




 本文介绍YOLOv2与YOLO9000两大物体检测系统的创新技术,包括BatchNormalization、高分辨率分类器、卷积锚框等改进措施,以及WordTree、联合训练算法等新方法,实现对9000种物体的实时检测。
本文介绍YOLOv2与YOLO9000两大物体检测系统的创新技术,包括BatchNormalization、高分辨率分类器、卷积锚框等改进措施,以及WordTree、联合训练算法等新方法,实现对9000种物体的实时检测。
原文下载:https://arxiv.org/pdf/1612.08242v1.pdf
工程代码:http://pjreddie.com/darknet/yolo/
目录
摘要
- 提出YOLO v2 :代表着目前业界最先进物体检测的水平,它的速度要快过其他检测系统(FasterR-CNN,ResNet,SSD),使用者可以在它的速度与精确度之间进行权衡。
- 提出YOLO9000 :这一网络结构可以实时地检测超过9000种物体分类,这归功于它使用了WordTree,通过WordTree来混合检测数据集与识别数据集之中的数据。
- 提出了一种新的联合训练算法( Joint Training Algorithm ),使用这种联合训练技术同时在ImageNet和COCO数据集上进行训练。YOLO9000进一步缩小了监测数据集与识别数据集之间的代沟。
简介
目前的检测数据集(Detection Datasets)有很多限制,分类标签的信息太少,图片的数量小于分类数据集(Classification Datasets),而且检测数据集的成本太高,使其无法当作分类数据集进行使用。而现在的分类数据集却有着大量的图片和十分丰富分类信息。
文章提出了一种新的训练方法–联合训练算法。这种算法可以把这两种的数据集混合到一起。使用一种分层的观点对物体进行分类,用巨量的分类数据集数据来扩充检测数据集,从而把两种不同的数据集混合起来。
联合训练算法的基本思路就是:同时在检测数据集和分类数据集上训练物体检测器(Object Detectors ),用监测数据集的数据学习物体的准确位置,用分类数据集的数据来增加分类的类别量、提升健壮性。
YOLO9000就是使用联合训练算法训练出来的,他拥有9000类的分类信息,这些分类信息学习自ImageNet分类数据集,而物体位置检测则学习自COCO检测数据集。
All of our code and pre-trained models are available online at http://pjreddie.com/yolo9000/
BETTER
YOLO一代有很多缺点,作者希望改进的方向是:改善recall,提升定位的准确度,同时保持分类的准确度。
目前计算机视觉的趋势是更大更深的网络,更好的性能表现通常依赖于训练更大的网络或者把多种model综合到一起。但是YOLO v2则着力于简化网络。具体的改进见下表:
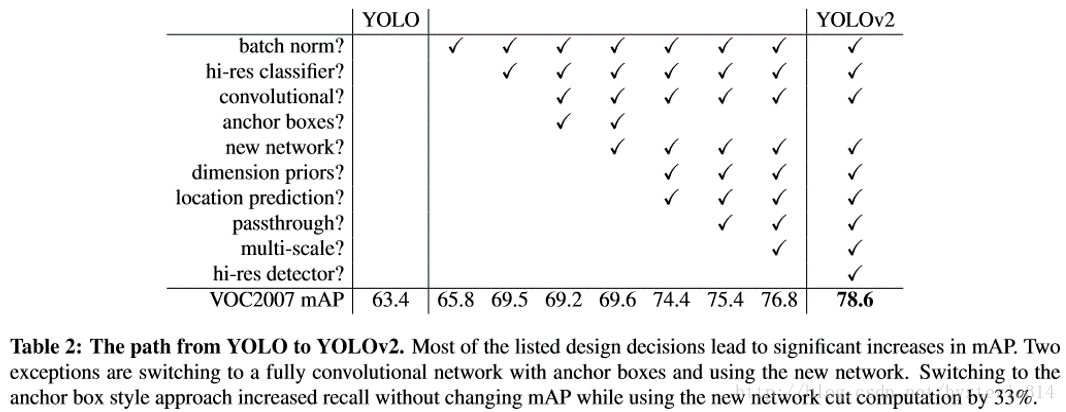
Batch Normalization
使用Batch Normalization对网络进行优化,让网络提高了收敛性,同时还消除了对其他形式的正则化(regularization)的依赖。通过对YOLO的每一个卷积层增加Batch Normalization,最终使得mAP提高了2%,同时还使model正则化。使用Batch Normalization可以从model中去掉Dropout,而不会产生过拟合。
High resolution classifier
目前业界标准的检测方法,都要先把分类器(classifier)放在ImageNet上进行预训练。从Alexnet开始,大多数的分类器都运行在小于256*256的图片上。而现在YOLO从224*224增加到了448*448,这就意味着网络需要适应新的输入分辨率。
为了适应新的分辨率,YOLO v2的分类网络以448*448的分辨率先在ImageNet上进行Fine Tune,Fine Tune10个epochs,让网络有时间调整他的滤波器(filters),好让其能更好的运行在新分辨率上,还需要调优用于检测的Resulting Network。最终通过使用高分辨率,mAP提升了4%。Convolution with anchor boxes
YOLO一代包含有全连接层,从而能直接预测Bounding Boxes的坐标值。 Faster R-CNN的方法只用卷积层与Region Proposal Network来预测Anchor Box的偏移值与置信度,而不是直接预测坐标值。作者发现通过预测偏移量而不是坐标值能够简化问题,让神经网络学习起来更容易。
所以最终YOLO去掉了全连接层,使用Anchor Boxes来预测 Bounding Boxes。作者去掉了网络中一个Pooling层,这让卷积层的输出能有更高的分辨率。收缩网络让其运行在416*416而不是448*448。由于图片中的物体都倾向于出现在图片的中心位置,特别是那种比较大的物体,所以有一个单独位于物体中心的位置用于预测这些物体。YOLO的卷积层采用32这个值来下采样图片,所以通过选择416*416用作输入尺寸最终能输出一个13*13的Feature Map。 使用Anchor Box会让精确度稍微下降,但用了它能让YOLO能预测出大于一千个框,同时recall达到88%,mAP达到69.2%。Dimension clusters
之前Anchor Box的尺寸是手动选择的,所以尺寸还有优化的余地。 为了优化,在训练集(training set)Bounding Boxes上跑了一下k-means聚类,来找到一个比较好的值。
如果我们用标准的欧式距离的k-means,尺寸大的框比小框产生更多的错误。因为我们的目的是提高IOU分数,这依赖于Box的大小,所以距离度量的使用:
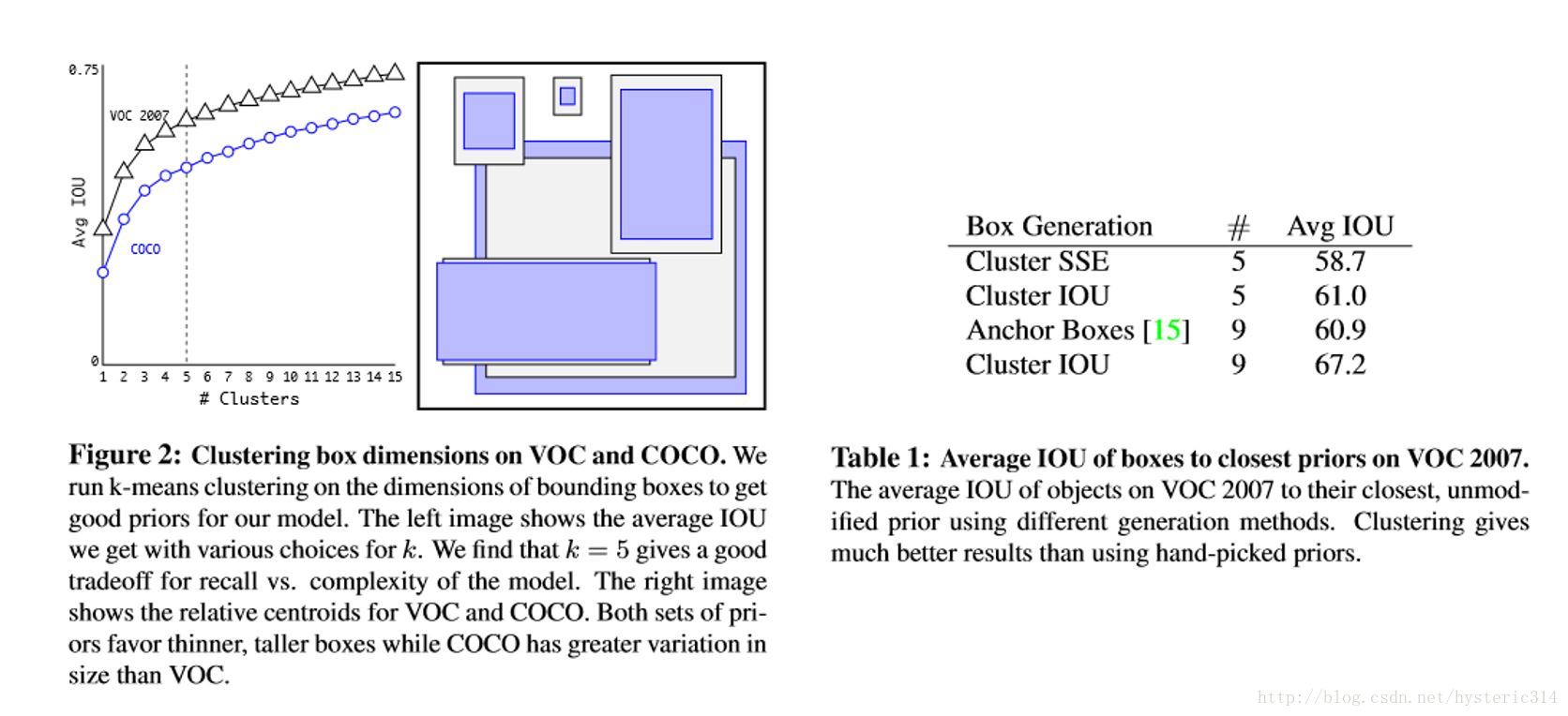
通过分析实验结果(Figure 2),左图:在model复杂性与high recall之间权衡之后,选择聚类分类数K=5。右图:是聚类的中心,大多数是高瘦的Box。
Table1是说明用K-means选择Anchor Boxes时,当Cluster IOU选择值为5时,AVG IOU的值是61,这个值要比不用聚类的方法的60.9要高。选择值为9的时候,AVG IOU更有显著提高。总之就是说明用聚类的方法是有效果的。
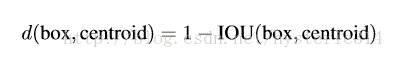
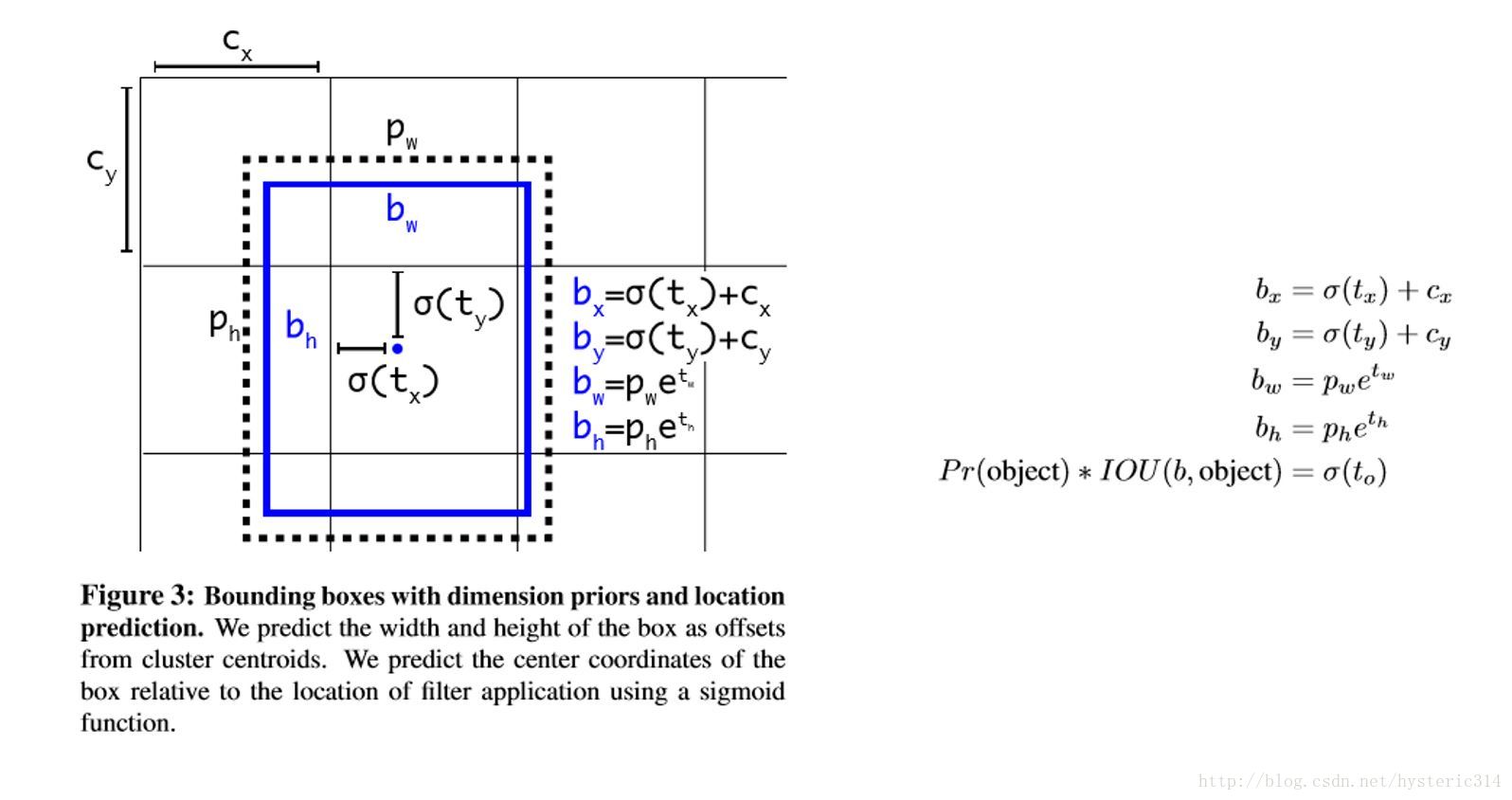
Direct location prediction
用Anchor Box的方法,会让model变得不稳定,尤其是在最开始的几次迭代的时候。大多数不稳定因素产生自预测Box的(x,y)位置的时候。按照之前YOLO的方法,网络不会预测偏移量,而是根据YOLO中的网格单元的位置来预测坐标,这就让Ground Truth的值介于0到1之间。而为了让网络的结果能落在这一范围内,网络使用一个 Logistic Activation来对于网络预测结果进行限制,让结果介于0到1之间。 网络在每一个网格单元中预测出5个Bounding Boxes,每个Bounding Boxes有五个坐标值tx,ty,tw,th,t0,他们的关系见下图(Figure3)。假设一个网格单元对于图片左上角的偏移量是cx,cy,Bounding Boxes Prior的宽度和高度是pw,ph,那么预测的结果见下图右面的公式:
因为使用了限制让数值变得参数化,也让网络更容易学习、更稳定。
Dimension clusters和Direct location prediction,improves YOLO by almost 5% over the version with anchor boxes.Fine-Grained Features
YOLO修改后的Feature Map大小为13*13,这个尺寸对检测图片中尺寸大物体来说足够了,同时使用这种细粒度的特征对定位小物体的位置可能也有好处。Faster F-CNN、SSD都使用不同尺寸的Feature Map来取得不同范围的分辨率,而YOLO采取了不同的方法,YOLO加上了一个Passthrough Layer来取得之前的某个26*26分辨率的层的特征。这个Passthrough layer能够把高分辨率特征与低分辨率特征联系在一起,联系起来的方法是把相邻的特征堆积在不同的Channel之中,这一方法类似与Resnet的Identity Mapping,从而把26*26*512变成13*13*2048。YOLO中的检测器位于扩展后(expanded )的Feature Map的上方,所以他能取得细粒度的特征信息,这提升了YOLO 1%的性能。
Multi-ScaleTraining
作者希望YOLO v2能健壮的运行于不同尺寸的图片之上,所以把这一想法用于训练model中。
区别于之前的补全图片的尺寸的方法,YOLO v2每迭代几次都会改变网络参数。每10个Batch,网络会随机地选择一个新的图片尺寸,由于使用了下采样参数是32,所以不同的尺寸大小也选择为32的倍数{320,352…..608},最小320*320,最大608*608,网络会自动改变尺寸,并继续训练的过程。
这一政策让网络在不同的输入尺寸上都能达到一个很好的预测效果,同一网络能在不同分辨率上进行检测。当输入图片尺寸比较小的时候跑的比较快,输入图片尺寸比较大的时候精度高,所以你可以在YOLO v2的速度和精度上进行权衡。
Figure4,Table 3:在voc2007上的速度与精度Further Experiments
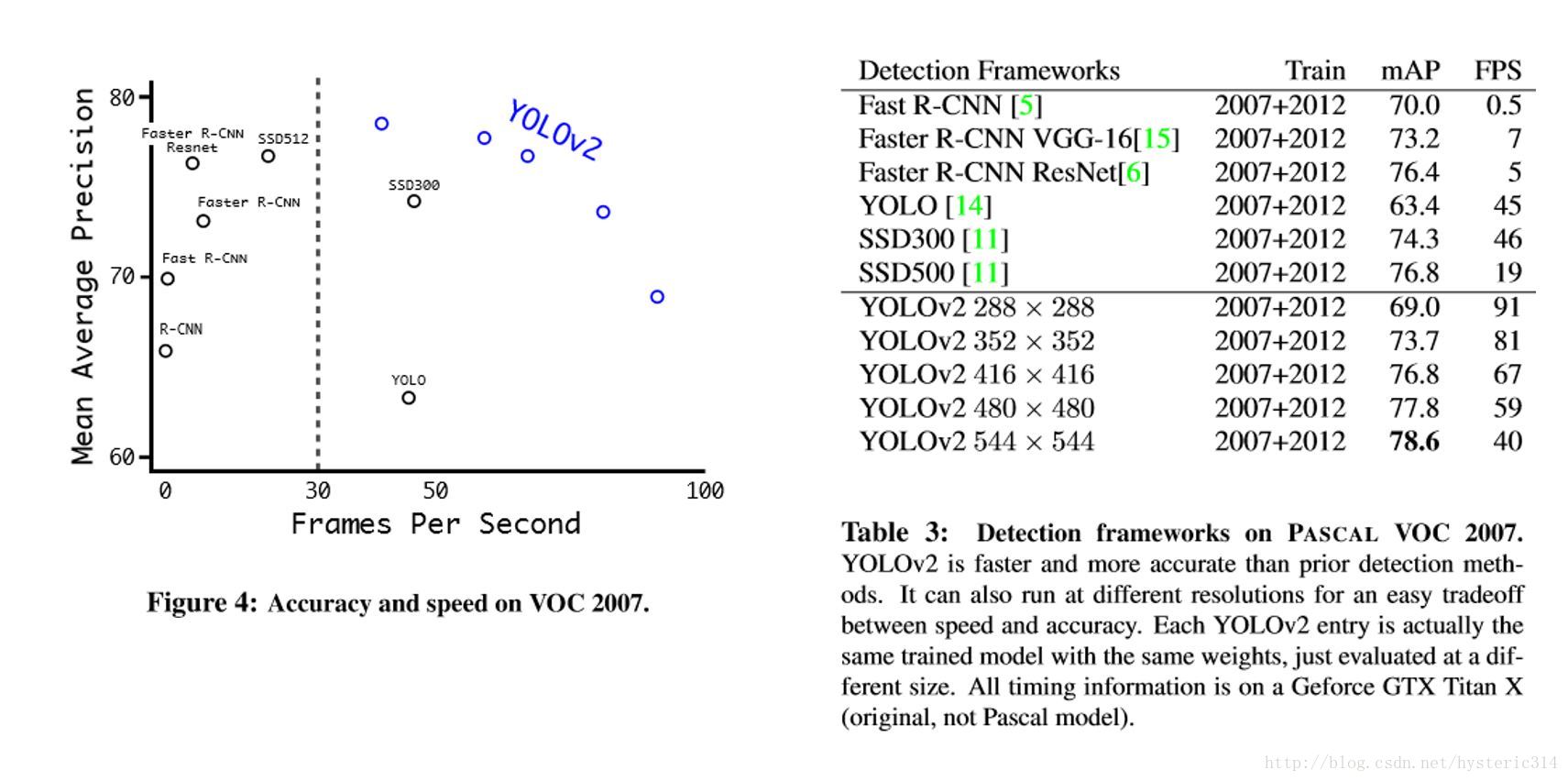
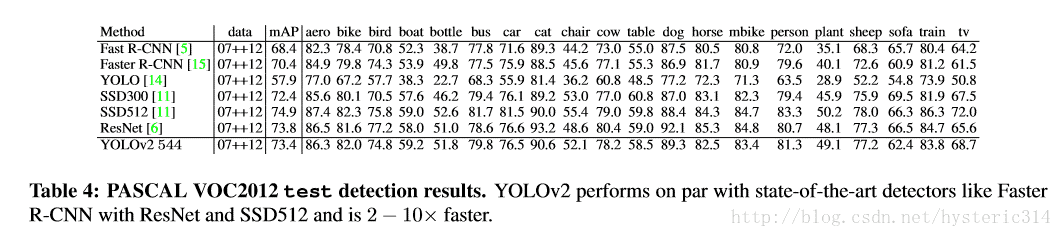
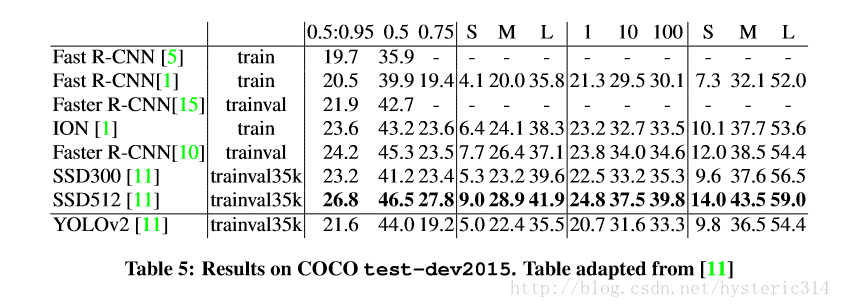
Faster
YOLO使用的是Googlelent架构,比VGG-16快,YOLO完成一次前向过程只用8.52 billion 运算,而VGG-16要30.69billion,但是YOLO精度稍低于VGG-16。
Draknet19
YOLO v2基于一个新的分类model,有点类似与VGG。YOLO v2使用3*3filter,每次Pooling之后都增加一倍Channels的数量。YOLO v2使用全局平均Pooling,使用Batch Normilazation来让训练更稳定,加速收敛,使model规范化。
最终的model–Darknet19,有19个卷积层和5个maxpooling层,处理一张图片只需要5.58 billion次运算,在ImageNet上达到72.9%top-1精确度,91.2%top-5精确度。Training for classification
网络训练在 ImageNet 1000类分类数据集,训练了160epochs,使用随机梯度下降,初始学习率为0.1, polynomial
rate decay with a power of 4, weight decay of 0.0005 and momentum of 0.9 。训练期间使用标准的数据扩大方法:随机裁剪、旋转、变换颜色(hue)、变换饱和度(saturation), 变换曝光度(exposure shifts)。
在训练时,把整个网络在更大的448*448分辨率上Fine Turnning 10个 epoches,初始学习率设置为0.001,这种网络达到达到76.5%top-1精确度,93.3%top-5精确度。Training for detection
网络去掉了最后一个卷积层,而加上了三个3*3卷积层,每个卷积层有1024个Filters,每个卷积层紧接着一个1*1卷积层, with
the number of outputs we need for detection。
对于VOC数据,网络预测出每个网格单元预测五个Bounding Boxes,每个Bounding Boxes预测5个坐标和20类,所以一共125个Filters,增加了Passthough层来获取前面层的细粒度信息,网络训练了160epoches,初始学习率0.001,dividing it by 10 at 60 and 90 epochs,a weight decay of 0.0005 and momentum of 0.9,数据扩大方法相同,对COCO与VOC数据集的训练对策相同。
Stronger
在训练的过程中,当网络遇到一个来自检测数据集的图片与标记信息,那么就把这些数据用完整的YOLO v2 loss功能反向传播这个图片。当网络遇到一个来自分类数据集的图片和分类标记信息,只用整个结构中分类部分的loss功能反向传播这个图片。
但是检测数据集只有粗粒度的标记信息,像“猫“、“ 狗”之类,而分类数据集的标签信息则更细粒度,更丰富。比如狗这一类就包括”哈士奇“”牛头梗“”金毛狗“等等。所以如果想同时在监测数据集与分类数据集上进行训练,那么就要用一种一致性的方法融合这些标签信息。
再者,用于分类的方法,大多是用softmax layer方法,softmax意味着分类的类别之间要互相独立的。而盲目地混合数据集训练,就会出现比如:检测数据集的分类信息中”狗“这一分类,在分类数据集合中,就会有的不同种类的狗”哈士奇“”牛头梗“”金毛“这些分类,这两种数据集之间的分类信息不相互独立。所以使用一种多标签的model来混合数据集,假设一个图片可以有多个分类信息,并假定分类信息必须是相互独立的规则可以被忽略。
Hierarchical classification
WordNet的结构是一个直接图表(directed graph),而不是树型结构。因为语言是复杂的,狗这个词既属于‘犬科’又属于‘家畜’两类,而‘犬科’和‘家畜’两类在wordnet中则是同义词,所以不能用树形结构。
作者希望根据ImageNet中包含的概念来建立一个分层树,为了建立这个分层树,首先检查ImagenNet中出现的名词,再在WordNet中找到这些名词,再找到这些名词到达他们根节点的路径(在这里设为所有的根节点为实体对象(physical object))。在WordNet中,大多数同义词只有一个路径,所以首先把这条路径中的词全部都加到分层树中。接着迭代地检查剩下的名词,并尽可能少的把他们添加到分层树上,添加的原则是取最短路径加入到树中。
为了计算某一结点的绝对概率,只需要对这一结点到根节点的整条路径的所有概率进行相乘。所以比如你想知道一个图片是否是Norfolk terrier的概率,则进行如下计算:
为了验证这一个方法,在WordTree上训练Darknet19的model,使用1000类的ImageNet进行训练,为了建立WordtTree 1K,把所有中间词汇加入到WordTree上,把标签空间从1000扩大到了1369。在训练过程中,如果有一个图片的标签是”Norfolk terrier“,那么这个图片还会获得”狗“(dog)以及“哺乳动物”(mammal)等标签。总之现在一张图片是多标记的,标记之间不需要相互独立。
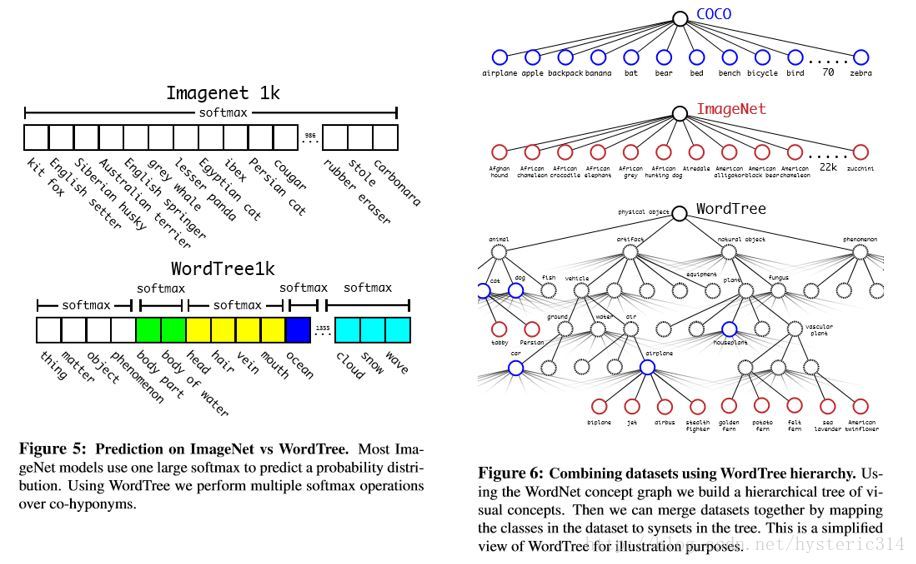
如Figure5所示,之前的ImageNet分类是使用一个大softmax进行分类。而现在,WordTree只需要对同一概念下的同义词进行softmax分类。
使用相同的训练参数,这种分层结构的Darknet19达到71.9%top-1精度和90.4%top-5精确度,精度只有微小的下降。
这种方法的好处:在对未知或者新的物体进行分类时,性能降低的很优雅(gracefully)。比如看到一个狗的照片,但不知道是哪种种类的狗,那么就高置信度(confidence)预测是”狗“,而其他狗的种类的同义词如”哈士奇“”牛头梗“”金毛“等这些则低置信度。
Datasets combination with wordtree
用WordTree 把数据集合中的类别映射到分层树中的同义词上,例如上图Figure 6,WordTree混合ImageNet与COCO。
Joint classification and detection
作者的目的是:训练一个Extremely Large Scale检测器。所以训练的时候使用WordTree混合了COCO检测数据集与ImageNet中的Top9000类,混合后的数据集对应的WordTree有9418个类。另一方面,由于ImageNet数据集太大了,作者为了平衡一下两个数据集之间的数据量,通过过采样(oversampling)COCO数据集中的数据,使COCO数据集与ImageNet数据集之间的数据量比例达到1:4。
YOLO9000的训练基于YOLO v2的构架,但是使用3priors而不是5来限制输出的大小。当网络遇到检测数据集中的图片时则正常地反方向传播,当遇到分类数据集图片的时候,只使用分类的loss功能进行反向传播。同时作者假设IOU最少为 .3。最后根据这些假设进行反向传播。使用联合训练法,YOLO9000使用COCO检测数据集学习检测图片中的物体的位置,使用ImageNet分类数据集学习如何从大量的类别中进行分类。
为了评估这一方法,使用ImageNet Detection Task对训练结果进行评估。
评估结果:
YOLO9000取得19.7mAP。
在未学习过的156个分类数据上进行测试,mAP达到16.0。
YOLO9000的mAP比DPM高,而且YOLO有更多先进的特征,YOLO9000是用部分监督的方式在不同训练集上进行训练,同时还能检测9000个物体类别,并保证实时运行。

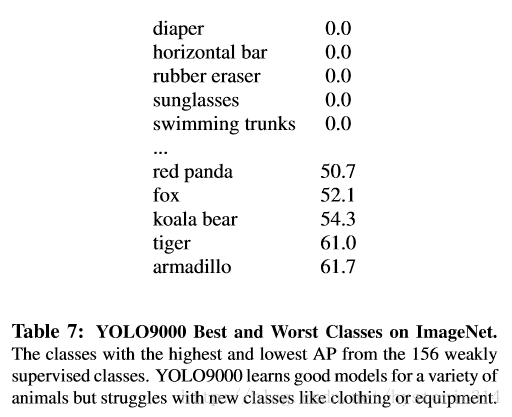
虽然YOLO9000对动物的识别性能很好,但是对类别为”sungalsses“或者”swimming trunks“这些衣服或者装备的类别,它的识别性能不是很好,见table 7。这跟数据集的数据组成有很大关系。
总结
YOLO v2 代表着目前最先进物体检测的水平,在多种监测数据集中都要快过其他检测系统,并可以在速度与精确度上进行权衡。
YOLO 9000 的网络结构允许实时地检测超过9000种物体分类,这归功于它能同时优化检测与分类功能。使用WordTree来混合来自不同的资源的训练数据,并使用联合优化技术同时在ImageNet和COCO数据集上进行训练,YOLO9000进一步缩小了监测数据集与识别数据集之间的大小代沟。
文章还提出了WordTree,数据集混合训练,多尺寸训练等全新的训练方法。
要说的
首先这文章属于学习笔记,里面一定会有错误的内容,仅供参考,一切以原文为准。
如果你发现文章中的错误,欢迎留言指正,多谢。
准备考博了,还要中期,最近事情比较多,不过以后应该还会更新使用YOLO v2 训练其他数据的方法。


















 836
836

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









