DeepLearning中文分词实践
DeepLearning中文分词实践










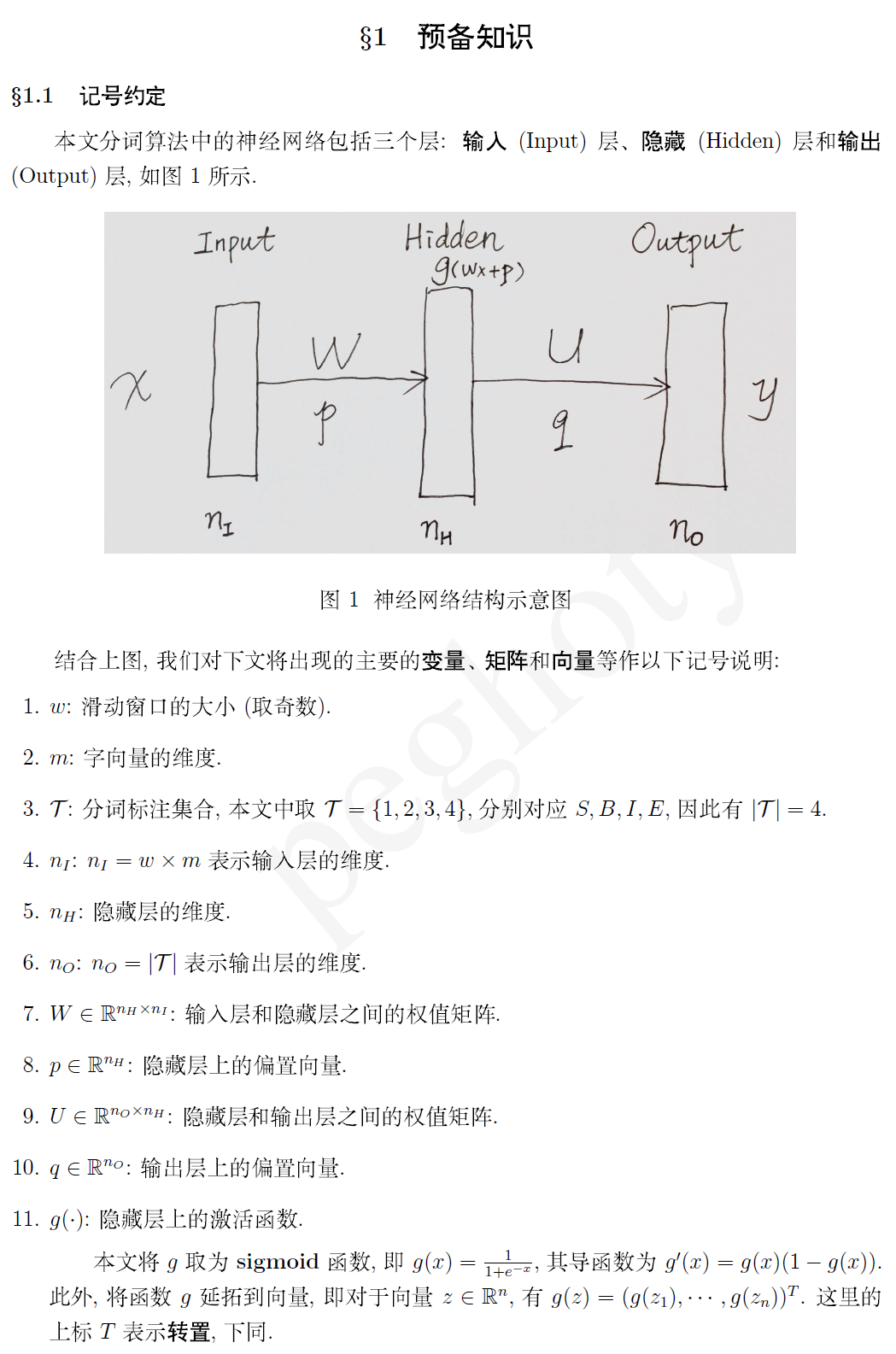
最近针对之前发表的一篇博文《Deep Learning 在中文分词和词性标注任务中的应用》中的算法做了一个实现,感觉效果还不错。本文主要是将我在程序实现过程中的一些数学细节整理出来,借此优化一下自己的代码,也希望为对此感兴趣的朋友提供点参考。文中重点介绍训练算法中的模型参数计算,以及 Viterbi 解码算法。
 本文分享了《DeepLearning在中文分词和词性标注任务中的应用》算法的实际编程实现经验,重点介绍了模型参数计算及Viterbi解码算法。
本文分享了《DeepLearning在中文分词和词性标注任务中的应用》算法的实际编程实现经验,重点介绍了模型参数计算及Viterbi解码算法。
本文分享了《DeepLearning在中文分词和词性标注任务中的应用》算法的实际编程实现经验,重点介绍了模型参数计算及Viterbi解码算法。
本文分享了《DeepLearning在中文分词和词性标注任务中的应用》算法的实际编程实现经验,重点介绍了模型参数计算及Viterbi解码算法。
最近针对之前发表的一篇博文《Deep Learning 在中文分词和词性标注任务中的应用》中的算法做了一个实现,感觉效果还不错。本文主要是将我在程序实现过程中的一些数学细节整理出来,借此优化一下自己的代码,也希望为对此感兴趣的朋友提供点参考。文中重点介绍训练算法中的模型参数计算,以及 Viterbi 解码算法。
 6072
1133
2205
3569
6072
1133
2205
3569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言