







K-近邻算法(KNN)原理分析和代码实战
前言
K-近邻算法,全称为K-nearest neighbor,简称KNN。它是一个原理非常简单,但是计算复杂度比较高的一个分类算法,接下来,我们先从原理出发,再进行源代码的解析。
源代码地址:KNN
原理分析
通过计算输入数据与模型数据的欧几里得距离,选取前K个距离最短的模型数据,类型出现次数最多的就是输入数据所属的类型。
我们来看一下下面这个图(画的不好,大家多多担待)

上图中,黑色点为输入数据,棕色和红色数据均为模型数据,我们假设棕色数据属于1类,红色数据属于2类,假设K等于5.
步骤:
- 计算黑色数据与棕色数据和红色数据之间的距离(欧几里得距离)
- 找出与黑色数据距离最近的五个数据,如图中橘黄色线段
- 统计这五个数据所属的分类。图中这5个数据中,有3个是红色数据,属于2类,2个棕色数据,属于1类
- 选择数量最多的类别,即为输入数据的类别。图中5个数据中,红色数据个数大于棕色数据个数,所以,输入数据属于2类。
欧几里得距离公式:
二维
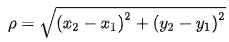
多维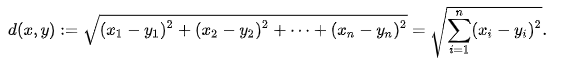
原理很简单,接下来咱们分析一下算法优缺点
优点:
- 原理简单,不涉及复杂的数据理论知识,只有一个欧几里得距离计算
- 对异常数据不敏感
- 精准度比较高
- 适用于数值型数据和标称型(就是取值有限,比如0、1或者是、否)数据
缺点:
- 计算量太大,每次输入数据,都需要与模型中所有数据进行欧几里得距离计算
- 占用的空间比较大。
源代码解析
项目背景:
此项目数据集使用得是《机器学习实战》一书提供得关于约会对象匹配得数据集,该数据集共有四列数据,前三列是数据的属性,分别是 行里程数、玩游戏时间占比、消耗冰淇淋公升数,最后一列是数据的归属类,数据一共分类3类,分别是1、2、3.
数据存储在txt文件中,不同属性的数据使用空格进行分割,下图是数据格式:

一、加载数据
import numpy as np
import operator
def loaddatasets(dataseturl,datatype='train'):
datasetLabel = []
datasetClass = []
with open(dataseturl) as f:
datas = f.readlines()
for data in datas:
dataline = data.strip().split('\t')
datasetLabel.append(dataline[:-1])
datasetClass.append(dataline[-1])
if(type=='train') 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4747
4747











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









