







图像转置的Neon优化代码
原理
图像转置
图像转置和矩阵转置是一样的,其公式为:
dst.getPixels(y, x) = src.getPixels(x, y)
dst.w = src.h
dst.h = src.w效果如下:
原图:

结果图:

先做图像转置后,再实现90度/270度的旋转相对容易,
如图像旋转90度,就只需要再水平翻转一下:
旋转结果图:

分而治之
图像转置的优化思路是:
1、将图像分割成一系列小矩阵。
分成的小矩阵当然是越大越好,但在矩阵变大时,汇编代码的复杂度变高,且寄存器如果使用完了也非常难处理,这里选的是4X4的矩阵。
2、每个小矩阵的宏观位置转置。
3、实现每个小矩阵的内部转置。
必须把矩阵图和寄存器向量的关系图画清,然后推演一番。
Neon指令vtrn是解决转置问题的核心。
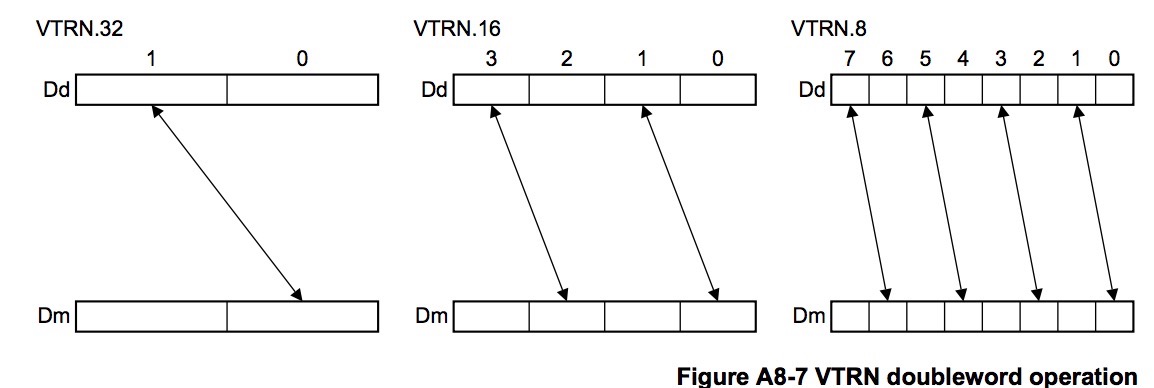
4、边角处理
写惯了基于一行的Neon优化,到这步很容易犯错,一定要记得这里是二维的Neon优化,边角料是两条边。

代码
该代码仅适用于32位(RGBA)图像的转置。
static void _transpose(unsigned char* dest_s, unsigned char* source_s, int dstw, int srcw, int dw, int dh)
{
int ista=0,jsta=0;
const int bpp = 4;//RGBA
#ifdef HAS_NEON
/*矩阵转置示意图
d1 d2
x00 x01 x02 x03
d3 d4
x10 x11 x12 x13
d5 d6
x20 x21 x22 x23
d7 d8
x30 x31 x32 x33
_||_
\ /
\/
d1 d2
x00 x10 x20 x30
d3 d4
x01 x11 x21 x31
d5 d6
x02 x12 x22 x32
d7 d8
x03 x13 x23 x33
*/
const int unit = 4;//必须是4
//GPCLOCK;
int nw = dw/unit;
int nh = dh/unit;
int srcstride = srcw*bpp;
int dststride = dstw*bpp;
if (nw > 1 && nh > 1)
{
asm (
"mov r5, #4\t\n"
"mul r8, %[srcstride], r5\t\n"
"mul r9, %[dststride], r5\t\n"
"mul r10, r5, r5\t\n"//In fact, it's 4*r5
"movs r5, %[nh]\t\n"//i
"sub r5, r5, #1\t\n"
"1:\t\n"
"sub r4, %[nw], #1\t\n"//j
"2:\t\n"
"mla r6, r4, r8, %[source_s]\t\n"
"mla r6, r5, r10, r6\t\n"
"vld1.32 {d1, d2}, [r6]\t\n"
"add r6, r6, %[srcstride]\t\n"
"vld1.32 {d3, d4}, [r6]\t\n"
"add r6, r6, %[srcstride]\t\n"
"vld1.32 {d5, d6}, [r6]\t\n"
"add r6, r6, %[srcstride]\t\n"
"vld1.32 {d7, d8}, [r6]\t\n"
/*Transpose internal*/
"vtrn.32 d1, d3\t\n"
"vtrn.32 d2, d4\t\n"
"vtrn.32 d5, d7\t\n"
"vtrn.32 d6, d8\t\n"
"vswp d2, d5\t\n"
"vswp d4, d7\t\n"
"mla r7, r5, r9, %[dest_s]\t\n"
"mla r7, r4, r10, r7\t\n"
"vst1.32 {d1, d2}, [r7]\t\n"
"add r7, r7, %[dststride]\t\n"
"vst1.32 {d3, d4}, [r7]\t\n"
"add r7, r7, %[dststride]\t\n"
"vst1.32 {d5, d6}, [r7]\t\n"
"add r7, r7, %[dststride]\t\n"
"vst1.32 {d7, d8}, [r7]\t\n"
"subs r4, r4, #1\t\n"
"bne 2b\t\n"//Loop1
"mla r6, r4, r8, %[source_s]\t\n"
"mla r6, r5, r10, r6\t\n"
"vld1.32 {d1, d2}, [r6]\t\n"
"add r6, r6, %[srcstride]\t\n"
"vld1.32 {d3, d4}, [r6]\t\n"
"add r6, r6, %[srcstride]\t\n"
"vld1.32 {d5, d6}, [r6]\t\n"
"add r6, r6, %[srcstride]\t\n"
"vld1.32 {d7, d8}, [r6]\t\n"
/*Transpose internal*/
"vtrn.32 d1, d3\t\n"
"vtrn.32 d2, d4\t\n"
"vtrn.32 d5, d7\t\n"
"vtrn.32 d6, d8\t\n"
"vswp d2, d5\t\n"
"vswp d4, d7\t\n"
"mla r7, r5, r9, %[dest_s]\t\n"
"mla r7, r4, r10, r7\t\n"
"vst1.32 {d1, d2}, [r7]\t\n"
"add r7, r7, %[dststride]\t\n"
"vst1.32 {d3, d4}, [r7]\t\n"
"add r7, r7, %[dststride]\t\n"
"vst1.32 {d5, d6}, [r7]\t\n"
"add r7, r7, %[dststride]\t\n"
"vst1.32 {d7, d8}, [r7]\t\n"
"subs r5, r5, #1\t\n"
"bne 1b\t\n"//Loop2
/*Last line*/
"sub r4, %[nw], #1\t\n"//j
"4:\t\n"
"mla r6, r4, r8, %[source_s]\t\n"
"mla r6, r5, r10, r6\t\n"
"vld1.32 {d1, d2}, [r6]\t\n"
"add r6, r6, %[srcstride]\t\n"
"vld1.32 {d3, d4}, [r6]\t\n"
"add r6, r6, %[srcstride]\t\n"
"vld1.32 {d5, d6}, [r6]\t\n"
"add r6, r6, %[srcstride]\t\n"
"vld1.32 {d7, d8}, [r6]\t\n"
/*Transpose internal*/
"vtrn.32 d1, d3\t\n"
"vtrn.32 d2, d4\t\n"
"vtrn.32 d5, d7\t\n"
"vtrn.32 d6, d8\t\n"
"vswp d2, d5\t\n"
"vswp d4, d7\t\n"
"mla r7, r5, r9, %[dest_s]\t\n"
"mla r7, r4, r10, r7\t\n"
"vst1.32 {d1, d2}, [r7]\t\n"
"add r7, r7, %[dststride]\t\n"
"vst1.32 {d3, d4}, [r7]\t\n"
"add r7, r7, %[dststride]\t\n"
"vst1.32 {d5, d6}, [r7]\t\n"
"add r7, r7, %[dststride]\t\n"
"vst1.32 {d7, d8}, [r7]\t\n"
"subs r4, r4, #1\t\n"
"bne 4b\t\n"//Loop1
"mla r6, r4, r8, %[source_s]\t\n"
"mla r6, r5, r10, r6\t\n"
"vld1.32 {d1, d2}, [r6]\t\n"
"add r6, r6, %[srcstride]\t\n"
"vld1.32 {d3, d4}, [r6]\t\n"
"add r6, r6, %[srcstride]\t\n"
"vld1.32 {d5, d6}, [r6]\t\n"
"add r6, r6, %[srcstride]\t\n"
"vld1.32 {d7, d8}, [r6]\t\n"
/*Transpose internal*/
"vtrn.32 d1, d3\t\n"
"vtrn.32 d2, d4\t\n"
"vtrn.32 d5, d7\t\n"
"vtrn.32 d6, d8\t\n"
"vswp d2, d5\t\n"
"vswp d4, d7\t\n"
"mla r7, r5, r9, %[dest_s]\t\n"
"mla r7, r4, r10, r7\t\n"
"vst1.32 {d1, d2}, [r7]\t\n"
"add r7, r7, %[dststride]\t\n"
"vst1.32 {d3, d4}, [r7]\t\n"
"add r7, r7, %[dststride]\t\n"
"vst1.32 {d5, d6}, [r7]\t\n"
"add r7, r7, %[dststride]\t\n"
"vst1.32 {d7, d8}, [r7]\t\n"
"5:\t\n"
: [srcstride] "+r" (srcstride), [dststride] "+r" (dststride), [source_s] "+r" (source_s), [dest_s] "+r" (dest_s), [nw] "+r" (nw), [nh] "+r" (nh)
:
: "r4", "r5", "r6", "r7", "r8", "r9","r10", "cc","memory", "d1", "d2", "d3", "d4", "d5", "d6", "d7", "d8"
);
}
ista = nh*unit;
jsta = nw*unit;
#endif
//边角处理,先处理图像下边缘,再处理图像右边缘
for (int i=ista; i<dh; ++i)
{
for (int j=0; j<dw; ++j)
{
unsigned char* dest = dest_s + (i*dstw+j)*bpp;
unsigned char* source = source_s + (j*srcw+i)*bpp;
::memcpy(dest, source, bpp*sizeof(unsigned char));
}
}
for (int i=0; i<ista; ++i)
{
for (int j=jsta; j<dw; ++j)
{
unsigned char* dest = dest_s + (i*dstw+j)*bpp;
unsigned char* source = source_s + (j*srcw+i)*bpp;
::memcpy(dest, source, bpp*sizeof(unsigned char));
}
}
}加速比率
大约10倍左右性能提升,数据遗失,不补。

















 450
450

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









