




 本文介绍如何在Solr6环境中整合中文分词库mmseg4j,包括所需环境搭建、mmseg4j简介及配置过程。mmseg4j基于MMSeg算法实现,支持多种分词模式。
本文介绍如何在Solr6环境中整合中文分词库mmseg4j,包括所需环境搭建、mmseg4j简介及配置过程。mmseg4j基于MMSeg算法实现,支持多种分词模式。
摘要: Solr有诸多分词器,本文介绍Solr6与中文分词库mmseg4j的整合,在此之前,你需要有一个可以运行Solr的环境,参见Solr6.0与Jetty、Tomcat在Win环境下搭建/部署。
准备环境
mmseg4j需要mmseg4j-core-1.10.0.jar和mmseg4j-solr-2.3.0.jar,之前的mmseg4j-analysis已经整合进了mmseg4j-solr-2.3.0.jar,不需要再导入
<dependency>
<groupId>com.chenlb.mmseg4j</groupId>
<artifactId>mmseg4j-core</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>com.chenlb.mmseg4j</groupId>
<artifactId>mmseg4j-solr</artifactId>
<version>2.3.0</version>
</dependency>科普mmseg4j
- mmseg4j 用 Chih-Hao Tsai 的 MMSeg 算法(http://technology.chtsai.org/mmseg/ )实现的中文分词器,并实现 lucene 的 analyzer 和 solr 的TokenizerFactory 以方便在Lucene和Solr中使用。
- MMSeg 算法有两种分词方法:Simple和Complex,都是基于正向最大匹配。
- mmseg4j有三种分词模式simple|complex|max-word,默认是max-word。
- mmseg4j的词库强制使用 UTF-8。
- mmseg4j 1.8.3 只支持 lucene 2.9/3.0 接口 和 solr 1.4。
mmseg4j 1.8.5 支持 lucene 3.1, solr 3.1。
mmseg4j 1.9.0 支持 lucene 4.0, solr 4.0。
mmseg4j 1.9.1 支持 solr/lucene 4.3.1。
mmseg4j-solr-2.0.0.jar 要求 lucene/solr >= 4.3.0。
mmseg4j-solr-2.1.0.jar 要求 lucene/solr 4.8.x。
mmseg4j-solr-2.2.0.jar 要求 lucene/solr [4.9, 4.10.x]。
mmseg4j-solr-2.3.0.jar 要求 lucene/solr [5.0, ] - 开源地址:https://github.com/chenlb/mmseg4j-solr
- 作者chenlb,chenlb是中文名拼音Chen Lin Bin简写,公开资料显示其来自浙江杭州。许多关于mmseg4j的说明可以在他的博客上找到。很可惜的是,现在mmseg4j已经没有更新了,并且mmseg4j已经不能完整支持Solr6及以上版本。
Solr6整合中文分词mmseg4j
- 确保已经装好了Solr6,如果版本高于6,可能会不支持,需要改mmseg4j包
- 解压下载的压缩包mmseg4j-solr-2.3.0-with-mmseg4j-core.zip,得到
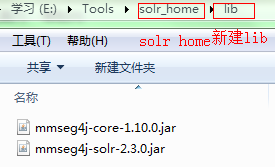
mmseg4j-core-1.10.0.jar和mmseg4j-solr-2.3.0.jar - 在solr_home下新建文件夹
lib,将两个jar文件复制进去。
- 配置
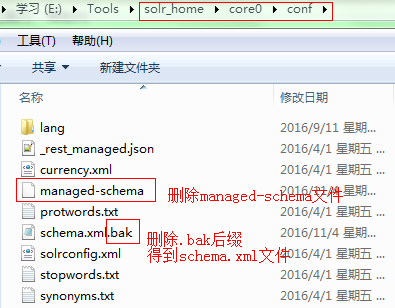
schema.xml:在solr_home/core0/conf下找到schema.xml.bak文件,将其重命名为schema.xml,删除managed-schema。
- 编辑
schema.xml:添加fieldType 和 field到schema.xml文件。
<!-- mmseg4j fieldType-->
<fieldType name="text_mmseg4j_complex" class="solr.TextField" positionIncrementGap="100" >
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex" />
</analyzer>
</fieldType>
<fieldType name="text_mmseg4j_maxword" class="solr.TextField" positionIncrementGap="100" >
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="max-word" />
</analyzer>
</fieldType>
<fieldType name="text_mmseg4j_simple" class="solr.TextField" positionIncrementGap="100" >
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="simple" />
</analyzer>
</fieldType>注意:请不要给tokenizer加”dicPath”属性,因为当前版本2.3.0的mmseg4j已经不能很好支持Solr6,新版本的Solr中有API的改动
<!--mmseg4j field-->
<field name="mmseg4j_complex" type="text_mmseg4j_complex" indexed="true" stored="true"/>
<field name="mmseg4j_maxword" type="text_mmseg4j_maxword" indexed="true" stored="true"/>
<field name="mmseg4j_simple" type="text_mmseg4j_simple" indexed="true" stored="true"/>
6.启动Solr,如果控制台没有报错,那就大功告成了。点击Analysis,测试几个数据看看。下面这个没有分词成南京-市长-江大桥。
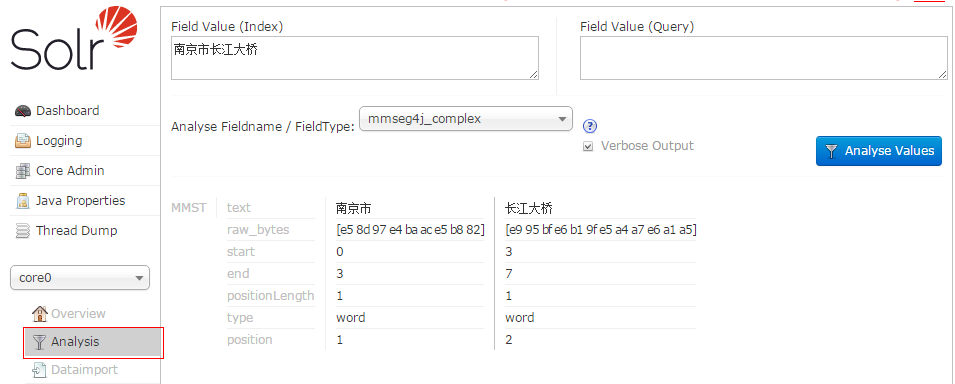
7.如果你没有运行起来,可能遇到了不兼容的问题,在下一篇解答。


















 161
161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











