







Hadoop MapReduce 手机流量统计
1)分析业务需求:
用户使用手机上网,存在流量的消耗。流量包括两部分:其一是上行流量(发送),其二是下行流量(接收)。每种流量在网络传输过程中,有两种形式说明:包的大小,流量的大小。使用手机上网,以手机号为唯一标识进行记录。这个记录包括很多信息,需要的信息字段:
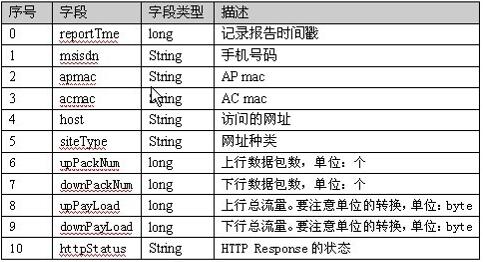
实际需要的字段:
手机号码,上行数据包数,下行数据包数,上行总流量,下行总流量
2)自定义数据类型(五个字段)
DataWritable 实现 WritableComparable 接口。
3)分析MapReduce写法
分析MapReduce写法,哪些业务逻辑在Map阶段执行,那些业务逻辑在Reduce阶段执行。
Map阶段:从文件中获取数据,抽取需要的五个字段,输出的key为手机号码,输出的value为数据流量的类型DataWritable对象。
Reduce阶段:将相同手机号码的value中的数据流量进行相加,得出手机流量的总数(数据包和数据流量)。输出到文件中,以制表符分开。
package org.apache.hadoop.mapreduce.app;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class DataTotalMapReduce {
// Mapper Class
static class DataTotalMapper extends Mapper<LongWritable, Text, Text, DataWritable> {
private Text mapOutputKey = new Text();
private DataWritable dataWritable = new DataWritable();
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String lineValue = value.toString();
// 数据分割 split
String[] strs = lineValue.split("\t");
// 从strs中获取我们需要的几个字段
String phoneNum = strs[1];
int upPackNum = Integer.valueOf(strs[6]);
int downPackNum = Integer.valueOf(strs[7]);
int upPayLoad = Integer.valueOf(strs[8]);
int downPayLoad = Integer.valueOf(strs[9]);
// 设置map输出的key/value
mapOutputKey.set(phoneNum);
dataWritable.set(upPackNum, upPayLoad, downPackNum, downPayLoad);
// 设置map输出
context.write(mapOutputKey, dataWritable);
}
}
// Reducer Class
static class DataTotalReducer extends Reducer<Text, DataWritable, Text, DataWritable> {
private DataWritable dataWritable = new DataWritable();
public void reduce(Text key, Iterable<DataWritable> values, Context context)
throws IOException, InterruptedException {
int upPackNum = 0;
int downPackNum = 0;
int upPayLoad = 0;
int downPayLoad = 0;
// 循环
for (DataWritable data : values) {
upPackNum += data.getUpPackNum();
downPackNum += data.getDownPackNum();
upPayLoad += data.getUpPayLoad();
downPayLoad += data.getDownPayLoad();
}
// 设置输出
dataWritable.set(upPackNum, upPayLoad, downPackNum, downPayLoad);
// 设置reduce/job输出
context.write(key, dataWritable);
}
}
// Driver Code
public int run(String[] args) throws Exception {
// get conf
Configuration conf = new Configuration();
// create job
Job job = new Job(conf, DataTotalMapReduce.class.getSimpleName());
// set job
job.setJarByClass(DataWritable.class);
// 1)input
Path inputDir = new Path(args[0]);
FileInputFormat.addInputPath(job, inputDir);
// 2)map
job.setMapperClass(DataTotalMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(DataWritable.class);
// 3)reduce
job.setReducerClass(DataTotalReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(DataWritable.class);
// 4)output
Path outputDir = new Path(args[1]);
FileOutputFormat.setOutputPath(job, outputDir);
// submit job
boolean isSuccess = job.waitForCompletion(true);
// return status
return isSuccess ? 0 : 1;
}
// run mapreduce
public static void main(String[] args) throws Exception {
// set args
args = new String[] {
// input path
// output path
};
// run job
int status = new DataTotalMapReduce().run(args);
// exit
System.exit(status);
}
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









