









 本文详细介绍了HBase从0.20版本到当前版本的存储引擎演变过程,包括MapFile、HFile V1、HFile V2及HFile V3的不同特点与改进,帮助读者理解HBase如何实现随机读写及低延迟访问。
本文详细介绍了HBase从0.20版本到当前版本的存储引擎演变过程,包括MapFile、HFile V1、HFile V2及HFile V3的不同特点与改进,帮助读者理解HBase如何实现随机读写及低延迟访问。
Apache HBase是Hadoop的分布式开源的存储管理工具,非常适合随机实时的io操作。
我们知道,Hadoop的Sequence File是一个顺序读写,批量处理的系统。但是为什么HBase能做到随机的,实时的io操作呢?
Hadoop底层使用Sequence File文件格式存储,Sequence File允许以追加的方式增加k-v(Key-Value)数据,根据hdfs的append-only的特性,Sequence File不允许修改或删除一个指定的数据。只有append操作是被允许的,而且你想要查找某个key,你只能遍历文件,知道找到这个key为止。
所以,在这个文件格式至上搭建的HBase系统,是如何搭建随机读写,低访问延迟的呢?
HBase 0.20之前-MapFile
上文中提到了MapFile,是一个以Sequence File为基础的文件格式。MapFile实际上是由两个Sequence File组成的,/data存储了数据,/index存储了索引。
MapFile提供了一个按顺序存储的方式,每当N(N是可配置的)条记录写入后,会将文件偏移地址写入index文件;这就实现了快速查找,相比直接遍历Sequence File,你可以直接遍历index文件,index文件存储了更少的文件句柄,一旦找到了文件块所在的位置,可以直接跳到该文件块查找;因此查找速度非常快。
但是还有另外两个问题:
1. 如何删除或更新一个k-v记录;
2. 当插入数据不是有序的,如何使用MapFile
MapFile文件格式如下:

HBase的key包括:行键,列族,column qualifier,时间戳,属性。
为了解决删除的问题,使用key中的type标记该记录是否被删除。
解决更新的问题,实际上是获取时间戳更晚的记录,正确的数据总会更接近文件的末尾。为了解决无序数据的问题,hbase将插入的数据暂存在内存中,直到一个阈值到达,hbase会将内存中的数据存储到MapFile中。hbase在内存中使用sorted ConcurrentSkipListMap数据结构存储数据,每次到达阈值(hbase.hregion.memstore.flush.size)或到达内存上限(hbase.regionserver.global.memstore.upperLimit),都会将内存中的数据向一个新的mapFile写入。由于每次flush操作都会写入一个新的MapFile,这就意味着查找时,会横跨多个文件,这也会耗费更多的资源和时间。
为了避免在查找get和scan扫描时横跨过多的文件,hbase中有一个线程来执行文件合并的相关操作。当线程发现文件数量达到阈值(hbase.hstore.compaction.max)后,会有一个compaction进程来执行文件合并,将小的文件合并到一个大文件中。
hbase中有两种合并模式,minor和major。minor会合并两个或多个较小的文件到一个大文件中。另外的major会合并所有的文件到一个文件中,并且执行一些清理,被删除的数据将不会被写入新的文件,并且重复的数据会被清除,只留下最新的有效数据。0.20以下版本的hbase使用上述的文件存储方式,到0.20以后,HFile V1被引入替代了MapFile。
HBase 0.20到0.92之前-HFile V1
从 HBase 0.20开始,HBase引入了HFile V1文件格式。HFile V1的具体格式如下:
KeyValue的具体格式如下:

上图中,keytype有四种类型,分别是Put、Delete、 DeleteColumn和DeleteFamily。RowLength为2个字节,Row长度不固定,ColumnFamilyLength为2个字节,ColumnFamily长度不固定,ColumnQualifier长度不固定,TimeStamp为4个字节,KeyType为1个字节。之所以不记录ColumnQualifier的长度是因为可以通过其他字段计算得到。
HFile文件的长度可变,唯一固定的是File Info和Trailer。Trailer存储指向其他块的指针,它在持久化数据到文件结束时写入的,写入后,该文件就会变成不可变的数据存储文件。数据块(data blocks)中存储key-values,可以看做是一个MapFile。当block关闭操作时,第一个key会被写入index中,index文件在hfile关闭操作时写入。Hfile V1还增加两个额外的元数据类型,Meta和FileInfo。这两个数据也是在hfile的close时被写入的。
块大小是由HColumnDescriptor设置的。该配置可以在建表时自己指定。默认是64KB。如果程序主要涉及顺序访问,则设置较大的块大小更合适。如果程序主要涉及随机访问,则设置较小的块大小更合适。不过较小的块也导致更多的块索引,有可能创建过程变得更慢(必须在每个块结束的时候刷写压缩流,会导致一个FS I/O刷写)。块大小一般设置在8KB~1MB比较合适。
HBase的Regionserver的存储文件中,使用Meta Block存储了BloomFilter,使用FileInfo存储了最大的SequenceId,Major compaction key和时间跨度信息。这些信息在旧文件或非常新的文件中判断key是否存在非常有用。
BloomFilter是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合。
HBase 0.92到0.98之前-HFile V2
在hbase 0.92版本中,为了改进在大数据存储下的效率,HFile做了改变。HFile V1的主要问题是,你需要加载(load)所有的单片索引和BloomFilter到内存中。为了解决这个问题,v2引入了多级索引和分块BloomFilter。HFile v2改进了速度,内存和缓存利用率。
HFile V2的具体格式如下:
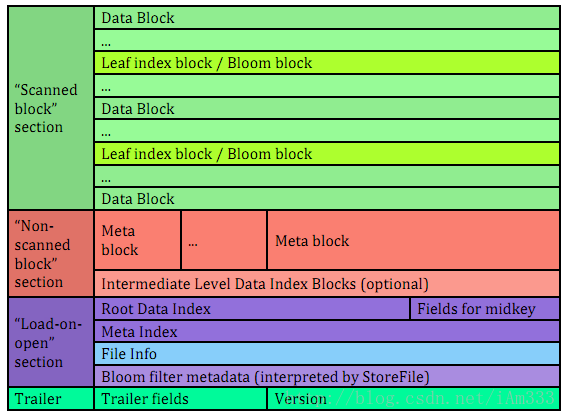
上图中,主要包括四个部分:Scanned Block(数据block)、Non-Scanned block(元数据block)、Load-on-open(在hbase运行时,HFile需要加载到内存中的索引、bloom filter元数据和文件信息)以及trailer(文件尾)。
V1的时候,在数据块索引很大时,很难全部load到内存。假设每个数据块使用默认大小64KB,每个索引项64Byte,这样如果每台及其上存放了60TB的数据,那索引数据就得有60G,所以内存的占用还是很高的。然而,将这些索引以树状结构进行组织,只让顶层索引常驻内存,其他索引按需读取并通过LRU cache进行缓存,这样就不用全部加载到内存了。
v2的最主要特性是内联块。主要思想是拆分了索引和BloomFilter到每个数据块中,来解决整个文件的索引和BloomFilter都load到内存中的问题。
因为索引被拆分到每个数据块中,这就意味着每个数据块都有自己的索引(leaf-index)。每个数据块中的最后一个key被当做节点组建了类似b+树的多级索引结构。

数据块的头信息中的Block Magic被Block Type替换,Block Type包含描述Block数据的一些信息,包括叶子索引,Bloom,元数据,根索引等。
具体实现来看,在写入HFile时,在内存中会存放当前的inline block index,当inline block index大小达到一定阈值(比如128KB)时就直接flush到磁盘,而不再是最后做一次flush,这样就不需要在内存中一直保持所有的索引数据。当所有的inline block index生成之后,HFile writer会生成更上一级的block index,它里面的内容就是这些inline block index的offset,依次递归,逐步生成更上层的block index,上层的包含的就是下层的offset,直到最顶层大小小于阈值时为止。所以整个过程就是自底向上的通过下层index block逐步构建出上层index block。
其他三个字段(compressed/uncompressed size and offset prev block)也被添加用于前后的快速查找。
在HFile V2中根据key查找数据的过程如下:
1)先在内存中对HFile的root索引进行二分查找,如果支持多级索引,则定位到leaf index,如果是单级索引,则定位到数据块;
2)如果支持多级索引,则会从cache/hdfs中读取leaf index,然后再进行二分查找,找到对应的数据块;
3)从cache/hdfs中读取数据块;
4)在数据块中遍历查找对应的数据。
HBase 0.98到目前-HFile V3HBase 0.98开始增加了对cell tags的支持,所以其HFile结构也发生了改变。HFile V3的格式只是在V2格式后增加了标签部分。其他保持不变,所以对V2保持了兼容性。用户可以从V2直接切换到V3。
转载请注明出处:http://blog.csdn.net/iAm333

















 1025
1025

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









