







 本文介绍了Hadoop的核心组件HDFS和MapReduce。HDFS采用固定大小的64MB数据块存储文件,并通过NameNode和DataNode实现数据的管理和存储,提供容错机制。MapReduce通过分而治之的策略处理大规模数据,JobTracker负责任务调度,TaskTracker执行任务。HDFS支持批量读写,适用于大数据处理,但不适用于低延迟交互式应用。
本文介绍了Hadoop的核心组件HDFS和MapReduce。HDFS采用固定大小的64MB数据块存储文件,并通过NameNode和DataNode实现数据的管理和存储,提供容错机制。MapReduce通过分而治之的策略处理大规模数据,JobTracker负责任务调度,TaskTracker执行任务。HDFS支持批量读写,适用于大数据处理,但不适用于低延迟交互式应用。
文章来源:
http://blog.csdn.net/huanglong8/article/details/63695488
视频教学来源:
http://www.imooc.com/learn/391
3. Hadoop的核心-HDFS简介
HDFS的文件都被分块存储,并且是固定比例的。默认大小是64MB。块是作为处理的逻辑单元。
有两个节点概念:
1. NameNode是管理节点,存放文件元数据
主要包括 文件和数据块的映射表,数据块与数据节点的映射表。
2. DataNode是工作节点,存放的是真正的数据块。
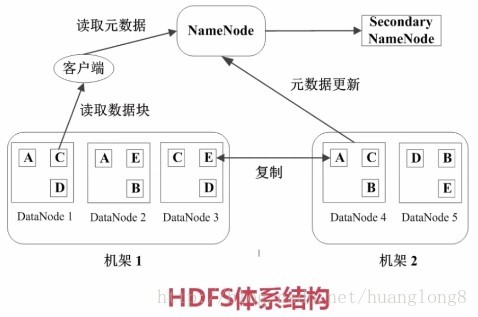
基本可以理解为,当有 一个 大小为 1GB的文件 进行存储时,HD会将其划分为 64MB * 16 。也就是 会将这个文件拆成 16个块,将每块分别存储到指定位置,通过映射表来进行管理。
快速存放,副本三份。容错处理。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









