










HTTPS协议原理分析
HTTPS协议需要解决的问题
HTTPS作为安全协议而诞生,那么就不得不面对以下两大安全问题:
-
身份验证
确保通信双方身份的真实性。直白一些,A希望与B通信,A如何确认B的身份不是由C伪造的。
(由C伪造B的身份与A通信,称为中间人攻击)
-
通信加密
通信的机密性、完整性依赖于算法与密钥,通信双方是如何选择算法与密钥的。
能同时解决以上两个问题,就能确保真实有效的通信双方采取有效的算法与密钥进行通信,便完成了协议安全的初衷。
在介绍HTTPS协议如何解决两大安全问题前,我们首先了解几个概念。
-
数字证书
数字证书是互联网通信中标识双方身份信息的数字文件,由CA签发。
-
CA
CA(certification authority)是数字证书的签发机构。作为权威机构,其审核申请者身份后签发数字证书,这样我们只需要校验数字证书即可确定对方的真实身份。
-
HTTPS协议、SSL协议、TLS协议、握手协议的关系
HTTPS是Hypertext Transfer Protocol over Secure Socket Layer的缩写,即HTTP over SSL,可理解为基于SSL的HTTP协议。HTTPS协议安全是由SSL协议(目前常用的,本文基于TLS 1.2进行分析)实现的。
SSL协议是一种记录协议,扩展性良好,可以很方便的添加子协议,而握手协议便是SSL协议的一个子协议。
TLS协议是SSL协议的后续版本,本文中涉及的SSL协议默认是TLS协议1.2版本。
HTTPS协议的安全性由SSL协议实现,当前使用的TLS协议1.2版本包含了四个核心子协议:握手协议、密钥配置切换协议、应用数据协议及报警协议。
解决身份验证与通信加密的核心,便是握手协议,接下来着重介绍握手协议。
握手协议
握手协议的作用便是通信双方进行身份确认、协商安全连接各参数(加密算法、密钥等),确保双方身份真实并且协商的算法与密钥能够保证通信安全。
对握手协议的介绍限于客户端对服务端的身份验证,单向身份验证也是目前互联网公司最常见的认证方式。
首先我们看一下协议交互,如图1所示:

图1 握手协议
接下来以Wireshark抓取接口的握手协议过程为例,针对每条协议消息分析。
ClientHello消息
ClientHello消息的作用是,将客户端可用于建立加密通道的参数集合,一次性发送给服务端。
消息内容包括:期望协议版本(TLS 1.2)、可供采用的密码套件(Cipher Suites)、客户端随机数(Random)及扩展字段内容(Extension)等信息,如图2所示。
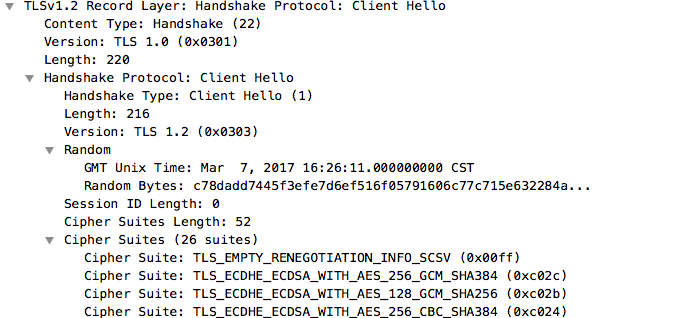
图2 ClientHello
ServerHello消息
ServerHello消息的作用是,在ClientHello参数集合中选择适合的参数,并将服务端用于建立加密通道的参数发送给客户端。
消息内容包括:采取的协议版本(TLS 1.2)、采用的密码套件(Cipher Suite)、服务端随机数(Random)、用于恢复会话的会话ID(Session ID)及扩展字段等信息,如图3所示。
自此客户端与服务端的协议版本、密码套件已经协商完毕。
这里服务端下发的会话ID可用于后续恢复会话。若客户端在ClientHello中携带了会话ID,并且服务端认可,则双方直接通过原主密钥生成一套新的密钥即可继续通信。将两个网络往返降低为一个网络往返,提高通道建立的效率。
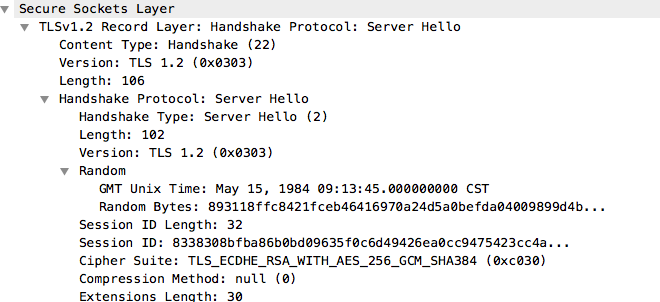
图3 ServerHello
Certificate消息
Certificate消息的作用是,将服务端证书的详细信息发送给客户端,供客户端进行服务端身份校验。
消息内容:服务端下发的证书链,如图4所示。
服务端为了保证下发的证书能够被客户端正确识别,就需要将签发此证书的CA证书一同下发,构成证书链,保证客户端可以根据证书链的信息在系统配置中找到根证书,并通过根证书的公钥逐层向下验证证书的合法性。
如图所示,五八服务器下发了两个证书:自己的证书与签发CA的证书。通过签发CA的证书信息,能够直接找到根证书。
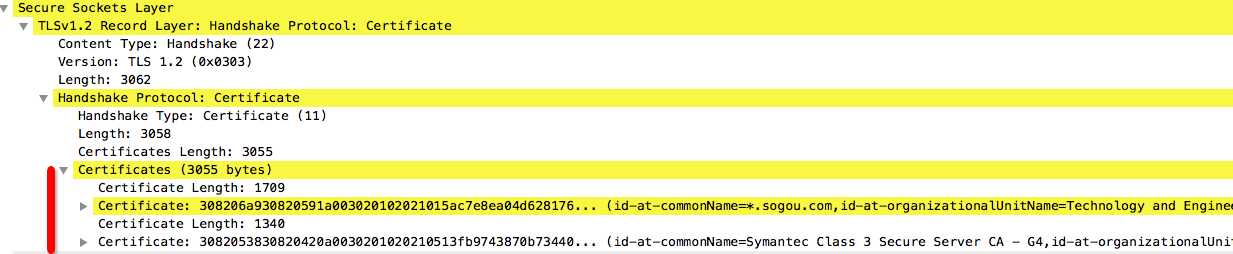
图4 Certificate
客户端本地校验服务端证书,若校验通过,则客户端对服务端的身份验证便完成了。
Certificate这个阶段解决了两端的身份验证问题。借助CA的力量,通过CA签发证书,将身份验证的工作交给了CA处理。
只要是我们认可的CA,签发的证书我们均认可证书持有者的身份。由于CA的介入,解决了中间人攻击的问题,因为中间人并没有服务端的证书可供客户端验证。
ServerKeyExchange消息(可能不发送)
ServerKeyExchange消息的作用是,将需要服务端提供的密钥交换的额外参数,传给客户端。有的算法不需要额外参数,则ServerKeyExchange消息可不发送。
消息内容:用于密钥交换的额外参数,如图5所示。
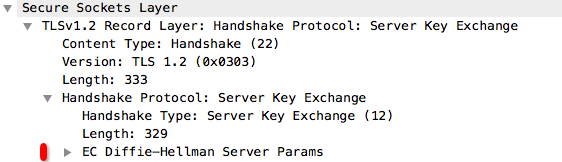
图5 ServerKeyExchange
如图5,服务端下发了“EC Diffile-Hellman”密钥交换算法所需要的参数。
ServerHelloDone消息
ServerHelloDone消息的作用是,通知客户端ServerHello阶段的数据均已发送完毕,等待客户端下一步消息。
ClientKeyExchange消息
ClientKeyExchange消息的作用是,将客户端需要为密钥交换提供的数据发送给服务端。
当我们选用RSA密钥交换算法时,此消息的内容便是通过证书公钥加密的用于生成主密钥的预主密钥。
如图6所示,由于选用的密钥交换算法是“EC Diffie-Hellman”,所以ClientKeyExchange消息发送的是”EC Diffie-Hellman”算法需要的客户端参数。
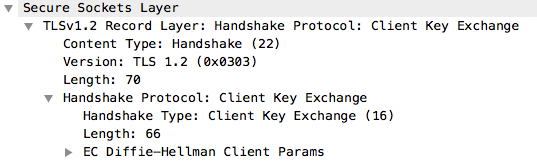
图6 ClientKeyExchange
当发送了ClientKeyExchange后,两端均具有了生成主密钥的完整密钥数据与随机数,两端分别根据所选算法计算主密钥即可。
至此,ClientKeyExchange发送后,两端均可生成主密钥,密钥交换问题便解决了。
有的读者可能对随机数的采用有些疑惑,笔者觉得随机数的加入是为了提高密钥的随机性。
由于客户端直接生成的密钥很有可能不够随机,而通过预主密钥加上两端提供的两个随机数做种子,创建的主密钥可以保证更加贴近真实随机的密钥。
ChangeCipherSpec消息
经过以上六条消息,我们已经解决了身份认证问题、密码套件选取问题、密钥交换问题。双方也已经通过主密钥生成了实际使用的六个加解密密钥。
ChangeCipherSpec消息的作用,便是声明后续消息均采用密钥加密。在此消息后,我们在WireShark上便看不到明文信息了。
Finished消息
Finished消息的作用,是对握手阶段所有消息计算摘要,并发送给对方校验,避免通信过程中被中间人所篡改。
HTTPS协议总结
自此,HTTPS如何保证通信安全,通过握手协议的介绍,我们已经有所了解。
但是,在全面使用HTTPS前,我们还需要考虑一个众所周知的问题——HTTPS性能。
相对HTTP协议来说,HTTPS协议建立数据通道的更加耗时,若直接部署到App中,势必降低数据传递的效率,间接影响用户体验。
接下来,介绍HTTPS性能救星——HTTP2协议。
协议新宠-HTTP2
协议介绍
随着互联网的快速发展,HTTP1.x协议得到了迅猛发展,但当App一个页面包含了数十个请求时,HTTP1.x协议的局限性便暴露了出来:
- 每个请求与响应需要单独建立链路进行请求(Connection字段能够解决部分问题),浪费资源。
- 每个请求与响应都需要添加完整的头信息,应用数据传输效率较低。
- 默认没有进行加密,数据在传输过程中容易被监听与篡改。
HTTP2正是为了解决HTTP1.x暴露出来的问题而诞生的。
说到HTTP2不得不提spdy。
由于HTTP1.x暴露出来的问题,Google设计了全新的名为spdy的新协议。spdy在五层协议栈的TCP层与HTTP层引入了一个新的逻辑层以提高效率。spdy是一个中间层,对TCP层与HTTP层有很好的兼容,不需要修改HTTP层即可改善应用数据传输速度。
spdy通过多路复用技术,使客户端与服务器只需要保持一条链接即可并发多次数据交互,提高了通信效率。
而HTTP2便士基于spdy的思路开发的。
通过流与帧概念的引入,继承了spdy的多路复用,并增加了一些实用特性。
HTTP2有什么特性呢?HTTP2的特性不仅解决了上述已暴露的问题,还有一些功能使HTTP协议更加好用。
- 多路复用
- 压缩头信息
- 对请求划分优先级
- 支持服务端Push消息到客户端
此外,HTTP2目前在实际使用中,只用于HTTPS协议场景下,通过握手阶段ClientHello与ServerHello的extension字段协商而来,所以目前HTTP2的使用场景,都是默认安全加密的。
下面介绍HTTP2协议协商以及多路复用与压缩头信息两大特性,实现部分采用okhttp源码(基于parent-3.4.2)进行分析与介绍。
okhttp是目前使用最广泛的支持HTTP2的Android端开源网络库,以okhttp为例介绍HTTP2特性也可方便读者提前了解okhttp,方便后续接入okhttp。
协议协商
HTTP2协议的协商是在握手阶段进行的。
协商的方式是通过握手协议extension扩展字段进行扩展,新增Application Layer Protocol Negotiation字段进行协商。
在握手协议的ClientHello阶段,客户端将所支持的协议列表填入Application Layer Protocol Negotiation字段,供服务端进行挑选。如图7所示:

图7 ALPN1
服务端收到ClientHello消息后,在客户端所支持的协议列表中选择适当协议作为后续应用层协议。如图8所示:
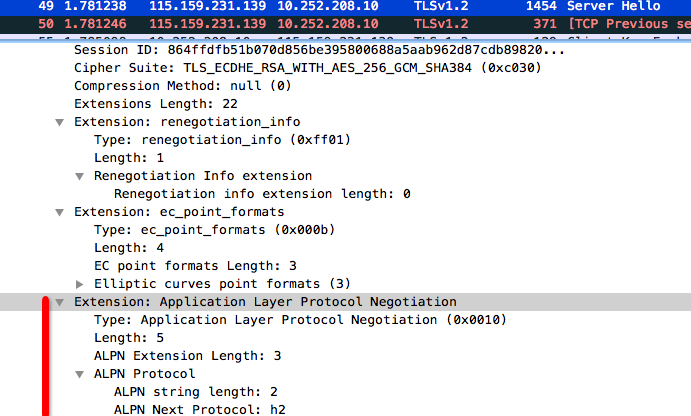
图8 ALPN2
这样,两端便完成了HTTP2协议的协商。
在HTTP2未出现时,spdy也是通过扩展字段,扩展出next_protocol_negotiation字段,以NPN协议进行spdy的协商。不过由于NPN协议协商过于复杂,对https协议侵入性较强,在出现ALPN协商协议后,便逐渐被淘汰了。所以,本文协议协商并为对NPN协议协商做介绍。
协议特性之多路复用
http2为了优化http1.x对TCP性能的浪费,提出了多路复用的概念。
多路复用的含义
在HTTP2中,同一域名下的请求,可通过同一条TCP链路进行传输,使多个请求不必单独建立链路,节省建立链路的开销。
为了达到这个目的,HTTP2提出了流与帧的概念,流代表请求与响应,而请求与响应具体的数据则包装为帧,对链路中传输的数据通过流ID与帧类型进行区分处理。图9便是多路复用的抽象图,每个块代表一帧,而相同颜色的块则代表是同一个流。

图9 http2_stream
那么HTTP2的多路复用是如何实现的呢?
由于网络请求的场景很多,我们选择其中一个路径来介绍:
- 客户端与服务端在某个域名的TCP通道已建立
- 新创建的客户端请求通过已连接的TCP通道进行请求发送与响应处理
多路复用实现
默认我们已经添加各参数创建了Request对象r,并通过Request对象创建了Call对象c。并在独立线程中,调用c.execute()方法,进行同步请求操作。
okhttp调用execute方法后,实际上是由一系列的interceptor来负责执行的。
interceptor根据添加顺序依此执行,其中我们关注的是RetryAndFollowUpInterceptor、ConnectInterceptor0、CallServerInterceptor。
1.在RetryAndFollowUpInterceptor中,okhttp为我们创建了一个StreamAllocation对象,StreamAllocation中含有基于url创建的Address对象。
Address类的url字段与Request类的url字段不同,Address类的url字段不包括path与query字段,只含有scheme与authority部分,这点在进行Connection复用的equal操作时起了很大作用。
2.在ConnectInterceptor中,StreamAllocation对象的Address与连接池中每个Connection对象的Address依次进行匹配,匹配成功并满足一些条件的Connection便可复用。基于匹配出的Connection创建Http2xStream,用于后续读写操作。
与连接池中Address匹配主要通过Address的url,url由于只含有scheme与authority所以可用于域名的匹配,这便是okhttp基于域名层面多路复用的基础。
实际上真正进行流读写操作的是FramedConnection与FramedStream,Connection与Http2xStream是抽象于具体操作的类,以方便上层使用。
3.在CallServerInterceptor中,Http2xStream创建FramedStream用于Request发送,并将FramedStream与对应的StreamID绑定缓存下来,以便Response到来时,能够根据StreamID索引到对应的FramedSteam进行后续操作。
在FramedStream发送完Request后,执行readResponseHeaders方法时进行调用了wait,将当前线程挂起。
并在FramedConnection读线程收到StreamID消息时,在缓存中查询FramedStream并将对应线程唤醒进行Response解码。
归纳下okhttp的多路复用实现思路:
- 通过请求的Address与连接池中现有连接Address依次匹配,选出可用的Connection。
- 通过Http2xStream创建的FramedStream在发送了请求后,将FramedStream对象与StreamID的映射关系缓存到FramedConnection中。
- 收到消息后,FramedConnection解析帧信息,在Map中通过解析的StreamID选出缓存的FramedStream,并唤醒FramedStream进行Response的处理。
在笔者看来,HTTP2便是一个良好兼容http协议格式的自定义协议,通过Stream将数据分发到各请求,通过Frame将请求数据详细细分。
协议特性之压缩头信息
HTTP2为了解决HTTP1.x中头信息过大导致效率低下的问题,提出的解决方案便是压缩头部信息。具体的压缩方式,则引入了HPACK。
HPACK压缩算法是专门为HTTP2头部压缩服务的。为了达到压缩头部信息的目的,HPACK将头部字段缓存为索引,通过索引ID代表头部字段。客户端与服务端维护索引表,通信过程中尽可能采用索引进行通信,收到索引后查询索引表,才能解析出真正的头部信息。
HPACK索引表划分为动态索引表与静态索引表,动态索引表是HTTP2协议通信过程中两端动态维护的索引表,而静态索引表是硬编码进协议中的索引表。
作为分析HPACK压缩头信息的基础,需要先介绍HPACK对索引以及头部字符串的表示方式。
索引
索引以整型数字表示,由于HPACK需要考虑压缩与编解码问题,所以整型数字结构定义如图10所示:

图10 int_strut
-
类别标识
通过类别标识进行HPACK类别分类,指导后续编解码操作,常见的有1,01,01000000等八个类别。
-
首字节低位整型
首字节排除类别标识的剩余位,用于表示低位整型。若数值大于剩余位所能表示的容量,则需要后续字节表示高位整型。
-
结束标识
表示此字节是否为整型解析终止字节。
-
高位整型
字节余下7bit,用于填充整型高位。
“结束标识+高位整型”字节可能有0个、也有可能有多个,依据数据大小而定。
譬如,若想表示类别为1,索引为2,则使用10000010即可,不需要额外字节增加高位整型。
头部字符串
头部字符串需要显式声明长度,所以数据首字节由“类型标识+数据长度”组成。如图11所示:

图11 string_strut
-
类型标识
是否选用哈夫曼编码,1为选用,0为不选用,okhttp默认不选用哈夫曼编码。
-
数据长度
标识数据长度,采用上面提到的整型表示法表示。
-
数据内容
二进制数据。
解码实例
下面综合okhttp源码分析HPACK解码头部字段过程。
对编码部分感兴趣的读者,可以查阅RFC 7541或直接分析OkHttp源码。
当我们需要解码头部字段时,首先解析头部字段首字节(HPACK头部字段首字节分为8个类别,摘选其中3个类别说明),首字节用于指导当前头部字段的解析规则:
-
1xxxxxxx
类别标识为1,代表收到一条K、V均为索引的头部字段。
K、V值:通过解析HPACK整型获取KV对的索引值,并根据索引值映射对应的头部原字段即可,压缩效率最高。
-
01xxxxxx
类别标识为01,代表收到一条K为索引、V为原字段,且需要加入动态索引表的头部字段。
K值:通过解析HPACK整型获取K值索引值,并通过索引值映射对应的头部原字段。
V值:通过解析HPACK字符串获取V值原字段。
获取K、V值后还需插入动态索引表中。
-
01000000
01000000代表收到一条K、V均为原字段,且需要加入动态索引表的头部字段。
K、V值:通过解析HPACK字符串获取K、V原字段,并插入动态索引表中。
还有不加入动态索引表、调整索引表大小等类别,这里就不展开了,感兴趣的可以看okhttp源码实现。
okhttp解析头信息的核心方法实现如下:
void readHeaders() throws IOException {
while (!source.exhausted()) {
int b = source.readByte() & 0xff;
if (b == 0x80) { // 10000000
//类别标识为1,但索引为0
throw new IOException("index == 0");
} else if ((b & 0x80) == 0x80) { // 1NNNNNNN
//类别为1,通过readIndexedHeader解析整型index。
int index = readInt(b, PREFIX_7_BITS);
//通过index获取完整头部字段
readIndexedHeader(index - 1);
} else if (b == 0x40) { // 01000000
//01000000代表KV均为原字段,解析字符串依次获取K值、V值,并插入动态表中
readLiteralHeaderWithIncrementalIndexingNewName();
} else if ((b & 0x40) == 0x40) { // 01NNNNNN
//01xxxxxx代表K值为索引,V值为原字符串,依次解析整型index与字符串,并插入动态表中
int index = readInt(b, PREFIX_6_BITS);
readLiteralHeaderWithIncrementalIndexingIndexedName(index - 1);
} else if ((b & 0x20) == 0x20) { // 001NNNNN
//类别为001,含义是更新动态列表容量
maxDynamicTableByteCount = readInt(b, PREFIX_5_BITS);
if (maxDynamicTableByteCount < 0
|| maxDynamicTableByteCount > headerTableSizeSetting) {
throw new IOException("Invalid dynamic table size update " + maxDynamicTableByteCount);
}
adjustDynamicTableByteCount();
} else if (b == 0x10 || b == 0) { // 000?0000 - Ignore never indexed bit.
//这个类别代表KV均为原字符串,依次解析字符串,并不对解析后的KV值插入动态表。
readLiteralHeaderWithoutIndexingNewName();
} else { // 000?NNNN - Ignore never indexed bit.
//与上一类别类似,但K值为索引,V值为原字符串
int index = readInt(b, PREFIX_4_BITS);
readLiteralHeaderWithoutIndexingIndexedName(index - 1);
}
}
}压缩效果
K值为“accept-encoding”、V值为“gzip, deflate”的头部字段在HTTP2中可通过索引值15代替,从而达到头部字段压缩的效果。
“accept-charset”头部字段则通过14代表头部K值,而Value值根据HPACK规则编码写入流中。
通过HPACK,一个头部字段变化较少的App,每个头部字段将会缩减至4字节以内,压缩效果非常明显。














 3192
3192











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









