







优化维度设计
经过良好调校的维度设计方案是高性能Analysis Services最关键的因素之一。有两种主要的优化维度设计方案:
定义属性关系
通常情况下,Analysis Services维度数据源是关系型数据仓库中的维度表,维度表包含主键、属性和关联到其他表的外键。
表 1 简单的产品维度表包含的列
| 维度表列 | 列类型 | 与主键的关系 | 与其他列的关系 |
| Product Key | Primary Key | Primary Key | --- |
| Product SKU | Attribute | 1:1 | --- |
| Description | Attribute | 1:1 | --- |
| Color | Attribute | Many:1 | --- |
| Size | Attribute | Many:1 | Many: 1 to Size Range |
| Size Range | Attribute | Many:1 | |
| Subcategory | Attribute | Many:1 | Many: 1 to Category |
| Category | Attribute | Many:1 |
表1显示一种简单的产品维度表。在这个简单的例子中,产品维度表有一个主键列,其他列是属性。从关系的观点看,所有属性与主键都是多对一,或一对一的关系。属性间也存在关系,例如Size和Size Range是多对一的关系;Subcategory和Category也是多对一的关系。
如同在关系型数据库中需要理解和定义字段间功能性依赖关系,在Analysis Services中为了正确聚合数据、有效存储和查找数据,你必须理解属性间关系。为了帮助你在属性间创建联系,Analysis Services提供了属性关系特征。顾名思义,属性关系用于描述两个属性间的关系。
在最初创建维度时,Analysis Services自动将主键和属性间建立多对一关系,如图 5。

图 5 默认属性关系
图 5中的箭头代表了Product Key与维度其他属性间的关系。图 5是一种有效,但是没有经过优化的维度结构,因为它没有为Analysis Services指明属性间的关系。
使用这种设计,当查询中包含了维度中的属性时,数据永远由维度主键汇总。比如,当你要按Subcategory查询销售量时,需要汇总Product Key级别的销售量;当你要按Category查询销量时,也需要汇总Product Key级别的销售量。这可以说是低效能的,因为Category属性的销售量可由Subcategory属性销售量汇总。而且,使用这种设计,Analysis Services不知道某种属性成员组合是否存在,它必须使用事实数据来识别有意义的成员组合。例如,Category属性包含成员“附件“,Subcategory属性包含成员“山地车”,“山地车”不属于“附件”,所以“山地车”和“附件”的组合是无意义的。但如果没有定义属性关系,而按Category和Subcategory属性组合来查询数据,Analysis Services就不能准确地确定“山地车”和“附件”的组合是否存在。
为了优化维度设计,首先你必须理解属性间的关系,并进行一些设置,让Analysis Services明白这些关系。
为了增强产品维度设计,图 6中使用属性关系来优化维度设计。
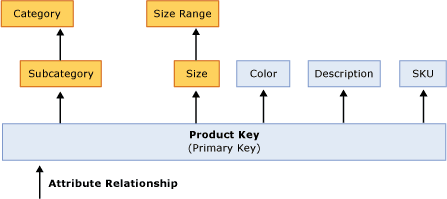
图 6 优化属性关系的产品维度
注意图 6和图 5的区别。图 5中,所有属性关联到主键。而在图 6中加入了两个属性关系,Size关联到Size Range,Category关联到Subcategory,这反映了属性间的多对一关系。
典型的多对一关系如图 6中层次那样。层次表明了多对一关系,但Analysis Services不会自动检验所有层次是否满足多对一关系。所以当属性加入层次前,你必须保证属性间能严格满足多对一关系。如果创建了违反多对一规则的层次,查询时就会得到错误的结果。
举个例子,你有一个时间维度带有月属性和年属性,月属性包含值1月、2月、……、12月,年属性包含2004、2005、……。当你在月属性和年属性间建立了关系,Analysis Services在处理时就不知道如何将月分配到年。Analysis Services不知道将1月关联到2004还是2005。唯一能保证正确建立关系的方法是在月属性的KeyColumns参数包含月列和年列。
KeyColumns是唯一标识属性成员的源列或源列集合。一旦你在属性间建立关系,就要注意KeyColumns。必须确保维中的每个属性的KeyColumns能唯一标识属性成员。如果KeyColumns不是唯一标识属性成员,在处理时遇到重复成员会默认忽略,结果导致不正确的汇总。
注意,如果属性关系有默认的Type,当Analysis Services遇到重复的月时,会错误地将所有月分配给第一或最后的年(依据于数据刷新方法),而且不会提示任何错误。关于Type参数和数据刷新方法对重复键的影响,参考“优化维度成员Insert, Update, Delete”章节。
无论选择何种数据刷新方法,键重复通常都会产生错误的数据汇总,你应该正确设置唯一的KeyColumns来避免这种情况。如果正确配置了KeyColumns,最好修改维度的默认错误配置,以确保处理时不再忽略重复键。将KeyDuplicate值从IgnoreError改成ReportAndContinue或ReportAndStop,这样在遇到重复键时Analysis Services将发出警告信息。
定义了新的属性关系后,为了性能和数据正确性,必须删除多余的关系。图 6中,在加入了新的关系后,Product Key不再需要直接关联Size Range和Category,所以要删除这两个关系。为了帮助你识别多余的属性关系,Business Intelligence Development Studio提供了可视化的警告。
虽然Product Key不再需要直接关联Size Range和Category,但仍然通过属性关系链间接地关联到这些属性。比如,Product Key关联到Size,Size关联到Size Range,这种属性关系链叫做层叠属性关系。
有了层叠属性关系,Analysis Services就能够更好的优化聚合设计、数据存储、数据查找和MDX计算。除了性能方面的优点,属性关系也可以用来增强维度安全,可以用来将度量数据关联到非主键粒度属性。例如,你的销售度量数据粒度是Product Key,但你的预测度量数据粒度是Subcategory,有了Subcategory与Category的属性关系,你的预测度量数据就可以汇总到Category。
设计有效属性关系的核心原则是依据业务逻辑建立维度模型。这里提供优化维度设计的指导和最佳方案,为了设计成功的模型,你必须非常熟悉数据和数据所支持的业务需求。
考虑这样的例子:你的时间维度带有一个称为Day of Week的属性。这个属性包含七个成员,既“星期一”到“星期日”。你可能会想到修改此属性的KeyColumns参数,使星期能与日历日期关联起来,比如将星期与年月组成层次。但你又必须考虑到,某些场合下需要独立分析一周七天的销售变化。所以最好的设计依赖于业务需求。
有效使用层次
在Analysis Services中,用户可以使用属性建立两种层次:属性层次和用户层次。不同的层次对查询性能有不同的影响。
属性层次是维度中默认建立的。对非父子层次,每个属性层次包括两级:属性本身和All级别。尽管All默认是每一个属性层次的最顶部级别,但你也可以通过设置IsAggregatable参数禁用All级别。在大多数情况下,不建议禁用All级别。禁用All级别后,你的查询总是要用此属性层次中一个特定的成员进行切片。当你显式指定Default Member控制切片时,注意所有查询都将使用此切片,而不管你的查询语句中是否引用了此属性层次。
(※注:原文不是很清楚,我解释一下。例如,一个度量值销售量关联到产品、日期、客户三个属性层次。如果要列出产品的销售量,你会查询{ 销售量, 产品.Members },相当于是查询{ 销售量, 产品.Members, 日期.All, 客户.All }。一旦禁用了日期的All层次后,查询时需要在MDX语句中为日期指定成员用于切片,或者设置日期的Default Member,比如将日期默认成员设置为2007年1月1日,那么当你使用同样的查询时,实际上是在查询{ 销售量, 产品.Members, 日期. 2007年1月1日, 客户.All },会用到日期的默认成员来切片)
就性能来说,属性层次中的属性不会自动聚合。当在查询中用到这些属性时,需要通过主键汇总数据。这样的话,查询性能可能会不理想。
为了增强性能,可以通过设置Aggregation Usage参数将属性标识为用于聚合备选。关于此技术手段的详细信息,参考“定义聚合备选”章节。不过,在修改Aggregation Usage前,先考虑是否可以使用用户层次来增强性能。
在用户层次中,属性被分派到预定义的多级导航树中,使得终端用户能更快捷的分析数据。Analysis Services能让你建立两种用户层次:自然和非自然层次。
<!--[if !supportLists]-->· <!--[endif]-->自然层次中,级别间的成员是直接或非直接的由底到高层的关系。大多数情况下,自然层次遵从多对一的关系。图6中产品维度的例子中,可以创建产品分组层次,此层次由低向上包含产品、产品子类别和产品类别。层次中所有属性都直接关联到上层属性,而不是直接关联到Product Key。另外,如果从层次中移除了产品子类别属性,产品和产品类别仍可构成自然层次。因为产品非直接关联到产品类别,两者是层叠属性关系。
<!--[if !supportLists]-->· <!--[endif]-->在非自然层次中,至少包含两个没有属性关系的连续层次。通常这种层次只是用来创建下钻路径以便用户能在客户端使用。
从性能上看,自然层次和非自然层次差别很大。自然层次中,层次树物化的存储在磁盘中,而且自然层次中的所有属性自动用于聚合备选。自然层次的这一特点非常重要,所以如果有可能,尽量创建自然层次。关于聚合备选的信息,参考“定义聚合备选”章节。
非自然层次不会物化存储在磁盘上,而且属性不会自动用于聚合备选。仅仅提供一种易于使用的下钻路径。你也可以使用各种MDX导航函数将所需的属性集合到层次中,所以另一种代替非自然层次的方法是在查询时,在MDX语句中使用cross-join。cross-join和非自然属性性能上差不多。非自然属性仅仅是提供了重用性和集中管理的好处。
若想要使用自然层次,你必须正确设置了层次中属性层叠关系。因为创建属性关系和创建层次是独立的步骤,所以你可能会忘记为层次中的属性定义属性关系。这样的话,就算你需要的是自然层次,但Analysis Services 会自动将此层次标示为非自然层次。
为了验证你创建的层次的类型,如果层次中缺少属性关系,Business Intelligence Development Studio会显式警告图标 目的是帮助你发现非自然层次。如果你的目的就是要创建非自然层次,那么你可以忽略此警告图标。
而且,需要注意属性层次、自然层次和非自然层次在客户端显示的方式。例如,你有一系列地理属性,这些属性已包含在用户层次中。你就应该考虑隐***立的属性层次,以免用户同时看到属性层次和由属性组成的用户层次。要隐藏属性层次,修改AttributeHierarchyVisible参数。














 127
127











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









