







前言
大数据以及人工智能越来越火,作为一线攻城狮的我们有必要了解和研究,写本博客的目的在于分享以及自己记录总结,如有不美观之处请谅解,在后面的所有博客中,我们均采用python来进行代码编写,我们的思想是按照面向函数式思想来考虑问题,有时会更好理解一些代码中的函数。 #k近邻简介
k邻近算法是属于监督学习分类算法中比较简单的一种,网上和书上也说它是一种基于实例的学习方法,也就是它是基于已有的分类样本数据来预测未知的数据,它常常用于数据分类。
原理
它不需要花很长时间去训练分类过程,只要给定已知样本数据集后,当有一个新的测试样本输入,我们会通过计算出输入的待分类样本和已知数据集各个样本之间的特征距离,然后,根据距离从小到大排序,选取距离最近的k个样本,计算这k个样本中分类最多的那一类,找出来之后我们即把输入的样本归为这一类,看下面一张图帮助理解:
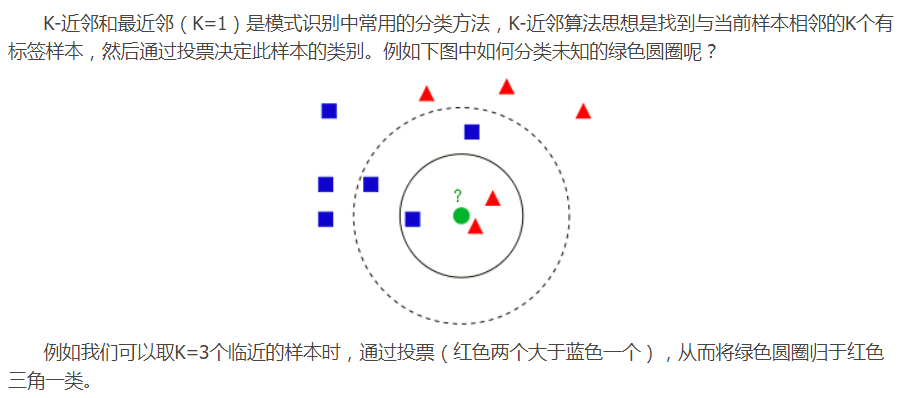
从原理上来看该算法并不复杂,理解起来也相对简单些,对于每一个算法或是其它理论方法我们应该有这样一个共识,它们都有自己的局限性和优势劣势,我们要做的是找到最有解法来适应最合适的应用场景。
概念解析
每篇博客我们都来接触几个概念,对于每个新事物概念是相当重要的部分,对于每个概念知道它的意义所在,产生这个概念的本质是源于什么目的,深刻理解后才能熟练应用,如同剑客的三个层次,手中无剑心中无剑,感觉英文解释也不错,有时翻译过来可能不太准确,如下:
- 训练集(Training set): A set of examples used for learning, which is to fit the parameters [i.e., weights] of the classifier.
- 验证集(Validation set): A set of examples used to tune the parameters [i.e., architecture, not weights] of a classifier, for example to choose the number of hidden units in a neural network.
- 测试集(Test set): A set of examples used only to assess the performance [generalization] of a fully specified classifier.
- 近似误差(approximation):网上有很多解析,感觉有一种比较好理解,可以先这样理解,近似误差是相对于训练集,表示预测结果与每个样本真实值的差异大小,当k值过小时,局部性增大过度耦合问题出现,同每个真实样本之间的比较近,则近似误差变小。
- 估计误差(estimation error):同理,估计误差相对于测试集,k小,训练模型复杂,预测测试数据时会偏离真实值较大,因此近似误差间变大,相反k值变大,近似误差减小。
步骤
- 1.得到已知样本集合和分类标签
- 2.计算已知类别数据集中的点与当前点之间的距离
- 3.按照距离递增排序
- 4.选取与当前点距离最小的k个点
- 5.计算k个点中出现类别最高的点,并返回该类别,作为待测点的分类 计算距离 计算出现最高的频路
问题
1.k值得选取
从原理中我们可以看出,k的取值范围是从1-n,n代表样本个数,那我们先从两个极端来分析一下k值 k=1时 k=1的意思即我们只查找距离输入样本距离最近的一个已知样本,它的分类即输入样本的分类,完全或过度依赖于最近的一个实例样本,在现实生活中如果对我们自己进行分类,我身边的朋友是已知分类样本,如果只根据我的一个朋友即把自己分为他那一类感觉是不是有些草率,分类过度依赖于一个人了,这种现象叫做过拟合 k=n 即每次输入待测样本预测时,都把所有已知的样本作为依据来分类,即把所有分类都考虑进去了,把原本离待测样本分类距离较远的也一起计算,且每次分类都是已知样本中分类多的占优势,近似误差增加,估计误差减小 。
2.距离计算方式
计算样本特征之间距离的方式有好几种,常用的有三种分别为 曼哈顿距离、欧氏距离、闵可夫斯基距离,这里我们采用了欧氏距离来计算特征之间的距离计算,有兴趣的可以自行研究。
代码示例
下面我们按着该算法的思路实现一个简单的例子来,该例子是已经一个数据集合,来判断新来的数据可能属于哪一个类别,代码写的注释比较多,大家可以通过看注释看懂啥叫意思,代码如下:
def createDataSet():
'''
创建训练集以及对应的分类标签
:return: 返回集合和分类标签
'''
group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return group, labels
def classify0(intX,dataSet,labels,k):
'''
k均值算法分类器简单实现
:param intX: 输入待测样本
:param dataSet: 训练集合
:param labels: 已知分类标签
:param k: 最近的k个样本点
:return: 返回待测样本点的分类结果
'''
# 获取已知样本行数
dataSetSize = dataSet.shape[0]
# tile 表示重复A 输出,计算intX 与每个样本的差值
diffMat = tile(intX,(dataSetSize,1)) - dataSet
# 每个值取平方
sqDiffMat = diffMat**2
print "sqDiffMat = %s" % sqDiffMat
# 欧式距离 axis=1 行之和,0 列之和
sqDistances = sqDiffMat.sum(axis=1)
print "sqDistances = %s" % sqDistances
# 开平方
distances = sqDistances**0.5
# 返回从小到大的索引值
sortedDistIndieies = distances.argsort()
classCount = {}
# 取最近的k个样本点
for i in range(k):
voteIlabel = labels[sortedDistIndieies[i]]
# 用字典保存最近样本点的次数
classCount[voteIlabel] = classCount.get(voteIlabel,0)+1
sortedClassCount = sorted(classCount.iteritems(),key=operator.itemgetter(1),reverse=True)
# 返回出现最高的那一个分类
print sortedClassCount[0][0]
if '__main__==__name__':
dataSet,labels = createDataSet()
# print dataSet
# print labels
classify0([0,0],dataSet,labels,3)总结
k均值学习算法作为第一个机器入门级学习算法,该算法的缺点在于时间和空间复杂度都很高,不过很好的帮我们认识了机器学习的过程,感觉在学习机器学习时的困难在于多理解各种概念,弄懂他们的意思和表达的含义,找到一个适合自己的思路去学习才会事半功倍,学习一个东西往往需要从多角度去考察、去学习其实这种思想在我们生活中无处不在,如通过前几天天气预测后面天气、基于每个人的现在情况预测一个人的未来,各种在已有条件发生的案例都可以使用该方法来预测,多观察生活多学习会让自己认识提高。
题外思考
悖论的意义
以前并不知道悖论的意义在哪里,完全是一些不着边际的遐想,在了解了它的意义之后会觉得它是有很大价值的想法,先拿一个例子说来叫”龟速赛跑“,但结论是兔子追不上乌龟。
这样的结论是不是不符合常理,它的逻辑是这样的假设乌龟在兔子前面100米,兔子速度是乌龟10倍,然后他们开始出发,如果兔子想追上乌龟必须达到乌龟的起点,当兔子达到乌龟起点时,乌龟又向前运动了10米,依次类推,兔子永远都是达到乌龟起点,古永远追不上乌龟。类似的悖论还有射箭非动、永远走不到学校等例子,殊不知西方很多科学的进步来自于悖论启发,东方人经常认为这是庸人自扰因为它不符合尝试,没有从常识出发不值得反驳,我们的思维一直强调学以致用、不合理的不去触碰因此我们失去了发现新知的机会,以我们的经验去理解逻辑的问题,有时逻辑中的漏洞往往是科学的巨大发现。
举个物理方面的例子,伽利略发现物体下落和质量无关的结论即源于这样的逻辑推理,在这之前亚里士多德认为质量大的物体下落应该快,人们也一直这么认为,伽利略通过实现做了一个逻辑假设,有两个物体一个10kg,一个1kg,将两个物体绑在一起如果速度跟质量有关,下降速度应该结余10与1之间,与假设矛盾,使得伽利略发明了这一个现象。
















 2373
2373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











