









 本文介绍了IKAnalyzer和mmseg4j两种常用中文分词器的特点及使用方法,重点讲解了mmseg4j在Solr中的配置过程,包括下载、配置及测试步骤。
本文介绍了IKAnalyzer和mmseg4j两种常用中文分词器的特点及使用方法,重点讲解了mmseg4j在Solr中的配置过程,包括下载、配置及测试步骤。
1 概述
中文分词器有多中,常用的有 IKAnalyzer、 mmseg4j。
引用:
前者最新版本更新到2012年,所以使用的时候要注意可能版本上有不兼容的情况,由于它是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始,IKAnalyzer已经推出了4个大版本。最初,它是以开源项目Luence为应用主体的,结合词典分词和文法分析算法的中文分词组件。从3.0版本开始,IK发展为面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。在2012版本中,IK实现了简单的分词歧义排除算法,标志着IK分词器从单纯的词典分词向模拟语义分词衍化。
使用方法。
主要记录以下mmseg4j的配置,关于mmseg4j介绍:http://www.oschina.net/p/mmseg4j?fromerr=Gtaj9S9O
2 为何引用分词器
使用通常的solr系统提供的分词,可以看到会将字符串切割成每一个词,它把每一个词都分开了,可以预计如果一篇文章这样分词的搜索的体验效果非常差。所以分词器的提供可以对此进行优化。
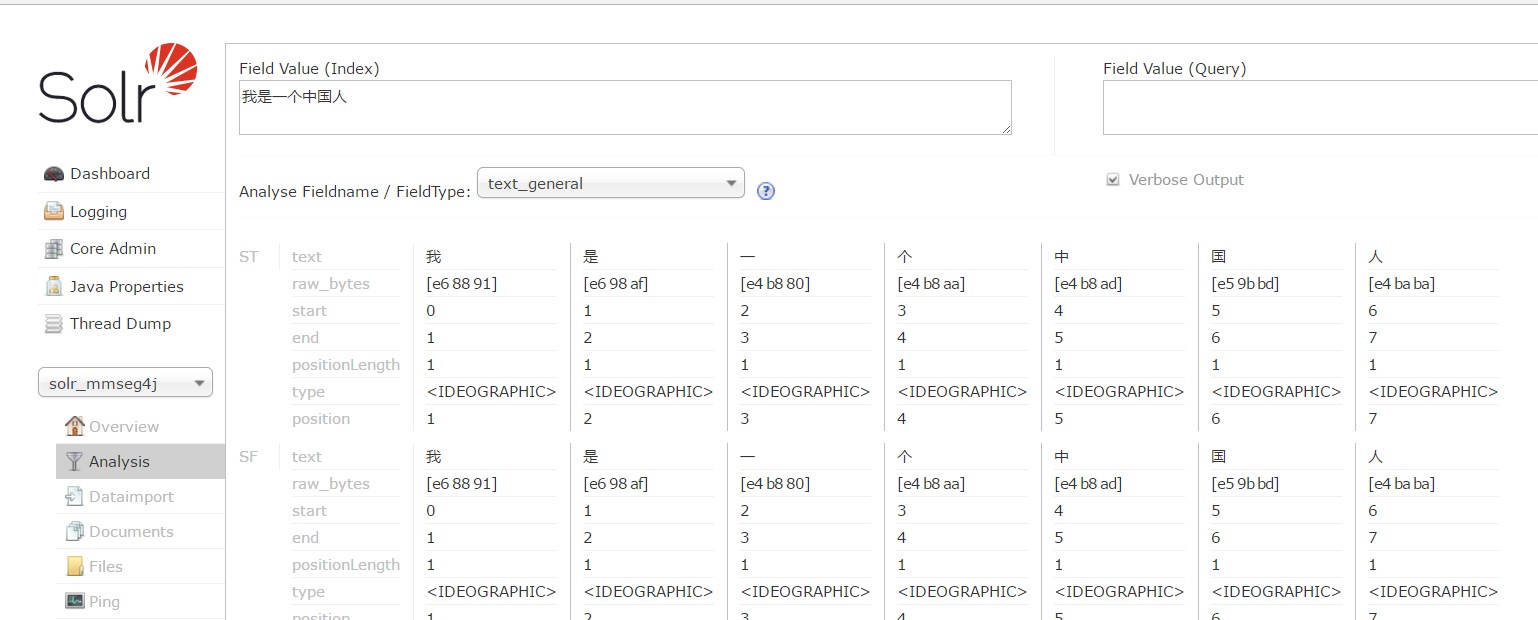
3 配置mmseg4j
3.1 下载
下载地址:https://github.com/chenlb/mmseg4j-solr
可以将源码下载后自行编译成jar
或者使用maven直接下载jar
<dependency>
<groupId>com.chenlb.mmseg4j</groupId>
<artifactId>mmseg4j-solr</artifactId>
<version>2.4.0</version>
</dependency>
将下载的mmseg4j-core-1.10.0.jar、mmseg4j-solr-2.4.0.jar拷贝到solr的lib目录下,
如:G:\solr\server\solr-webapp\webapp\WEB-INF\lib
3.2 配置
修改managed-schema文件,新增:
<!-- mmseg4j-->
<fieldTypename="text_mmseg4j_complex" class="solr.TextField"positionIncrementGap="100" >
<analyzer>
<tokenizerclass="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory"mode="complex" dicPath="dic"/>
</analyzer>
</fieldType>
<fieldTypename="text_mmseg4j_maxword" class="solr.TextField"positionIncrementGap="100" >
<analyzer>
<tokenizerclass="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory"mode="max-word" dicPath="dic"/>
</analyzer>
</fieldType>
<fieldTypename="text_mmseg4j_simple" class="solr.TextField"positionIncrementGap="100" >
<analyzer>
<!--
<tokenizerclass="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory"mode="simple" dicPath="n:/OpenSource/apache-solr-1.3.0/example/solr/my_dic"/>
-->
<tokenizerclass="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory"mode="simple" dicPath="dic"/>
</analyzer>
</fieldType>
<!-- mmseg4j-->
再新增Field:
<!-- mmseg4j -->
<field name="mmseg4j_complex"type="text_mmseg4j_complex" indexed="true"stored="true"/>
<field name="mmseg4j_maxword"type="text_mmseg4j_maxword" indexed="true"stored="true"/>
<field name="mmseg4j_simple"type="text_mmseg4j_simple" indexed="true"stored="true"/>
<!--mmseg4j -->
说明:dicPath 用于自定义词库,mmseg4j的jar包里面已经包含,可以删除dicPath配置
3.3 测试
以上配置完成后,停止solr,并重启
Solr.cmd stop –all
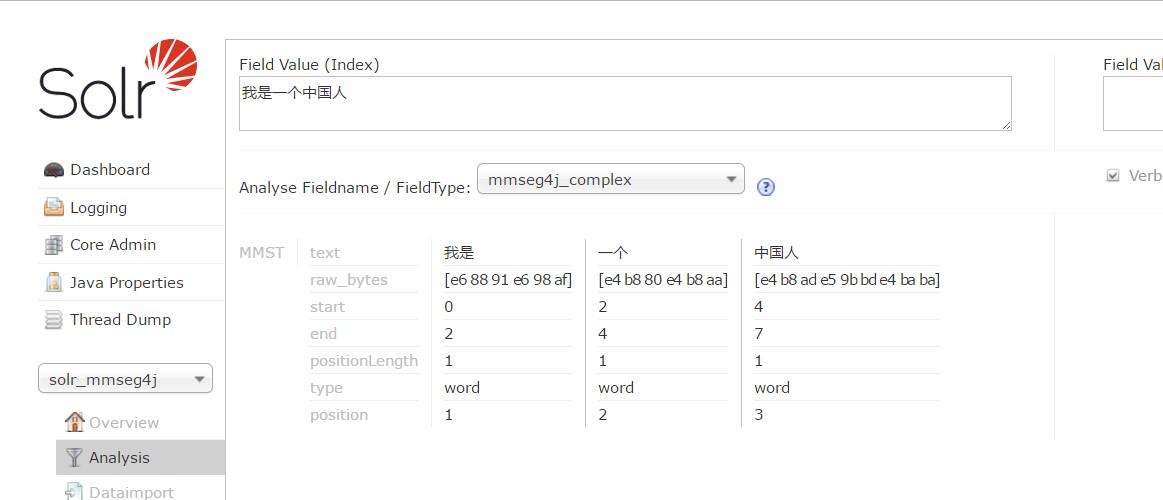
Solr.cmd start进入控制台Analysis,可以看到分词已经基本根据语意去分隔了,如下图:

















 151
151

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









