







--------------------------------------------------------------------------------------------------------------------------------------------
在全面介绍Storm之前,我们先通过一个简单的Demo让大家整体感受一下什么是Storm。
Storm运行模式:
- 本地模式(Local Mode): 即Topology(相当于一个任务,后续会详细讲解) 运行在本地机器的单一JVM上,这个模式主要用来开发、调试。
- 远程模式(Remote Mode):在这个模式,我们把我们的Topology提交到集群,在这个模式中,Storm的所有组件都是线程安全的,因为它们都会运行在不同的Jvm或物理机器上,这个模式就是正式的生产模式。
写一个HelloWord Storm
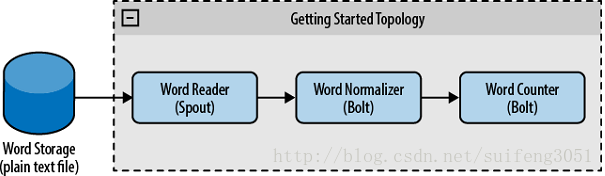
我们现在创建这么一个应用,统计文本文件中的单词个数,详细学习过Hadoop的朋友都应该写过。那么我们需要具体创建这样一个Topology,用一个spout负责读取文本文件,用第一个bolt来解析成单词,用第二个bolt来对解析出的单词计数,整体结构如图所示:
可以从这里下载源码:http://download.csdn.net/detail/xunzaosiyecao/9818483
写一个可运行的Demo很简单,我们只需要三步:
- 创建一个Spout读取数据
- 创建bolt处理数据
- 创建一个Topology提交到集群
下面我们就写一下,以下代码拷贝到eclipse(依赖的jar包到官网下载即可)即可运行。
1.创建一个Spout作为数据源
Spout作为数据源,它实现了IRichSpout接口,功能是读取一个文本文件并把它的每一行内容发送给bolt。
package storm.demo.spout;
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.util.Map;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichSpout;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
public class WordReader implements IRichSpout {
private static final long serialVersionUID = 1L;
private SpoutOutputCollector collector;
private FileReader fileReader;
private boolean completed = false;
public boolean isDistributed() {
return false;
}
/**
* 这是第一个方法,里面接收了三个参数,第一个是创建Topology时的配置,
* 第二个是所有的Topology数据,第三个是用来把Spout的数据发射给bolt
* **/
@Override
public void open(Map conf, TopologyContext context,
SpoutOutputCollector collector) {
try {
//获取创建Topology时指定的要读取的文件路径
this.fileReader = new FileReader(conf.get("wordsFile").toString());
} catch (FileNotFoundException e) {
throw new RuntimeException("Error reading file ["
+ conf.get("wordFile") + "]");
}
//初始化发射器
this.collector = collector;
}
/**
* 这是Spout最主要的方法,在这里我们读取文本文件,并把它的每一行发射出去(给bolt)
* 这个方法会不断被调用,为了降低它对CPU的消耗,当任务完成时让它sleep一下
* **/
@Override
public void nextTuple() {
if (completed) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// Do nothing
}
return;
}
String str;
// Open the reader
BufferedReader reader = new BufferedReader(fileReader);
try {
// Read all lines
while ((str = reader.readLine()) != null) {
/**
* 发射每一行,Values是一个ArrayList的实现
*/
this.collector.emit(new Values(str), str);
}
} catch (Exception e) {
throw new RuntimeException("Error reading tuple", e);
} finally {
completed = true;
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("line"));
}
@Override
public void close() {
// TODO Auto-generated method stub
}
@Override
public void activate() {
// TODO Auto-generated method stub
}
@Override
public void deactivate() {
// TODO Auto-generated method stub
}
@Override
public void ack(Object msgId) {
System.out.println("OK:" + msgId);
}
@Override
public void fail(Object msgId) {
System.out.println("FAIL:" + msgId);
}
@Override
public Map<String, Object> getComponentConfiguration() {
// TODO Auto-generated method stub
return null;
}
}
2.创建两个bolt来处理Spout发射出的数据
Spout已经成功读取文件并把每一行作为一个tuple(在Storm数据以tuple的形式传递)发射过来,我们这里需要创建两个bolt分别来负责解析每一行和对单词计数。
Bolt中最重要的是execute方法,每当一个tuple传过来时它便会被调用。
第一个bolt:WordNormalizer
package storm.demo.bolt;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
public class WordNormalizer implements IRichBolt {
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.collector = collector;
}
/**这是bolt中最重要的方法,每当接收到一个tuple时,此方法便被调用
* 这个方法的作用就是把文本文件中的每一行切分成一个个单词,并把这些单词发射出去(给下一个bolt处理)
* **/
@Override
public void execute(Tuple input) {
String sentence = input.getString(0);
String[] words = sentence.split(" ");
for (String word : words) {
word = word.trim();
if (!word.isEmpty()) {
word = word.toLowerCase();
// Emit the word
List a = new ArrayList();
a.add(input);
collector.emit(a, new Values(word));
}
}
//确认成功处理一个tuple
collector.ack(input);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
@Override
public void cleanup() {
// TODO Auto-generated method stub
}
@Override
public Map<String, Object> getComponentConfiguration() {
// TODO Auto-generated method stub
return null;
}
} package storm.demo.bolt;
import java.util.HashMap;
import java.util.Map;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class WordCounter implements IRichBolt {
Integer id;
String name;
Map<String, Integer> counters;
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.counters = new HashMap<String, Integer>();
this.collector = collector;
this.name = context.getThisComponentId();
this.id = context.getThisTaskId();
}
@Override
public void execute(Tuple input) {
String str = input.getString(0);
if (!counters.containsKey(str)) {
counters.put(str, 1);
} else {
Integer c = counters.get(str) + 1;
counters.put(str, c);
}
// 确认成功处理一个tuple
collector.ack(input);
}
/**
* Topology执行完毕的清理工作,比如关闭连接、释放资源等操作都会写在这里
* 因为这只是个Demo,我们用它来打印我们的计数器
* */
@Override
public void cleanup() {
System.out.println("-- Word Counter [" + name + "-" + id + "] --");
for (Map.Entry<String, Integer> entry : counters.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
counters.clear();
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// TODO Auto-generated method stub
}
@Override
public Map<String, Object> getComponentConfiguration() {
// TODO Auto-generated method stub
return null;
}
}
3.在main函数中创建一个Topology
在这里我们要创建一个Topology和一个LocalCluster对象,还有一个Config对象做一些配置。
package storm.demo;
import storm.demo.bolt.WordCounter;
import storm.demo.bolt.WordNormalizer;
import storm.demo.spout.WordReader;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.tuple.Fields;
public class WordCountTopologyMain {
public static void main(String[] args) throws InterruptedException {
//定义一个Topology
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("word-reader",new WordReader());
builder.setBolt("word-normalizer", new WordNormalizer())
.shuffleGrouping("word-reader");
builder.setBolt("word-counter", new WordCounter(),2)
.fieldsGrouping("word-normalizer", new Fields("word"));
//配置
Config conf = new Config();
conf.put("wordsFile", "d:/text.txt");
conf.setDebug(false);
//提交Topology
conf.put(Config.TOPOLOGY_MAX_SPOUT_PENDING, 1);
//创建一个本地模式cluster
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("Getting-Started-Toplogie", conf,
builder.createTopology());
Thread.sleep(1000);
cluster.shutdown();
}
}
运行这个函数我们即可看到后台打印出来的单词个数。(ps:因为是Local模式,运行开始可能会打印很多错误log,这个先不用管)

---------------------------------------------------------------------------------------------------------------------------------------------
折线之间的内容整理自:http://blog.csdn.net/suifeng3051/article/details/38369689
以上是Storm的上手例子,那么JStorm 应该如何写呢?
我们用的是JStorm,但上面的可以不修改一行就可以在JStorm上跑起来。
<!-- Storm Dependency -->
<!-- <dependency>
<groupId>storm</groupId>
<artifactId>storm</artifactId>
<version>0.7.1</version>
</dependency>-->
<!-- JStorm Dependency -->
<dependency>
<groupId>com.alibaba.jstorm</groupId>
<artifactId>jstorm-core</artifactId>
<version>2.1.1</version>
</dependency>小注:
如果不清楚如何使读取config下word.txt,可以修改TopologyMain类,将其中的
//conf.put("wordsFile", args[0]);
//在conf添加路径wordsFile的时候,可以将路径写死,弄成一个固定值
//比如:我这里将word.txt放到了/usr/local/jstorm-2.2.1/wait_deploy/路径下
conf.put("wordsFile", "/usr/local/jstorm-2.2.1/wait_deploy/word.txt");# 打包时跳过测试
mvn clean package -Dmaven.test.skip=true
例如我这里打包文件名为:Getting-Started-0.0.1-SNAPSHOT.jar,提交命令:
//提交jar
//jar包名称:Getting-Started-0.0.1-SNAPSHOT.jar
//入口类:TopologyMain
//入口类需要参数的话,需要在入口类后面添加需要的参数
jstorm jar Getting-Started-0.0.1-SNAPSHOT.jar TopologyMain
jstorm jar xxxxxx.jar com.alibaba.xxxx.xx parameter- xxxx.jar 为打包后的jar
- com.alibaba.xxxx.xx 为入口类,即提交任务的类
- parameter即为提交参数
demo中部分函数及参数注释:
setBolt方法中的参数parallelism_hint代表这样一个Spout或Bolt有多少个实例,即对应多少个线程,一个实例对应一个线程。
注意理解spout及bolt:
spout:自定义获取待处理流的地方
bolt:自定义处理流的地方

JStorm的安装可以参考官网:https://github.com/alibaba/jstorm/wiki/JStorm-Chinese-Documentation
下午写JStorm的demo花了一下午的时间,主要原因是:知道storm代码不需要修改就能跑在jstorm上,但上网搜资料的还是搜索jstorm的案例,但网上大部分jstrom的demo都是跑不起来的,或者需要自己升级版本的。jstorm官网的Example,拉到本地后,也是各种报错。
要写jstorm的代码,搜索storm,参考storm部分即可。
作者:jiankunking 出处:http://blog.csdn.net/jiankunking

















 1736
1736

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









