应该配置的是50010呢?很多时候,hadoop配置时可能显示可能是50020、50030等,这时候我们可以去看一下启动的hadoop窗口了,有一个namenode窗口,上面显示了我们要配置的这两个端口号

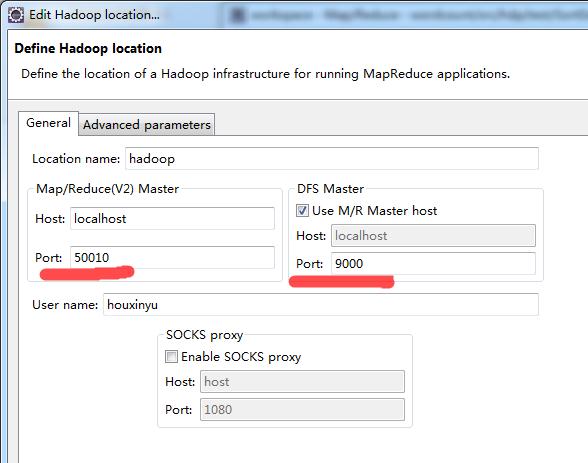
在namenode或datanode窗口会看到9000端口

4、在hdff上根据需要创建文件夹,可以创建、删除、上传文件和文件夹,这里的操作实际上是对hdfs文件系统的操作(你也可以到命令窗口操作,在HADOOP_HOME\bin目录下运行hdfs dfs -mkdir命令可以创建目录)
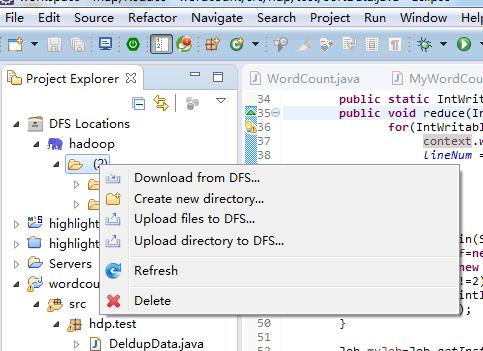
四、创建工程并进行开发调试
1、创建map/reduce工程wordcount
2、新建测试类MyWordCount
package hdp.test;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class MyWordCount {
public static class WordCountMapper extends Mapper<Object, Text, Text, IntWritable>{
private final IntWritable one=new IntWritable(1);
private Text word=new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException{
StringTokenizer stn=new StringTokenizer(value.toString());
while(stn.hasMoreTokens()){
word.set(stn.nextToken());
context.write(word, one);
}
}
}
public static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException{
Configuration conf=new Configuration();
String[] cliArgs=new GenericOptionsParser(conf,args).getRemainingArgs();
if(cliArgs.length!=2){
System.err.println("Usage: MyWordCount <in> <out>");
System.exit(2);
}
Job myJob=Job.getInstance(conf, "my first job");
myJob.setJarByClass(MyWordCount.class);
myJob.setMapperClass(WordCountMapper.class);
myJob.setReducerClass(WordCountReducer.class);
myJob.setCombinerClass(WordCountReducer.class);
myJob.setOutputKeyClass(Text.class);
myJob.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(myJob, new Path(cliArgs[0]));
FileOutputFormat.setOutputPath(myJob, new Path(cliArgs[1]));
boolean isSucced=myJob.waitForCompletion(true);
System.out.println(isSucced);
System.exit(isSucced? 0 : 1);
}
}
3、设置WordCount运行参数
右键wordcount工程,Run As->Run Configurations
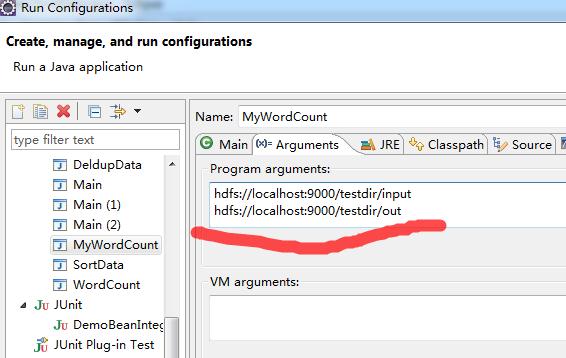
配置运行时的input和output两个参数,我这里把本地文件上传到了input目录,hdfs目录作为输出,其中out目录在hdfs中不存在,如果已经存在则先删除,或使用其他名字
4、经过配置后,运行WordCount程序,一切正常的化在eclipse控制台打印的信息如下
观察cmd中namenode和datanode窗口中信息的变化,程序运行完毕后,可以在eclipse中打开查看运行结果,至此在windows7中搭建hadoop2.7.3开发环境已经完成。
在配置过程中遇到的问题:
1、HADOOP_HOME和path配置出问题时,无法启动hadoop
2、在eclipse中配置map/reduce Locations时,报错往往是配置有问题,主要是端口,而不是插件或eclipse版本问题,如我就遇到如下报错
Hadoop异常:An internal error occurred during: “Map/Reduce location status updater”.
Java.lang.NullPointerException;














 221
221











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









