







摘要: mmseg4j支持用户自定义词库,这个配置过程相对简单,但是由于Solr6的API变动,使得mmseg4j无法使用自己的中文分词库,如果想使用这一功能,只能改源码了。
mmseg4j 版本与其对应的Solr版本
mmseg4j 1.8.3 只支持 lucene 2.9/3.0 接口 和 solr 1.4。
mmseg4j 1.8.5 支持 lucene 3.1, solr 3.1。
mmseg4j 1.9.0 支持 lucene 4.0, solr 4.0。
mmseg4j 1.9.1 支持 solr/lucene 4.3.1。
mmseg4j-solr-2.0.0.jar 要求 lucene/solr >= 4.3.0。
mmseg4j-solr-2.1.0.jar 要求 lucene/solr 4.8.x。
mmseg4j-solr-2.2.0.jar 要求 lucene/solr [4.9, 4.10.x]。
mmseg4j-solr-2.3.0.jar 要求 lucene/solr [5.0, ]
mmseg4j 作者chenlb目前仅支持最高Solr5
配置mmseg4j 词库
上一篇[Solr6配置中文分词],已经简单配置了mmseg4j分词,当时去掉了dicPath参数,该参数指定了自定义词库的路径,默认相对于solr_home,也可以是绝对路径。下面我在solr_home中新建文件夹dictionary,并在schema.xml中配置。
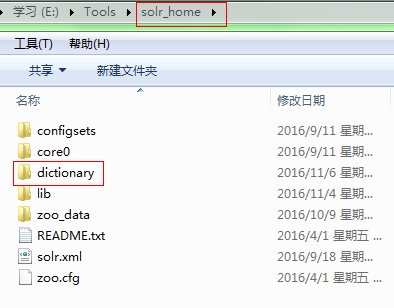

自定义词库文件
mmseg4j的自定义词库文件命名规则是
wordsXXX.dic, mmseg4j 可以从多个文件读取词。它的格式是一行一条数据, XXX 部分是如您自己写的名字,如:源码包里的 data/words-my.dic。注意:自定义词库文件名必需是 “words” 为前缀和 “.dic” 为后缀。并且文件是UTF-8编码的无BOM格式。
在dictionary文件夹下,新建文件words-mmseg4j.dic,然后每行一条记录,添加你的自定义词组。
保存文件,在windows平台下,默认使用的是ASCI编码方式,需要转化成UTF-8编码,使用Notepad++可以方便做到,选择以UTF-8无BOM格式编码,保存。
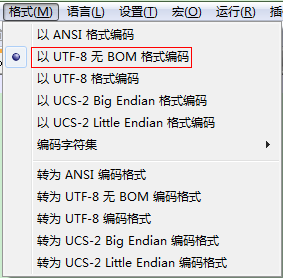
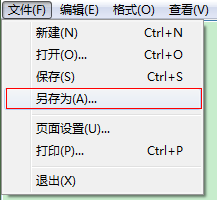
如果没有这个软件,可以用记事本的另存为功能,选择编码方式为UTF-8,那如何做到无BOM格式呢?最简单的方式就是文件的第一行留空,从第二行开始添加你的自定义词组。

升级mmseg4j
启动Solr,发现出现异常,好像是mmseg4j词库的工具栏报错:java.lang.NoSuchMethodError: org.apache.solr.core.SolrResourceLoader.getInstanceDir()Ljava/lang/String;
at com.chenlb.mmseg4j.solr.Utils.getDict(Utils.java:18)
于是,想办法升级mmseg4j,使其支持Solr6

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











