






1. 什么是决策树/判定树(decision tree)?
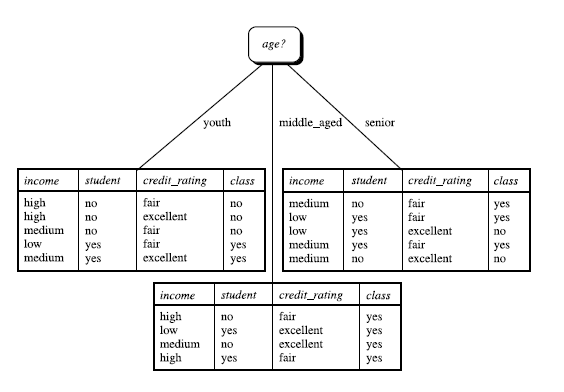

判定树是一个类似于流程图的树结构:其中,每个内部结点表示在一个属性上的测试,每个分支代表一个属性输出,而每个树叶结点代表类或类分布。树的最顶层是根结点。当一个属性被使用后就不能再次在下面使用。
如上图所示,当age出现时,下面将不会在出现。
下面给出数据表现形式:
相关的理论部分请观看教材
下面展示代码:
from sklearn.feature_extraction import DictVectorizer
import csv
from sklearn import tree
from sklearn import preprocessing
from sklearn.externals.six import StringIO
# Read in the csv file and put features into list of dict and list of class label
allElectronicsData = open(r'/home/zhoumiao/MachineLearning/01decisiontree/AllElectronics.csv', 'rb')
reader = csv.reader(allElectronicsData)
headers = reader.next()
print(headers)
# featureList存放特征属性,转换成多维:举例子“身高属性”的取值“高”“矮”{1.0,0.0},
# 若没有序关系,假定有k个属性值,则通常转化成k维向量,
# 例如属性”瓜类“的取值“西瓜”“南瓜”“黄瓜”可转化为(0,0,1)(0,1,0)(1,0,0)。
featureList = []
# labelList存放标签属性
labelList = []
for row in reader:
# 读入标签
labelList.append(row[len(row)-1])
# 添加字典,将属性添加到字典中
rowDict = {}
for i in range(1, len(row)-1):
rowDict[headers[i]] = row[i]
# 将字典存放到特征属性当中
featureList.append(rowDict)
print(featureList)
# Vetorize features
vec = DictVectorizer()
# python的模块,将字典转换成上面的属性形式
dummyX = vec.fit_transform(featureList) .toarray()
print("dummyX: " + str(dummyX))
print(vec.get_feature_names())
print("labelList: " + str(labelList))
# vectorize class labels
lb = preprocessing.LabelBinarizer()
dummyY = lb.fit_transform(labelList)
print("dummyY: " + str(dummyY))
# Using decision tree for classification
# clf = tree.DecisionTreeClassifier()
# sklearn的决策树使用
clf = tree.DecisionTreeClassifier(criterion='entropy')
clf = clf.fit(dummyX, dummyY)
print("clf: " + str(clf))
# Visualize model
# 运用graphviz将决策树写到文档中
with open("allElectronicInformationGainOri.dot", 'w') as f:
f = tree.export_graphviz(clf, feature_names=vec.get_feature_names(), out_file=f)
# 去除第一行
oneRowX = dummyX[0, :]
print("oneRowX: " + str(oneRowX))
# 修改第一行的数据,然后进行预测
newRowX = oneRowX
newRowX[0] = 1
newRowX[2] = 0
print("newRowX: " + str(newRowX))
predictedY = clf.predict(newRowX)
print("predictedY: " + str(predictedY))















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









