







 本文主要探讨了动态查找结构中的二叉查找树(二叉排序树),包括其特点、查找效率分析以及不同情况下的节点删除策略。通过实例展示了在不同情况下查找效率的变化,并提供了基本操作的代码实现。
本文主要探讨了动态查找结构中的二叉查找树(二叉排序树),包括其特点、查找效率分析以及不同情况下的节点删除策略。通过实例展示了在不同情况下查找效率的变化,并提供了基本操作的代码实现。
刚刚介绍完静态查找树查找算法总结(一),接下来谈谈一些常用的动态查找结构。其中包括最基本的二叉排序树(二叉查找树、二叉收索树)、二叉平衡树(AVL树)、红黑树、以及一些多路查找树(B+,B-树)。
二叉排序树 :
特点:
1、如果它的左子树不空,那么左子树上的所有结点值均小于它的根结点值;
2、如果它的右子树不空,那么右子树上的所有结点值均大于它的根结点值;
3、它的左右子树也分别为二叉查找树
如下如所示二叉查找树:
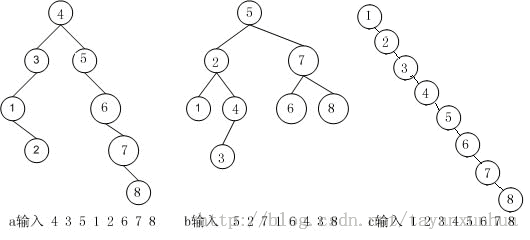
二叉查找树的插入和删除都非常的方便,很好的解决了折半查找添加删除所带来的问题。
那么它的效率又如何呢?
很显然,二叉查找树查找一个数据,不需要遍历全部的节点,查找效率确实提高了。但是,也有一个很严重的问题,我在a图中查找8需要比较5次,而在b图中查找8需要3次,更为严重的是,我的二叉查找树是c图,如果再查找8,那将会如何呢?很显然,整棵树就退化成了一个线性结构,此时再查找8,就和顺序查找没什么区别了。
时间复杂度分析:最坏的情况下和顺序查找相同,是O(N),最好的情况下和折半查找相同,是O(logN)。进过研究发现,在随机的情况下,二叉排序树的平均查找长度和logn是等数量级的。然而,在某些情况下(有人研究表明,这种概率大约占46.5%)尚需在构成二叉排序树的过程中进行”平衡化”处理,成为二叉平衡树。
这说明了一个问题,同样的一组数据集合,不同的添加顺序会导致二叉查找树的结构完全不一样,直接影响到了查找的效率。
二叉排序树的一些基本操作,包括,添加节点,删除节点,获取做大的节点,获取最小的节点,得到任意孩子节点的父节点等。
/**
* 向二叉排序树中添加节点
* @param root
* @param value
* @return 二叉排数树根节点
*/
public static TreeNode insertTreeNode(TreeNode root,int value){
if(root == null){
root = new TreeNode(value);
}else if(root.value>value){
root.left = insertTreeNode(root.left,value);
}else if(root.value<value){
root.right =insertTreeNode(root.right,value);
}
return root;
}/**
* 在二叉排数树中查找,关键字为key的节点
* @param root
* @param key
* @return 二叉排数树中关键字为key的节点
*/
public static TreeNode serachTreeNode(TreeNode root,int key){
if(root == null){
return null;
}
if(key>root.value)
return serachTreeNode(root.right,key);
else if(key<root.value)
return serachTreeNode(root.left,key);
else
return root;
}//获取父节点
public static TreeNode getParentTreeNode (TreeNode root,int key){
Queue<TreeNode> queue = new LinkedList<TreeNode>();
if(root==null || root.value==key){
return null;
}
queue.add(root);
while(!queue.isEmpty()){
TreeNode current = queue.poll();
if(current.left!=null){
if(current.left.value==key)
return current;
else
queue.add(current.left);
}
if(current.right!=null< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 745
745

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









