







查找算法包括:顺序查找,二分查找,分块查找,散列查找,二叉排序树查找,B树
B树用于查找磁盘数据,这里不进行分析
顺序查找
思想:从头到尾一个一个比较,简单,时间复杂度O(n)
java实现:
public static int seqSearch(List<Integer> arr, int key) {
for (int i = 0; i < arr.size(); i++) {
if (arr.get(i) == Integer.valueOf(key)) {
return i;
}
}
return -1;
}二分查找
二分查找要求,待查找的数组有序,且不能用于链表的查找
思想:分而治之,若要查找的key比当前的值小则在左半部分查找,否则在右半部分找,每次缩小一半查找范围。直到找到或者没找到,没找到的条件是起始位置大于终止位置。
时间复杂度:O(logn)
java实现:
//非递归实现
public static int binSearch(List<Integer> arr, int key, int low, int high) {
int middle = (low + high) / 2;
while (low < high) {
if (arr.get(middle) < key) {
low = middle + 1;
} else if (arr.get(middle) > key) {
high = middle - 1;
} else {
return middle;
}
middle = (low + high) / 2;
}
return -1;
}
//递归实现
/**
* 递归二分查找
* @param arr
* @param key
* @param low
* @param high
* @return
*/
public static int binSearchRecur(List<Integer> arr, int key, int low, int high) {
if (low > high)
return -1;
int middle = (low + high) / 2;
if (arr.get(middle) == key) {
return middle;
}
if (arr.get(middle) < key) {
return binSearchRecur(arr, key, middle + 1, high);
} else {
return binSearchRecur(arr, key, low, middle - 1);
}
}单元测试
public class Search {
public static void main(String[] args) {
System.out.println("请输入数组:");
List<Integer> arr = new ArrayList<Integer>();
int key = 0;
Scanner input = new Scanner(System.in);
String strInput = input.nextLine();
String[] inputs = strInput.split(" ");
for (int j = 0; j < inputs.length; j++) {
arr.add(Integer.valueOf(inputs[j]));
}
System.out.println("请输入要查找的数:");
key = input.nextInt();
System.out.println("顺序查找,找到的位置为:" + (seqSearch(arr, key)));
System.out.println("二分查找,找到的位置为:" + binSearch(arr, key, 0, arr.size() - 1));
System.out.println("递归二分查找,找到的位置为:" + binSearchRecur(arr, key, 0, arr.size() - 1));
}
public static int seqSearch(List<Integer> arr, int key) {
for (int i = 0; i < arr.size(); i++) {
if (arr.get(i) == Integer.valueOf(key)) {
return i;
}
}
return -1;
}
public static int binSearch(List<Integer> arr, int key, int low, int high) {
int middle = (low + high) / 2;
while (low < high) {
if (arr.get(middle) < key) {
low = middle + 1;
} else if (arr.get(middle) > key) {
high = middle - 1;
} else {
return middle;
}
//每次缩小一半范围
middle = (low + high) / 2;
}
return -1;
}
/**
* 递归二分查找
* @param arr
* @param key
* @param low
* @param high
* @return
*/
public static int binSearchRecur(List<Integer> arr, int key, int low, int high) {
if (low > high)
return -1;
int middle = (low + high) / 2;
if (arr.get(middle) == key) {
return middle;
}
if (arr.get(middle) < key) {
return binSearchRecur(arr, key, middle + 1, high);
} else {
return binSearchRecur(arr, key, low, middle - 1);
}
}
}分块查找
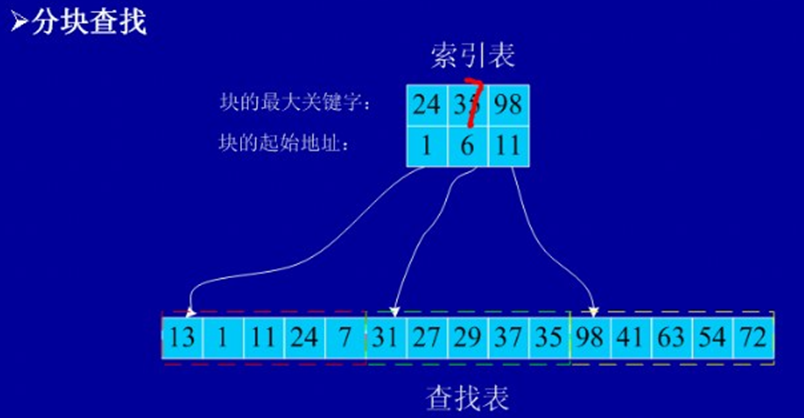
分块查找思想:将表固定长度分成若干块,建立索引表记录块起始地址和该块内的最大值,索引表是有序的,可以使用二分查找和顺序查找,找到key所处的块,在在该块内查找。块内是无序的可以使用顺序查找。
步骤:
1.创建索引表。
2.在索引表内查找,在块内查找。
设表共n个结点,分b块,s=n/b
(分块查找索引表)平均查找长度=Log2(n/s+1)+s/2
(顺序查找索引表)平均查找长度=(S2+2S+n)/(2S)
优点:
①在表中插入或删除一个记录时,只要找到该记录所属的块,就在该块内进行插入和删除运算。
②因块内记录的存放是任意的,所以插入或删除比较容易,无须移动大量记录。
分块查找的主要代价是增加一个辅助数组的存储空间和将初始表分块排序的运算。
分块查找算法的效率介于顺序查找和二分查找之间。
若表中有10000个结点,则应把它分成100个块,每块中含100个结点。用顺序查找确定块,分块查找平均需要做100次比较,而顺序查找平均需做5000次比较,二分查找最多需14次比较。
散列查找
[ 什么是散列表查找 ]
散列技术是在记录的存储位置和它的关键字之间建立一个确定的对应关系f,使得每个关键字key对应一个存储位置f(key)
这个对应关系f()称为散列函数或哈希函数。
采用散列技术将记录存储在一块连续的存储空间中,这块连续存储空间称为散列表或哈希表,那么关键字对应的记录存储位置我们称为散列地址。
[ 散列技术的优缺点 ]
使用散列技术,对于查找来书,简化了比较过程,效率会大大提高
但是散列技术不适合一个关键字对应多条记录的情况,如通过“男”查找班级里所有男生。
散列技术需要解决的另一个问题就是冲突:如k1 != k2, 但是f(k1) == f(k2), 这种现象我们称为冲突,并把k1和k2称为散列函数的同义词。
[ 散列函数构造方法 ]
1. 直接定址法:
2. 数字分析法:
3. 平方取中法:
4. 折叠法:
5. 除留余数法:
6. 随机数法:
[ 处理散列冲突的方法 ]
1. 开放地址法:
2. 再散列函数法:
3. 链地址法:
4. 公共溢出区法:
[ 散列表查找实现 ]
具体程序请查看HashMap,HashSet,Hashtable
当从HashSet集合中查找某个对象时,Java系统首先调用对象的hashCode()方法获得该对象的哈希码,然后根据哈希码找到对应的存储区域,最后取得该存储区域内的每个元素与该对象进行equals方法比较,这样就不用遍历集合中的所有元素就可以得到结论,可见HashSet集合具有很好的对象检索性能。
http://blog.chinaunix.net/uid-26981819-id-4462638.html 源码分析
[ 散列表查找性能分析 ]
如果没有冲突,散列查找是所有查找中效率最高的,因为它的时间复杂度为O(1), 可惜没有冲突的散列只是一种理想情况。
参考:http://java-mzd.iteye.com/blog/827523
参考:equals和hashcode http://www.cnblogs.com/dolphin0520/p/3681042.html
hashmap源码分析 http://blog.chinaunix.net/uid-26981819-id-4462638.html
二叉查找树查找
二叉查找树又叫二叉排序树,是满足 左子节点<根节点<右子节点 的二叉树。
因此查找使用递归很容易实现,难点主要是创建二叉树和维护二叉排序树的规则,这个以后详解。
思想:从根节点开始比较,比节点小则查找左子树,比节点大则查找右子树,相等返回。递归进行。
查找算法递归实现:
结点类型:
static class node{
int value;
node leftChild;
node rightChild;
}
递归查找:
public static node BSTSearch(node head,int key){
if(key==head.value){
return head;
}else if(key < head.value){
return BSTSearch(head.leftChild,key);
}else {
return BSTSearch(head.rightChild, key);
}
}非递归实现:主要循环判断是否相等。
public static node BSTSearch(node head,int key){
while(head.value !=key){
if(key<head.value){
head = head.leftChild;
}else{
head = head.rightChild;
}
if(head == null){
break;
}
}
return head;
}














 526
526

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









