







折腾了两天,总算把环境搭起来了,由于很多资料都是基于Hadoop1.0的,而目前的2.0以上的Hadoop架构发生变化,因此一些老旧的资料就已经不再适用,而我又实在是不喜欢看官方文档,所以整理出这篇攻略给同样不喜欢看英文文档的你(如果你喜欢看还会百度中文的资料么;-)
目标:组成一个由四台电脑构成的简单集群,其中一台为master,余下三台为slave。
环境:Ubuntu 14.04 LTS 64bit + JDK1.8.0u74 + Hadoop2.6.4
一、创建Hadoop集群用户组
1.分别在四台主机上创建一个新用户,名为hadoop,所属群组为hadoop,并设置新用户密码:
sudo adduser hadoop2.检查hadoop是否拥有sodu权限
sudo cat /etc/group|grep sudo回车之后会显示拥有sodu权限的用户,类似于:
sudo:x:27:tangyeah,hadoop3.如果hadoop用户没有列出,需手动将hadoop加入到sudo用户组:
sudo /usr/sbin/usermod -G 27 hadoop这样新建的hadoop用户就可以使用sudo命令临时获取root权限了。
二、修改主机名
四台主机的规划如下:
| ip地址 | 主机名 | 用途 |
|---|---|---|
| 9.119.131.131 | master | NameNode |
| 9.119.131.56 | slave1 | DataNode |
| 9.119.133.213 | slave2 | DataNode |
| 9.119.133.99 | slave3 | DataNode |
使用如下命令查看本机ip地址:
hadoop@pc1:~$ ifconfig1.分别更改4台主机的主机名,此处仅以NameNode为例:
sudo nano /etc/hostname将其内容改为master,保存并关闭。
2.分别配置四台主机的hosts文件:
sudo nano /etc/hosts将以下代码加入到hosts中:
9.119.131.131 master
9.119.131.56 slave1
9.119.133.213 slave2
9.119.133.99 slave3保存并关闭,注意一式四份,每台都要配。
三、设置ssh免密码验证
1.安装必要的组件
sudo apt-get install rsync
sudo apt-get install openssh-client
sudo apt-get install openssh-server2.使用hadoop用户登陆master,生成公钥、私钥对
hadoop@master:~$ sudo ssh-keygen -t rsa -p''3.将id_rsa.pub加入到授权的key中
hadoop@master:~$ sudo cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys4.在本机上测试一下,自己连自己:
hadoop@master:~$ ssh master第一次连接需要输入yes确认,若仍需要输入密码则需要提高authorized_keys的权限:
hadoop@master:~$ sudo chmod 600 .ssh/authorized_keys至此,第一台机器就搞定了。
5.hadoop用户分别登陆其余slave机,分别如上生成密钥对。
6.将3台slave的id_rsa.pub复制到master上:
slave1:
hadoop@slave1:~$ scp /home/hadoop/.ssh/id_rsa.pub hadoop@master:/home/hadoop/.ssh/slave1slave2:
hadoop@slave2:~$ scp /home/hadoop/.ssh/id_rsa.pub hadoop@master:/home/hadoop/.ssh/slave2slave3:
hadoop@slave3:~$ scp /home/hadoop/.ssh/id_rsa.pub hadoop@master:/home/hadoop/.ssh/slave37.将三台slave的密钥加入到授权的key中
hadoop@master:~$ sudo cat ~/.ssh/slave1 >> ~/.ssh/authorized_keys
hadoop@master:~$ sudo cat ~/.ssh/slave2 >> ~/.ssh/authorized_keys
hadoop@master:~$ sudo cat ~/.ssh/slave3 >> ~/.ssh/authorized_keys至此,三台slave登入master就应该可以免密码登入了。
8.将master的授权公钥复制到所有的slave机器上
hadoop@master:~$ scp /home/hadoop/.ssh/authorized_keys hadoop@slave1:/home/hadoop/.ssh/authorized_keys
hadoop@master:~$ scp /home/hadoop/.ssh/authorized_keys hadoop@slave2:/home/hadoop/.ssh/authorized_keys
hadoop@master:~$ scp /home/hadoop/.ssh/authorized_keys hadoop@slave3:/home/hadoop/.ssh/authorized_keys至此,master登入三台slave也可以免密码登入了,可以在任意一台电脑上登陆任意其他电脑或自己测试一下。
hadoop@master:~$ ssh slave2
hadoop@slave2:~$ ssh slave2
hadoop@slave2:~$ ssh slave3
hadoop@slave3:~$ ssh master四、下载安装JDK和Hadoop镜像
先在master上安装配置好,然后复制到slave上。
1.JDK的下载和安装
略,参考http://blog.csdn.net/jasonty/article/details/50936982
2.Hadoop2.6.4的下载和安装
Hadoop2.6.4官方下载链接:http://hadoop.apache.org/releases.html
选择2.6.4对应的binary点击下载(source是未编译的源代码,需要另搭环境重新编译),解压缩并移至/usr文件夹下,重命名为hadoop
hadoop@master:~$ tar -zxvf /home/tangyeah/Downloads/hadoop-2.6.4.tar.gz
hadoop@master:~$ sudo cp -r /home/tangyeah/hadoop-2.6.4 /usr
hadoop@master:~$ sudo mv /usr/hadoop-2.6.4 /usr/hadoop3.更改环境变量
hadoop@master:~$ sudo nano /etc/profile添加如下代码:
export JAVA_HOME=/usr/java
export HADOOP_HOME=/usr/hadoop
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
保存关闭,并使之生效:
hadoop@master:~$ source /etc/profile五、修改Hadoop配置文件
共有7个文件需要配置,列出清单如下:
/usr/hadoop/etc/hadoop/hadoop-env.sh
/usr/hadoop/etc/hadoop/yarn-env.sh
/usr/hadoop/etc/hadoop/core-site.xml
/usr/hadoop/etc/hadoop/hdfs-site.xml
/usr/hadoop/etc/hadoop/yarn-site.xml
/usr/hadoop/etc/hadoop/mapred-site.xml
/usr/hadoop/etc/hadoop/slaves
1.hadoop-env.sh
# The java implementation to use.
export JAVA_HOME=/usr/java
# Assuming your installation directory is /usr/local/hadoop
export HADOOP_PREFIX=/usr/hadoop2.yarn-env.sh
export JAVA_HOME=/usr/java3.core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>/home/hadoop/tmp需手动创建
4.hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/hadoop/names</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/hadoop/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.datanode.ipc.address</name>
<value>0.0.0.0:50020</value>
</property>
<property>
<name>dfs.datanode.http.address</name>
<value>0.0.0.0:50075</value>
</property>
</configuration>/usr/hadoop/names
/usr/hadoop/data
这两个目录也需要手动创建
5.yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>6.mapred-site.xml
如果该文件不存在,手动创建之。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>7.slaves
slave1
slave2
slave3六、Hadoop的启动与关闭
1.关闭防火墙
sudo /etc/init.d/iptables status
sudo /etc/init.d/iptables stop2.NameNode初始化,仅在第一次启动的时候执行。
hadoop@master:~$ cd /usr/hadoop/bin
hadoop@master:/usr/hadoop/bin$ ./hadoop namenode -format3.启动
hadoop@master:~$ cd /usr/hadoop/sbin
hadoop@master:/usr/hadoop/sbin$ start-dfs.sh
hadoop@master:/usr/hadoop/sbin$ start-yarn.sh
4.验证
hadoop@master:~$ jps
8918 SecondaryNameNode
7562 Jps
8701 NameNode
9438 ResourceManager
hadoop@slave1:~$ jps
10322 Jps
4836 ResourceManager
6804 DataNode
4693 SecondaryNameNode
6923 NodeManager
5.关闭
hadoop@master:~$ stop-all.sh七、在浏览器中验证
在浏览器中输入:
master:8088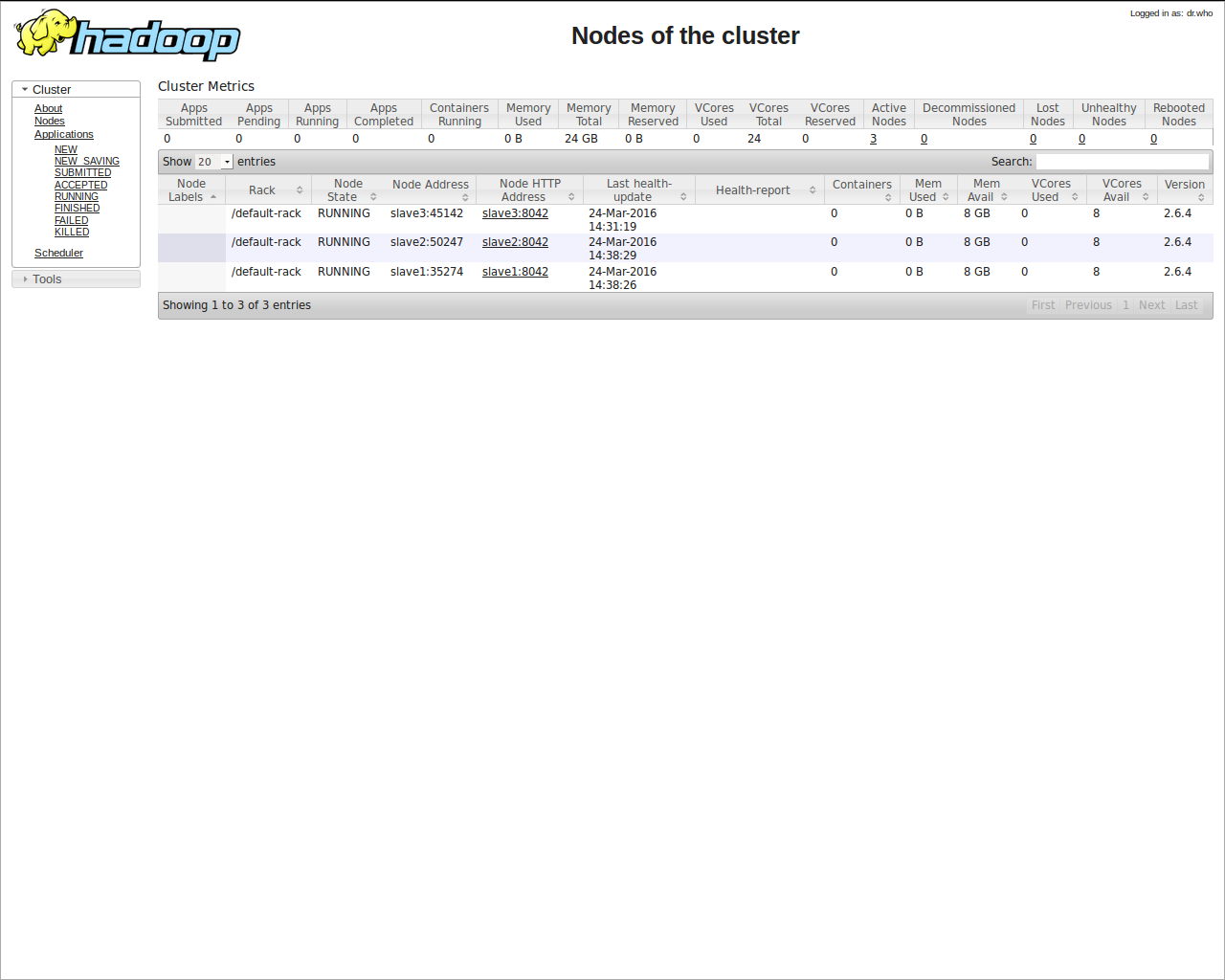
master:50070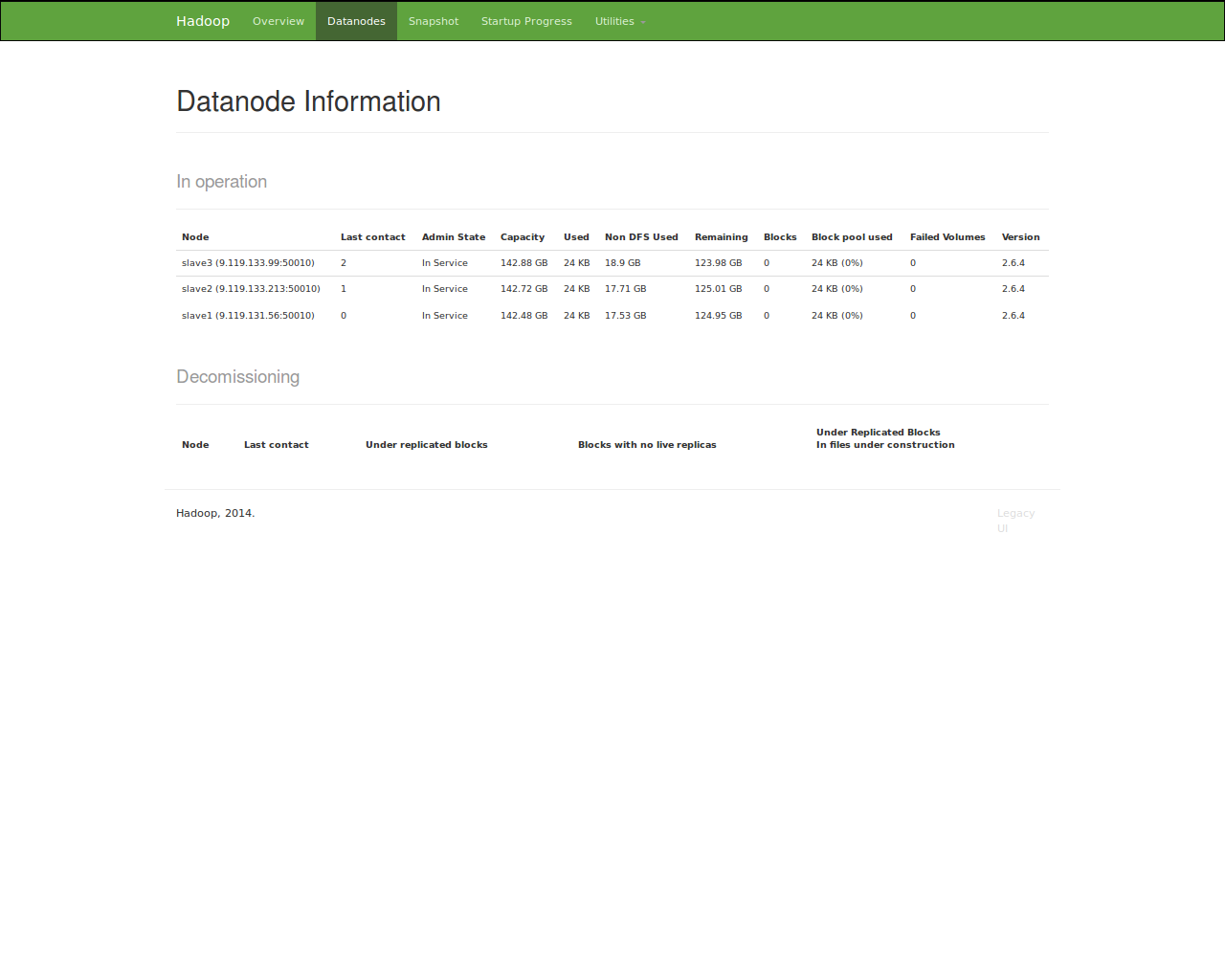
写在最后
需要从master复制到slave的文件清单:
/usr/java
/usr/hadoop
/etc/profile
/etc/hosts增减DataNode需要更改的文件:
/usr/hadoop/etc/hadoop/hdfs-site.xml
/usr/hadoop/etc/hadoop/slaves
/etc/hosts另外如果新加入节点,需要更新集群内所有节点的公钥,以便互相之间可以无密码访问。
如果你完全参照本文步骤却不能实现环境的搭建,多半是某些文件的权限问题,比如/usr/hadoop/log等,仔细查看终端报错的信息,会发现大部分都是permission denied,个人建议把你需要使用的文件的所有者都变成hadoop,这是种笨办法而且会造成不安全的问题,但对于解决问题有立竿见影的效果。
其次,本文作为一篇速食文档只是记录我自己配置的过程,实际情况可能依赖于环境和版本而有所差别,如果想真正系统的掌握Hadoop,还是得去抠官方文档:http://hadoop.apache.org/ (不情愿的@_@)















 801
801











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









