




 本文介绍了LDA(Latent Dirichlet Allocation)主题模型的基本原理,解决了PLSA模型中的过拟合问题。LDA通过引入文档-主题分布的狄利克雷先验,减少了参数数量。在训练过程中采用变分推断方法,文中给出了关键的迭代公式。此外,还概述了源码中的关键函数,如`doc_e_step`和`lda_inference`,并强调了在新文档中预测topic分布的使用。
本文介绍了LDA(Latent Dirichlet Allocation)主题模型的基本原理,解决了PLSA模型中的过拟合问题。LDA通过引入文档-主题分布的狄利克雷先验,减少了参数数量。在训练过程中采用变分推断方法,文中给出了关键的迭代公式。此外,还概述了源码中的关键函数,如`doc_e_step`和`lda_inference`,并强调了在新文档中预测topic分布的使用。
Blei
基本介绍:
topic model,之前已经介绍过(
http://blog.csdn.net/hxxiaopei/article/details/7617838)
topic model本质上就一个套路,在doc-word user-url user-doc等关系中增加topic层,扩充为2层结构,一方面可以降维,另一方面挖掘深层次的关系,用户doc word user url的聚类。
LDA的理论知识不介绍太多,基本就讲了原理以及推导两个内容,原理比较简单,推导过程貌似很简单,就一个变分加上一些参数估计的方法就搞定了,但是具体的细节还没明白,以后慢慢研究。
简单介绍下基本原理以及有意义的几个公式:
plsa作为topic-model ,每篇文档对应一系列topics,每个topic对应一批terms,有如下问题:
1.每篇文档及其在topic上的分布都是模型参数,也就是模型参数随着文档的数目增加而增加,这样容易导致overfitting
2.对于new doc,如何确定其topic 分布
LDA解决这个问题,没必要把每个doc-topic分布作为模型参数,为doc-topic分布增加一个先验概率,限制整体上文档的topic分布,具体先验分布的作用,之前已经介绍过。
doc-topic分布服从多项分布,狄利克雷分布是其共轭先验。
这样参数的个数就变成K + N*K, N为词个数,K为topic个数,与文档个数无关。
如果我想知道一个文档的topic分布怎么办?下面介绍下train以及predic的方法。
作者采用了
varitional inference进行推导,过程就免了,列出来几个重要的公式:
论文中几个重要公式:
概率模型:
D 表示文档集合,最后就是保证P(D|α,β)最大。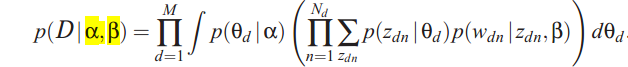
phi的迭代公式,表示文档中单词n在topic i上的分布:
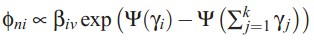
gamma的迭代公式,文档在topic上的分布
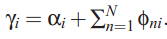
Beta的迭代公式,model中topic-word分布:
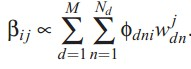
alpha的迭代公式,model中文档-topic分布的先验参数,利用梯度下降法即可求解:
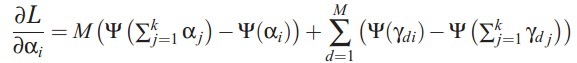
LDA最核心的迭代公式,针对每一篇文档,计算每个词的topic分布,从而计算文档的topic分布:

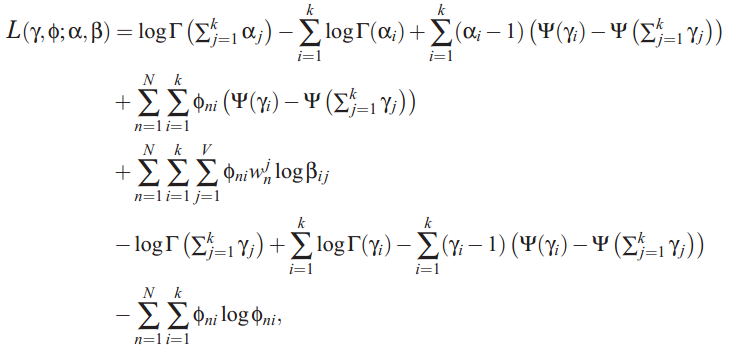
基本逻辑:
1.初始模型参数,开始迭代,执行2,3,4,直至收敛
2.针对每一篇文档,初始gamma以及phi参数,迭代该参数,直至收敛
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









