




 Apache Zeppelin是一款提供web界面的数据分析和可视化平台,支持Spark、Hive等多种数据处理引擎。本文详述了Zeppelin的安装部署过程,包括删除zeppelin-web项目pom.xml的特定内容,手动配置npm和node,以及编译其他项目。同时,文章还介绍了如何配置和启动Zeppelin,以实现数据的交互式分析和协作。
Apache Zeppelin是一款提供web界面的数据分析和可视化平台,支持Spark、Hive等多种数据处理引擎。本文详述了Zeppelin的安装部署过程,包括删除zeppelin-web项目pom.xml的特定内容,手动配置npm和node,以及编译其他项目。同时,文章还介绍了如何配置和启动Zeppelin,以实现数据的交互式分析和协作。
Zeppelin介绍
Apache Zeppelin提供了web版的类似ipython的notebook,用于做数据分析和可视化。背后可以接入不同的数据处理引擎,包括spark, hive, tajo等,原生支持scala, java, shell, markdown等。它的整体展现和使用形式和Databricks Cloud是一样的,就是来自于当时的demo。
Zeppelin可实现你所需要的:
- 数据采集
- 数据发现
- 数据分析
- 数据可视化和协作
支持多种语言,默认是scala(背后是spark shell),SparkSQL, Markdown 和 Shell。

甚至可以添加自己的语言支持。如何写一个zeppelin解释器
Zeppelin特性
Apache Spark 集成
Zeppelin 提供了内置的 Apache Spark 集成。你不需要单独构建一个模块、插件或者库。
Zeppelin的Spark集成提供了:
- 自动引入SparkContext 和 SQLContext
- 从本地文件系统或maven库载入运行时依赖的jar包。更多关于依赖载入器
- 可取消job 和 展示job进度
数据可视化
一些基本的图表已经包含在Zeppelin中。可视化并不只限于SparkSQL查询,后端的任何语言的输出都可以被识别并可视化。
Bank
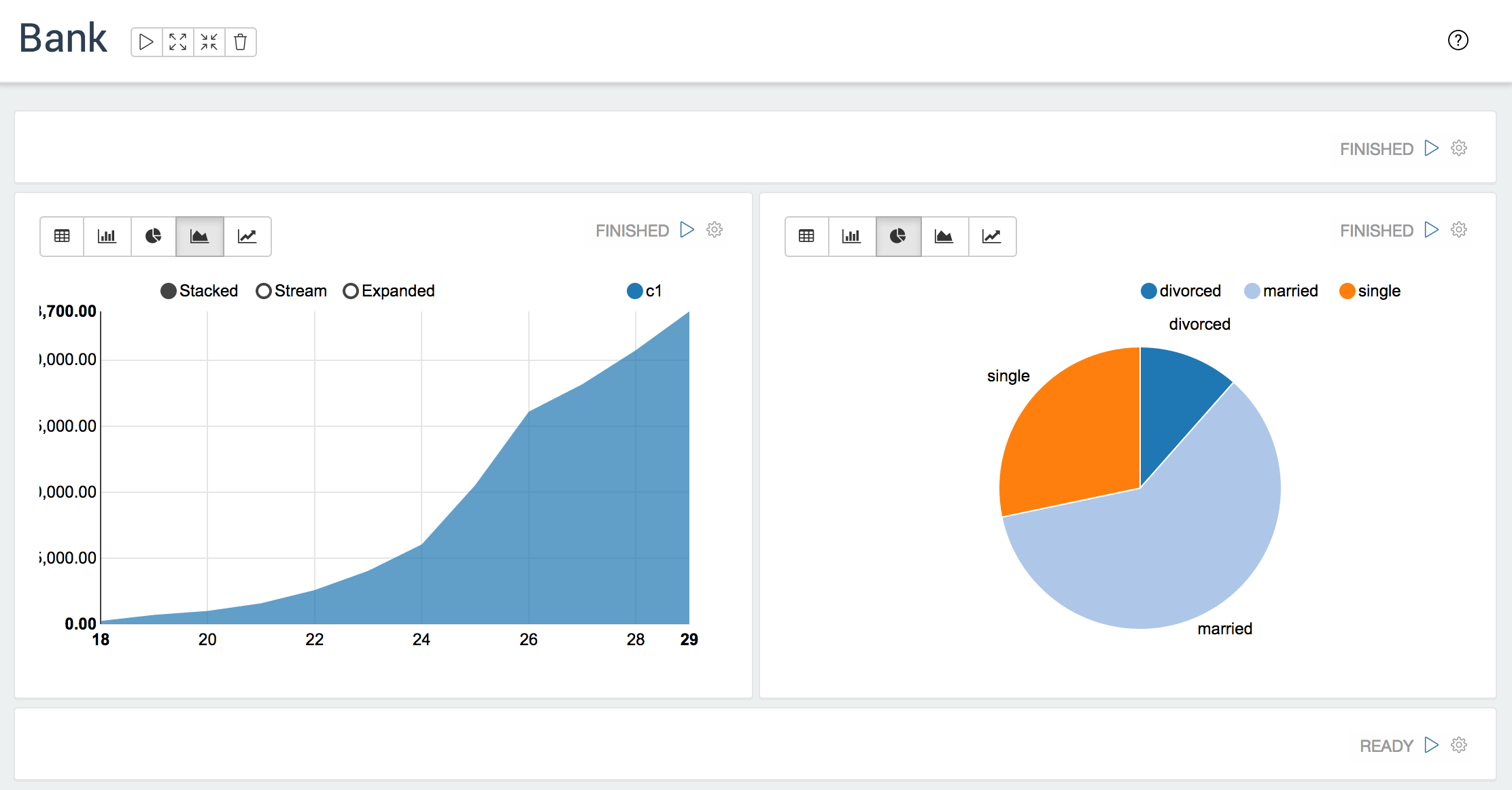
动态表格
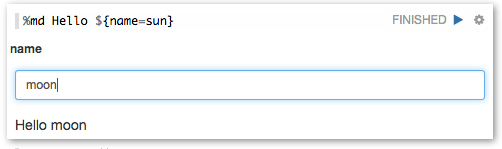
Zeppelin 可以在你的笔记本中动态地创建一些输入格式。
协作
Notebook 的 URL 可以在协作者间分享。 Zeppelin 然后可以实时广播任何变化,就像在 Google docs 中一样。
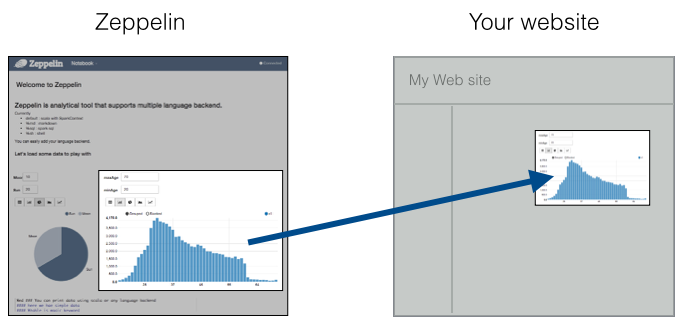
发布
Zeppelin提供了一个URL用来仅仅展示结果,那个页面不包括Zeppelin的菜单和按钮。这样,你可以轻易地将其作为一个iframe集成到你的网站。
Zeppelin的安装部署
由于Zeppelin目前不提供binary安装包,所以这里Zeppelin的安装需要自己编译。
这里可以参考Zeppelin Github和Install Zeppelin
准备工作
需要
Java 1.7
Tested on Mac OSX, Ubuntu 14.X, CentOS 6.X
Maven (if you want to build from the source code)
Node.js Package Manag
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 54
54

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









