







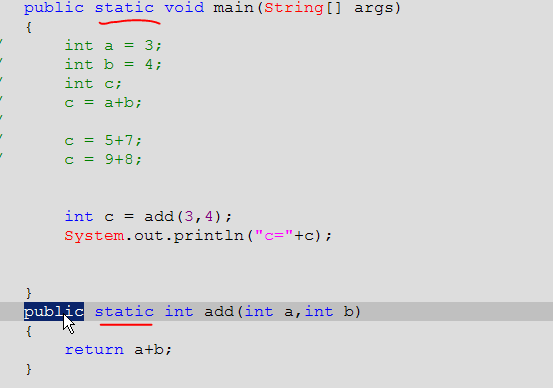
1、静态的主函数main在调用别的函数时,那个函数也要是静态的。
2、java是强类型语言,也即对每一种数据都进行了类型的划分。
3、函数中的return除了能返回值外,还有结束函数的功能,return后面的语句都是不执行的!当返回值类型为void时,函数中最后一句写成 return; 或者不写 return; 这句直接结束也行。而定义函数的好处是就是讲代码块封装,便于提高代码复用。
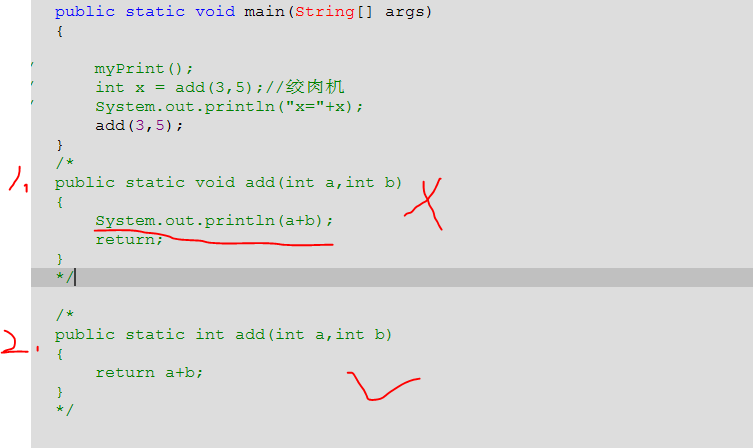
4、函数可以调用函数,他们的性质级别是本质都是函数,所以不能再函数里面定义函数,只能在函数外面定义函数。同时定义函数时还需注意尽量要把函数的结果返回给调用者,函数自己尽量不要过多处理结果,而是由调用者来决定结果该如何处理。下图中第一种定义方法,直接把结果输出了,相当于对结果a+b进行了操作,故这种方法没有第二种定义方法合适。

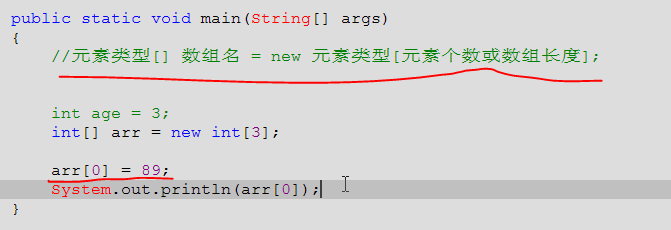
5、变量能装一个数据,但是容器可以装很多数据。数组就是容器的一种。
数组的命名方法如下:Java中 [ ] 就代表了数组,int [ ] 表示这个数组存放的元素都是int类型的。数组刚创建好,若没有赋值,那里面的元素默认都是0。对数组元素进行处理,arr[3](就这种形式)
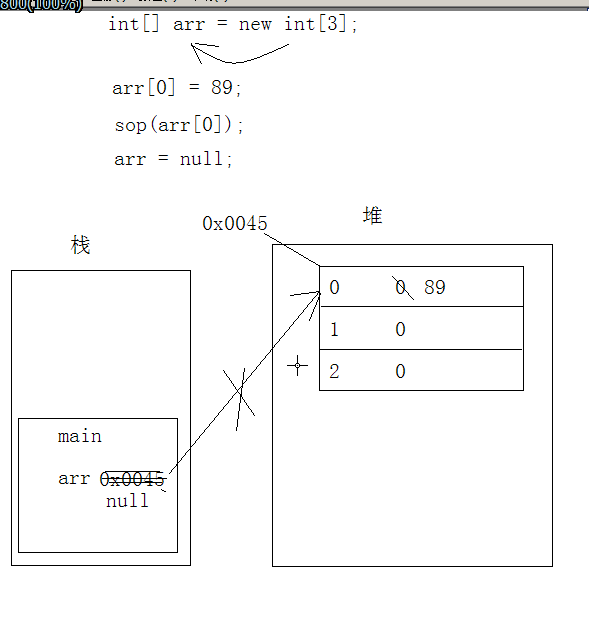
6、内存划分为,其中寄存器供CPU用,2、3供系统用,4、5是重点。局部变量就是定义在方法内的变量,区别于成员变量(定义在方法外,类内部)。
7、实体就是实实在在的个体,用于封装数据,像数组和对象都是是实体。函数运行,main函数入栈,这样函数里的成员变量才能入栈。赋值左边是成员变量,存在栈里,右边是实体,放在堆里,把实体在堆里的地址(引用)返回给栈里的变量存储。堆内存中的数据会默认初始化,故存放在堆里的数组,就算你不初始化,堆也也会默认自动把数组初始化,不同类型数据初始化值不同,有0、0.0、0.0f、false等。‘\u0000’ 是Unicode码中的。基本数据类型一般放在变量中,而实体太大,故只把实体的引用(地址)放进栈里的变量存储。而数组、对象都是引用型数据。new出来的都在堆中,都是引用型数据。

8、编译时主要检测语法是否错误,不检测具体数值,但是运行时要运行程序和数据,所以编译不报错,运行时可能出错。
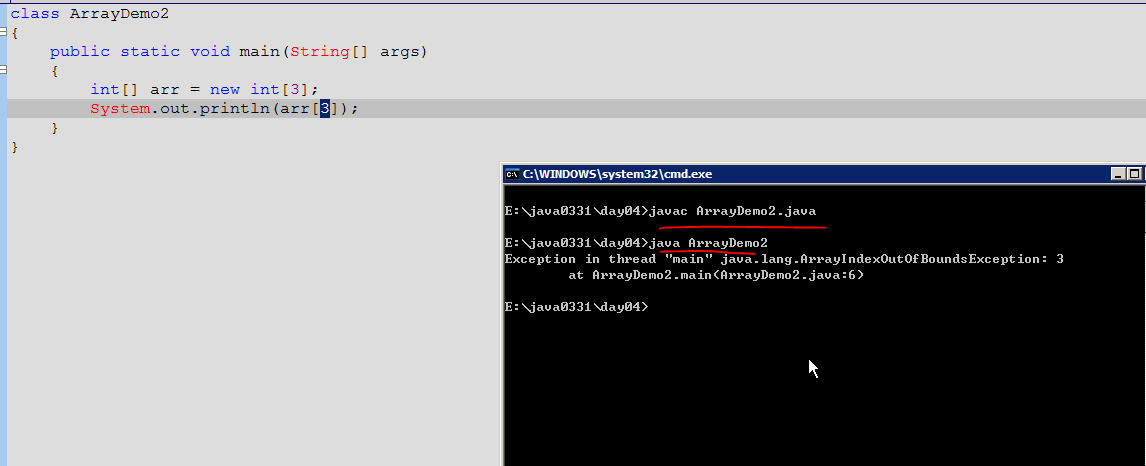
9、@是分界线,[ 说明是数组, I 说明是int类型,数字就相当于是地址。合起来是这个引用型数组的地址(存放在变量arr中)。
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









