







Hive数据仓库 可以将sql变成mapreduce任务
HIVE:HQL和MySQL语句相差不多
2.Hive中数据库的概念本质上仅仅是表的一个目录或者命名空间。如果用户没有显式指定数据库,就会默认使用默认库default。
3.默认创建的是托管表,在load时不检查数据是否符合格式,因为load是移动操作,将数据从原来的地方移动到了hive的warehouse下,只有查询时才会知道
4.将日志文件以时间戳进行分区,可以提高查询效率。关键字是partitioned by
5.将表或者分区放入桶时,将获得更好的查询效率,同时取样更方便,关键字是CLUSTERED BY(userid) [SORTED BY(viewTime)] INTO 32 BUCKETS,使用了hash,建议使用hive来进行划分桶的操作。
6.location指定的是hive中的表存储的文件夹的路径,而使用默认路径的话,则在/user/hive/warehouse下创建表名对应的文件夹,truncate table可以删除内部表的数据,但不会删除表即不会删除hdfs上的文件夹
7.外部表不可以使用truncate table删除表的数据,使用drop table 时不会将location下的文件删除
8.load导入数据本质上是移动数据,即hdfs上数据的位置发生了改变。
9.hive 中的表在mysql中的位置是hive–>TBLS,字段在COLUMNS_V2表中,SDS保存着表在hdfs中的位置
命令位置:
/letv/data/apache-hive-0.13.1-bin/bin
查看所有的数据库:
hive> show databases ;
查看当前有DB有啥表:hive> SHOW TABLES IN DbName;
查看表信息:desc sys_user_info
删除表数据:truncate table nglog_analyze;
创建表
hive>create table wyp (id int, name string, age int, tel string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t’ LINES TERMINATED BY '\n’ STORED AS TEXTFILE;
FIELDS TERMINATED BY '\t’:表示字段之间用tab分割,
LINES TERMINATED BY '\n’:表示行之间用回车分割
STORED AS TEXTFILE:表示储存为txt格式
数组或者是map
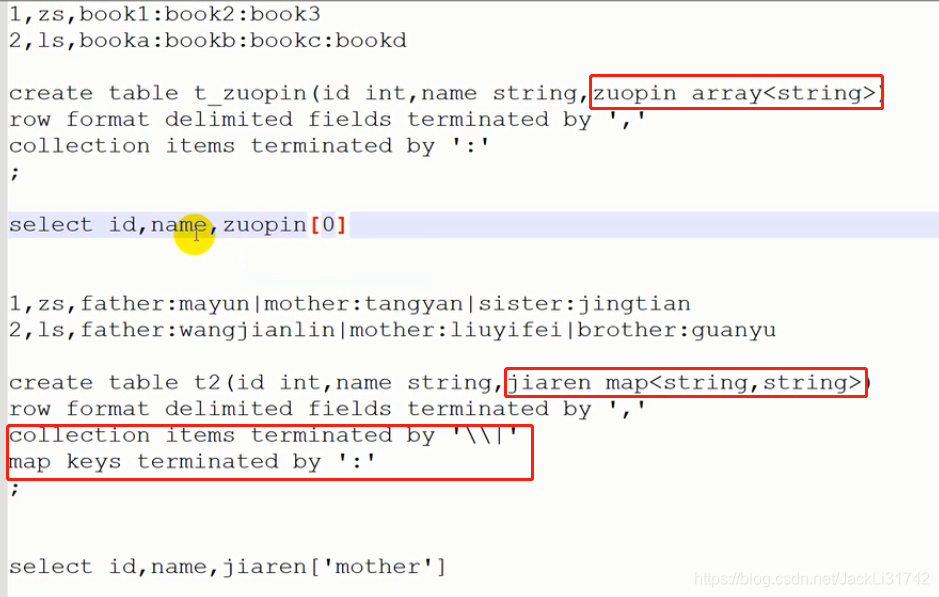
结构体:

加载的数据必须严格按照这个格式,否则就是null
**
而且数据本身之间的空格如果有其他分隔符存在是无需在字段分割中体现的,否则就会出现数据全都在,但在每一行数据之后都会存在null字段,而且null字段的数量比数据字段数少一个,而如果字段之间仅仅以空格分隔,则创建表时必须使用’ ‘来分隔,而不能使用’\0’。
hive 导入数据出错,可以使用 select * from nglog_analyze1 limit 10; 和原始数据对比
**
加载数据
hive>LOAD DATA LOCAL INPATH '/root/id' INTO TABLE t1; // 从本地文件加载
hive>LOAD DATA INPATH '/root/id' INTO TABLE t1; // 从HDFS中加载
从其他hive表导入,只需要创建字段即可,不用分割之类的东西
insert into table nglog_analyze2 select remote_addr,http_marketChannelName,http_x_forwarded_for,upstream_addr from nglog_analyze3;
查看表信息
desc formatted ChannelSort;
参考:
hive教程:
http://blog.csdn.net/lifuxiangcaohui/article/details/40588929
http://blog.csdn.net/lifuxiangcaohui/article/details/40615843
http://blog.csdn.net/hguisu/article/details/7256833
http://my.oschina.net/yangzhiyuan/blog/228362
http://www.cnblogs.com/edisonchou/p/4426096.html
http://jingyan.baidu.com/album/624e7459b705f734e8ba5a1d.html
hive优化
http://itindex.net/detail/53011-hive-%E6%80%A7%E8%83%BD-%E4%BC%98%E5%8C%96
hive、hbase、pig的关系
http://www.linuxidc.com/Linux/2014-03/98978.htm
Hive点滴 – 数据类型
http://debugo.com/hive-datatype/
http://www.bkjia.com/yjs/1049153.html
类型转换:
http://www.iteblog.com/archives/892
函数:
http://dataguild.org/?p=6381
http://blog.csdn.net/skywalker_only/article/details/38752003
http://my.oschina.net/repine/blog/193867
http://blog.csdn.net/yhao2014/article/details/46312469
hive分析
http://life.leanote.com/post/c2242f5a500e
https://www.zybuluo.com/aitanjupt/note/209968
动态分区
http://blog.csdn.net/jiedushi/article/details/7356015
小技巧
http://www.iteblog.com/archives/831
http://sjq597.github.io/2015/11/11/Hive-SemanticException-Error-10025-Line-1-7-Expression-not-in-GROUP-BY-key/
where 陷进
http://blog.csdn.net/mashroomxl/article/details/22223777
hive 搭建
http://www.jianshu.com/p/763d5c665a23
hive的启动和停止以及查看状态
https://blog.csdn.net/zh_s_z/article/details/80972422














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









