







这篇博客我们将用java来实现基本的爬虫数据抓取操作,基本思路就是通过java访问url,然后拿到返回的html文档,并用jsoup解析。
首先我们来看下需要抓取的页面,以我自己的csdn博客列表页面为例。我们将每篇博客的链接地址,文章标题以及摘要抓取出来。下面是代码实现:
public class WhxCsdnCrawler {
public static void main(String[] args) {
String userName="hx_wang007";
String csdnUrl="http://blog.csdn.net/"+userName;
Connection conn = Jsoup.connect(csdnUrl);//获取连接
//设置请求头,伪装成浏览器(否则会报403)
conn.header("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36");
try { //设置超时时间,同时Document对象中封装了返回的html文档
Document doc=conn.timeout(100000).get();
String url;
String title;
String desc;
//得到博客列表
Element element=doc.getElementsByClass("skin_list").first();
for(Element ele:element.children()){
Element e=ele.getElementsByClass("list_c_t").first().child(0);
url = e.attr("href");
url="http://blog.csdn.net"+url;
title = e.text();
Element e1=ele.getElementsByClass("list_c_c").first();
desc=e1.text();
System.out.println(url+":"+title+":"+desc);
}
} catch (IOException e) {
e.printStackTrace();
}
}
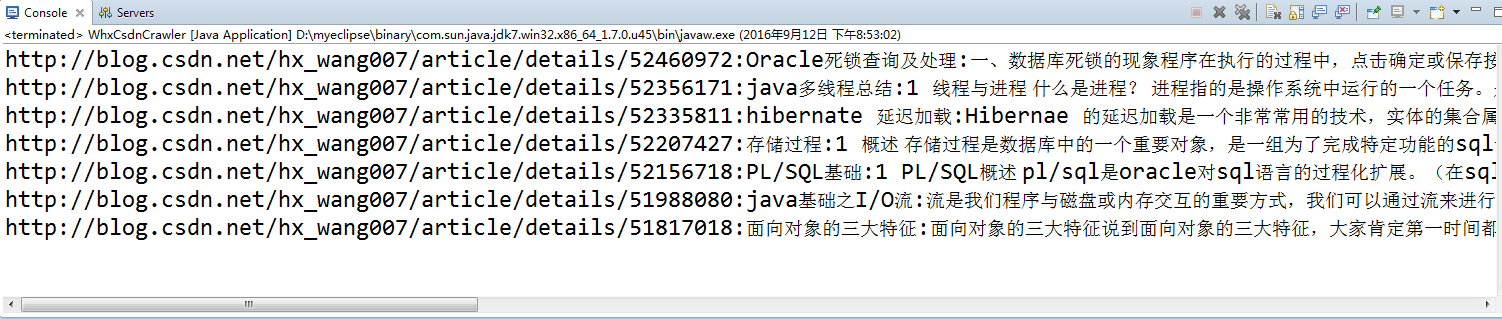
}下面是运行结果:















 2515
2515

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









