







 本文介绍MySQL读写分离的实现原理及Lua脚本示例,并探讨如何利用bin-log日志进行数据库备份与恢复,包括误操作的精确恢复。
本文介绍MySQL读写分离的实现原理及Lua脚本示例,并探讨如何利用bin-log日志进行数据库备份与恢复,包括误操作的精确恢复。
mysql的读写分离的基本原理是:让master(主数据库)来响应事务性操作,让slave(从数据库)来响应select非事务性操作,然后再采用主从复制来把master上的事务性操作同步到slave数据库中。

主从复制只要还是使用log_bin日志来实现主从复制,也可做增量备份
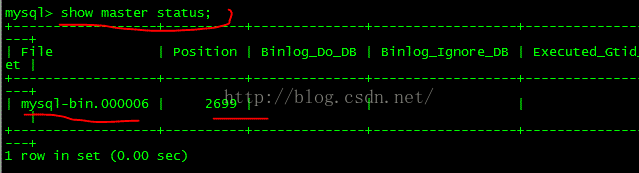
显示binlog二进制日志的柱表,一般都是position 106开始的。可以使用mysql的mysqlbinlog命令查看
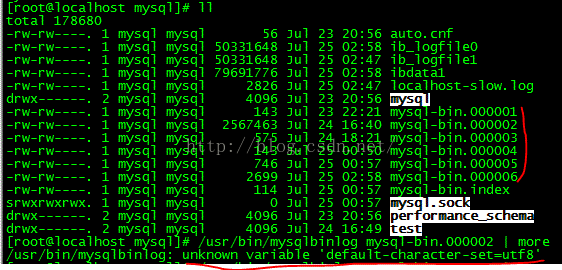
报错的原因是my.cnf中配置了default-character-ser=utf8,可以使用参数--no-defaluts参数来解决

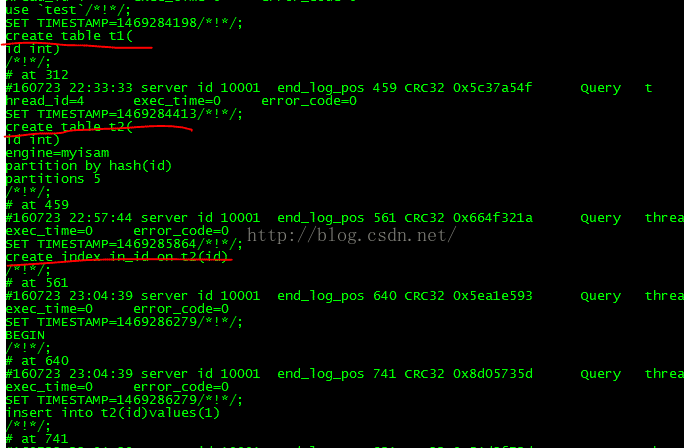
从中可以看到,所有的对表的操作都会记录下来。
首先我们先进行一次数据库备份,在备份的时候加上参数-F表示备份后产生一个新的bin-log日志来记录备份后的操作

参数中-l表示加读锁,等备份完成后自动解锁
然后进行一些mysql的操作例如表中插入数据都会记录到bin-log日志中,例如误删除了表等。

我们需要恢复之前备份的数据,然后数据库备份后数据只能通过bin-log日志来恢复这些操作。

这里的-v参数会记录恢复的详细信息,-f表示当遇到错误时,可以跳过去,继续执行下面的语句。
数据库恢复后,备份数据后的操作不能恢复,这就需要bin-log日志恢复了
执行语句 mysqlbinlog --no-defaults mysql.bin.000003 | mysql -uroot -p 密码
如果从bin-log日志中恢复误操作的语句,可以使用设置恢复position的位置区间来精确定位 --start-position="459" --stop-position="561",也可根据时间点来恢复

可通过查看binlog日志中内容来确定要恢复的position区间

《MySQL Proxy learns R/W Splitting》中详细的介绍了这种技巧以及连接池问题:
为了实现读写分离我们需要连接池。我们仅在已打开了到一个后端的一条经过认证的连接的情况下,才切换到该后端。MySQL协议首先进行握手。当进入到查询/返回结果的阶段再认证新连接就太晚了。我们必须保证拥有足够的打开的连接才能保持运作正常。
实现读写分离的LUA脚本:
-- 读写分离
--
-- 发送所有的非事务性Select到一个从数据库
if is_in_transaction == 0 and
packet:byte() == proxy.COM_QUERY and
packet:sub(2, 7) == "SELECT" then
local max_conns = -1
local max_conns_ndx = 0
for i = 1, #proxy.servers do
local s = proxy.servers[i]
-- 需要选择一个拥有空闲连接的从数据库
if s.type == proxy.BACKEND_TYPE_RO and
s.idling_connections > 0 then
if max_conns == -1 or
s.connected_clients < max_conns then
max_conns = s.connected_clients
max_conns_ndx = i
end
end
end
-- 至此,我们找到了一个拥有空闲连接的从数据库
if max_conns_ndx > 0 then
proxy.connection.backend_ndx = max_conns_ndx
end
else
-- 发送到主数据库
end
return proxy.PROXY_SEND_QUERY 
















 1278
1278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









