







1、基本思想
堆是一种特殊的树形数据结构,其每个节点都有一个值,通常提到的堆都是指一颗完全二叉树,根结点的值小于(或大于)两个子节点的值,同时,根节点的两个子树也分别是一个堆。
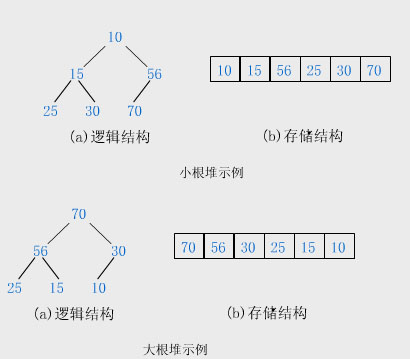
堆排序就是利用堆(假设利用大顶堆)进行排序的方法。它的基本思想是,将待排序的序列构造成一个大顶堆。此时,整个序列的最大值就是堆顶的根节点。将它移走(其实就是将其与堆数组的末尾元素交换,此时末尾元素就是最大值),然后将剩余的 n-1 个序列重新构造成一个堆,这样就会得到 n 个元素中次大的值。如此反复执行,便能得到一个有序序列了。
堆排序的实现需要解决的两个关键问题:
(1)将一个无序序列构成一个堆。
(2)输出堆顶元素后,调整剩余元素成为一个新堆。
2、复杂度分析
堆排序的运行时间主要耗费在初始构建堆和在重建堆时反复筛选上。在构建对的过程中,因为我们是完全二叉树从最下层最右边的非终端节点开始构建,将它与其孩子进行比较和若有必要的互换,对每个非终端节点来说,其实最多进行两次比较和互换操作,因此整个构建堆的时间复杂度为O(n)。
在正式排序时,第i次取堆顶记录重建堆需要用O(logi)的时间(完全二叉树的某个节点到根节点的距离为
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1227
1227

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









