







这篇文章介绍的是机器学习在文本分类中的应用,文章一开始介绍的是文本分类的应用,随后提到了进行文本分类需要解决的几个问题,最后给出了机器学习中的几种分类方法应用文本分类的效果。
下面是一些要点:
1、文本分类的几种意思[简称TC]
-the automatic assignment of documents to a predefined set of categories(这篇论文的要点)
-the automatic identification of such a set of categories
-the automatic identification of such a set of categories and the grouping of documents under them
-any activity of placing text items into groups
2、定义
The task of assigning a boolean value to each pair <dj, ci> ∈D*C,D is a domain of documents and C={c1,..c|c|} is a set of predefined categories. 如果值为T,则表明文档属于该类别,否则就不属于该类别。正式来说,可以是定义一个函数, D*C->{T,F},这个函数就是一个分类器
3、单标签和多标签分类
由于每个文档可以划分为k个类别,单标签时k=1。不过从多个标签中寻找一个最合适的较为困难,并且也可能找不到类别。这里只需要解决二元问题即可,因为解决了二元分类问题就解决了多标签问题,问题转换为给定类别ci,分类器能判断D是否属于该类别。D->{T,F}
4、基于类别分类和基于文档分类
基于文档分类:给定文档dj,我们想找到所有dj可以属于的类别(DPC),适用于文档不是一下子同时出现,而是在不同时刻出现
基于类别分类:给定类别ci,我们想找到所有属于类别ci的文档(CPC),适用于添加新类别或者是文档需要重新分类的情况
5、类别排序TC和文档排序TC
类别排序TC:给定文档dj,按照相关性从大到小输出类别信息,可以让专家选择最终文档能够属于的类别
文档排序TC:给定类别ci,按照相关性从大到小输出文档信息
6、文本分类的应用
-automatic indexing for boolean information retrieval systems:信息检索,比如从文档中提取关键词,关键段落等
-document organization:对文档进行规整,例如报纸上消息
-text filtering:文本过滤,包含推荐系统,在文本产生端需要保存所有用户的个人信息以过滤出有用文本,但是在客户端只需要一个单一个人信息
-word sense disambiguation:单词消除歧义,可以把一个单词的所有意思看成是类别集合,然后可以用TC来判断在这段文字中这个单词最可能是什么意思
-hierarchical categorization of web pages:web页面的层次分类,对页面按类别进行层次划分
7、TC中的机器学习方法
最原始的方法就是制定一个规则来划分:
If <DNF formula> then <category>
这里的规则需要人工制定,而且需要是每个领域的专家,分类器等于是人工设定的。
如果使用ML,人工需要做的是创建一个自动设定分类器的系统(the learner),不再是分类器本身。
8、某个类别的通用性
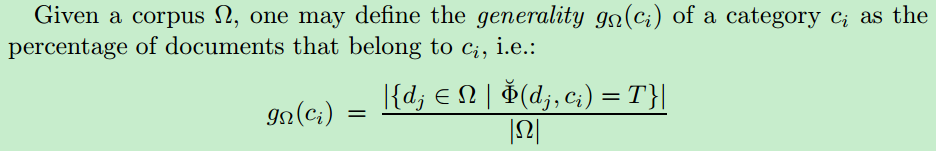
9、建立文档索引
一个文档dj通常由一个术语权重向量构成,dj=<w1j,w2j,...,wTj>. 其中T表示术语集合,wkj[0,1]表明术语tk对于文档dj的贡献程度(关键词肯定权重较高)。为了定义术语tk的权重wkj,我们采用最常见的tfidf函数,定义如下:
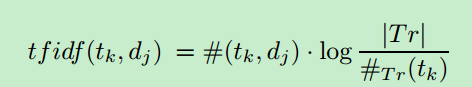
其中前面#一项表明tk在文档dj里面出现的次数,#Tr(tk)表示全部语料库中包含tk这个术语的文档个数,|Tr|即整个文档库的数目。这样求解能确保:一个术语在该文档中出现越多,其对于该文档的代表性越大;一个术语在越多的文档中出现,其代表性越差。为了让wkj落在[0,1]区间,需要对tfidf值进行单位化:
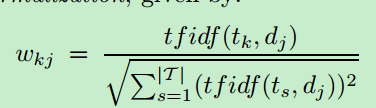
10、Darmstadt 文档索引
和上面的方法不同,DIA方法是使用一个指定单词表里面的术语,该方法能使用更大的特征集合来表示文档,其中包括以下几点:术语tk的属性;术语tk和文档dj之间的关系;文档dj的属性;类别cj的属性。
11、降维
对于一个较大的术语集合|T|,我们希望找到一个维度较小的集合|T’|<<|T|,这里有两种降维的范围选择:local DR-针对每个类别ci找到一个集合|Ti’|,该集合能确保在类别ci下正确分类;global DR-找到一个全局的集合|T’|,能够在全部的类别之下分类。降维方法也有两种:term selection-能够确保T’是T的子集;term extraction-T’中的术语不同于T,T’中的术语是通过在T的术语基础上组合变换得到的。下面具体介绍这两种方法。
Term-selection:确保|T’|中选择的都是文本分类中最重要的那些术语,这个重要性可以由之前的wkj值来判断,如果仅仅按照某个术语出现频率进行选择会发生错误,根据统计,出现次数低到中等的术语往往包含较多的信息。
Term-extraction:从原始集合T中产生出一个集合T’,让效率最大化。其中可以使用术语聚类,找到每个类别具有代表性的单词(word2vec做到了);或者是使用SVD的方法对数据进行压缩,但是这样得到的结果往往不可解读。
12、文档分类
在分类时有两种分类方法,一种是硬(全自动)分类,一种是软(半自动)分类。对于硬分类,我们构造的函数针对每个类别需要判断D->{T,F},而软分类需要判断D->[0,1]。可以设定一个阈值来判断文档是否属于该类别。下面介绍各个分类方法:
-贝叶斯分类:P(ci|dj)表示以向量形式表示的文档dj=<w1j,...w|T|j>属于类别ci的概率,可以转换为:
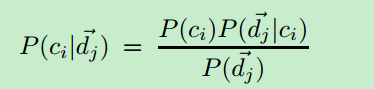
其中P(dj)表示随机选择一个文档具有向量dj形式的概率,P(ci)表示随机选择的文档属于ci的概率。使用朴素贝叶斯思想:
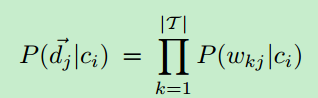
又可以写成:
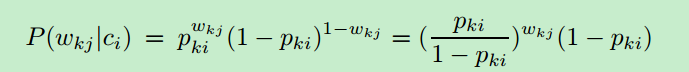
其中Pki代表P(wkx=1|ci),也就是类别ci中wkx为1的概率。
-在线分类:这种方法在检查第一个训练样本后立刻建立一个分类器,该分类器在后续的样本检测中不断变化,这一点类似于神经网络中权重的调节
-Rocchio方法:该方法为类别ci求得一个分类器ci=<w1i,...w|T|i>

Wkj是tk在文档dj中的权重,POSi代表属于ci类别的文档dj的个数,NEGi代表不属于类别ci文档的个数,前面两个系数为可控变量,进一步修改为:
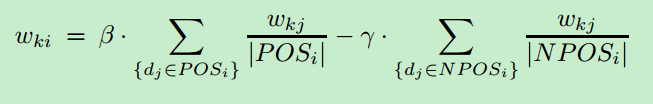
其中NPOSi代表靠近正样本的数据点,这里只选择这些样本点作为负样本,因为这些样本点是分类器最难区分。
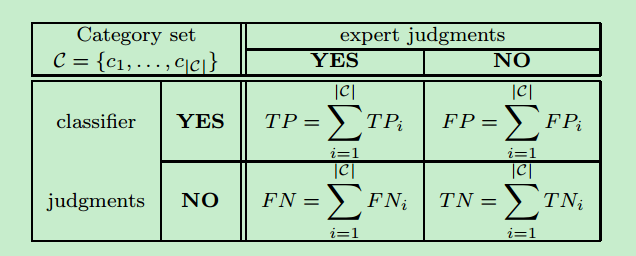
13、衡量分类器的准确率
衡量好坏一般采用precision和recall两个值:
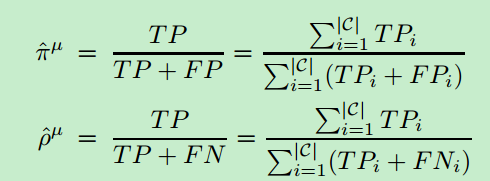
其中TPi ,FNi的含义如下:















 295
295

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









