




 本文深入探讨了MapReduce架构,源于Google的MapReduce论文,阐述其易于编程、良好扩展性和高容错性的特点。文章详细讲解了MapReduce编程模型,包括Map和Reduce函数以及输入输出过程。MapReduce执行流程分为Map任务处理和Reduce任务处理,通过MapReduce实例WordCount展示了其在数据处理中的应用。此外,还介绍了Shuffle过程,包括Map Shuffle Phase的分区、溢写和排序,以及Reduce Shuffle Phase的Copy和Merge阶段。最后,讨论了MapReduce作业中Map Task和Reduce Task数目的确定因素。
本文深入探讨了MapReduce架构,源于Google的MapReduce论文,阐述其易于编程、良好扩展性和高容错性的特点。文章详细讲解了MapReduce编程模型,包括Map和Reduce函数以及输入输出过程。MapReduce执行流程分为Map任务处理和Reduce任务处理,通过MapReduce实例WordCount展示了其在数据处理中的应用。此外,还介绍了Shuffle过程,包括Map Shuffle Phase的分区、溢写和排序,以及Reduce Shuffle Phase的Copy和Merge阶段。最后,讨论了MapReduce作业中Map Task和Reduce Task数目的确定因素。
MapReduce定义
源自 Google的MapReduce论文
发表于2004年12月
Hadoop MapReduce是Google MapReduce的克隆版
MapReduce特点
易于编程
良好的扩展性
高容错性
适合PB级以上海量数据的离线处理
MapReduce编程模型
一种分布式计算模型框架,解决海量数据的计算问题
MapReduce将整个并行计算过程抽象到两个函数
——>Map(映射):对一些独立元素组成的列表的每一个元素进行指定的操作,可以高度并行。
——>Reduce(化简):对一个列表的元素进行合并。
一个简单的MapReduce程序只需要指定map()、reduce()、input和output,剩下的事由架构完成。
input()——>map()——>reduce()——>output()

MapReduce系统架构
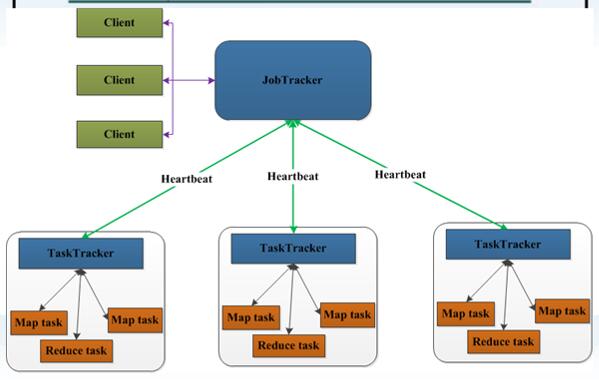
MapReduce——相关概念
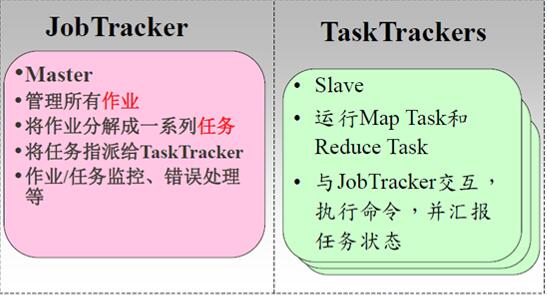
JobTracker负责接收用户提交的作业,负责启动、跟踪任务执行
TaskTracker负责执行由JobTracker分配的任务,管理各个任务在每个节点上的执行情况。
Job,用户的每一个计算请求,称为一个作业。
Task,每一个作业,都需要拆分开了,交由多个服务器来完成,拆分出来的执行单位,就称为任务。
Task分为MapTask和ReduceTask两种,分别进行Map操作和Reduce操作,依据Job设置的Map类和Reduce类
MapReduce——分布式计算框架

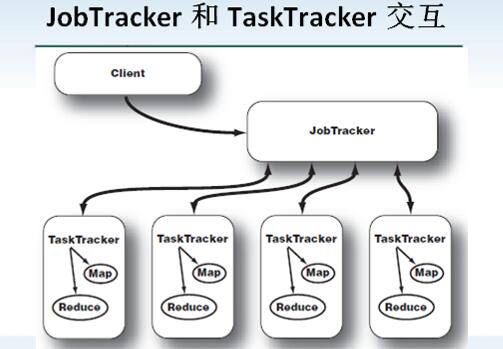
JobTracker与TaskTracker交互
当客户端调用JobTracker来启动一个数据处理作业时,JobTracker会将工作切分,并分配不同的map和reduce任务到集群中的每个TaskTracker上。
MapReduce实例——WordCount
问题:
有一批文件(规模为TB级或者PB级),如何统计这些文件中所有单词出现的次数。
方案:
首先,分别统计每个文件中单词出现的次数。
然后,累加不同文件中同一个单词出现的次数。
MapReduce WordCount实例运行
在dfs中创建input目录
[hadoop1@H01 data]$ hadoop fs -mkdir /wc/input将data中的.data文件拷贝到dfs中的input
[hadoop1@H01 data]$ hadoop fs -put ./*.data /wc/input查看
[hadoop1@H01 data]$ hadoop fs -ls /wc/input
Found 3 items
-rw-r--r-- 1 hadoop1 supergroup 26 2015-10-24 23:42 /wc/input/00.data
-rw-r--r-- 1 hadoop1 supergroup 15 2015-10-24 23:42 /wc/input/1.data
-rw-r--r-- 1 hadoop1 supergroup 523 2015-10-24 23:42 /wc/input/worldcount.data
运行wordcount
[root@H01 hadoop-1.2.1]# hadoop jar hadoop-examples-1.2.1.jar wordcount /wc/inp 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 569
569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









