







ARM纯汇编开发
注:这篇文章是两年前写的,现在更新到CSDN。当时认知不足,其中可能有不少错误,敬请行家指正。
为什么要用纯汇编
开发效率高
这里可能让很多人大跌眼镜了,纯汇编开发效率高?
首先,这个是有限定条件的,需要反复调优的重度运算场景(比如卷积),纯汇编开发效率最高。
其次,这里的纯汇编并不是整个代码用汇编写,是指的将足够重的函数提取出来,用纯汇编实现。
参数试验
为什么呢,在用C开发时,受到toolchtain制约,我们会花费很多的时间在试验编译器上(往往是试验pragma、-xxxx等等)。但android/ios、arm32/arm64 的编译器并不一样,往往在ios调得好好的,一放到android arm32架构上就慢得一踏糊涂,反复试验了几十次,结果到了最后,可能还是要用内联汇编。
而如果一开始就下定决心用纯汇编开发,优化策略相应的简单很多,基本上循环展开、指令重排之后,就有立竿见影的效果,试验时间大幅降低,因此总体开发效率反而更快。
方案试验
在优化过程中,我们会不停地去试各种方案,如果停留在C层面,很容易得到跟理论不一致的结果,比如:
量化权重和特征之后运算起来跟没量化的速度差不多。
用了 winograd ,还没有 im2col + gemm 快。
如果代码是比较好的纯汇编实现,性能表现基本就跟理论一样,该快的一定会快,不如预期的在写汇编就会发现设计时没考虑到的缺陷,就基本没有试验这一说了。
代码调试
一般来说,用汇编处理的是逻辑简单,运算复杂的场景,该调试的在前一步C/C++过流程时就已经调试好。
运算密集型的场景,C/C++ 的调试也是很无力的。squeezenet 第一层卷积,
227
∗
227
∗
3
227*227*3
227∗227∗3 的输入,
113
∗
113
∗
64
113*113*64
113∗113∗64 的输出,你想一个个断点去检查正误根本不可能。只能把结果打出来比对。这种情况下,C/C++和汇编的调试难度差不了多少。
性能稳定
纯汇编实现不需要担心工具链对性能影响,无论是哪个工具链编译参数怎么变,对性能影响都有限。
这里再提一下内联汇编,内联汇编虽然可以绕开有一点麻烦的函数传参,但在用的寄存器很多时还是会有问题(看编译器),不如纯汇编中按标准靠谱,因此,内联汇编我们所见到的,用的寄存器都不是很多,无法充分发挥cpu算力。
一个卷积运算,一样的滑动窗口算法,一样地使用neon,纯汇编重写后,arm32 速度提升了 100% 以上,arm64架构提升30%-50%。足见纯汇编重写是一种十分有效的优化方法。
汇编开发
开发难点
学习成本
前面已经分析过,用汇编开发其实效率是高的,但之所以人们觉得开发汇编慢,主要是入门很困难,资料很少。arm 指令集没有个一两年时间,很难说做到熟练。
忍受重复
习惯看和写这种代码,其实也需要一点时间训练,聪明人可能不屑于写,但在你真正能自己弄出编译器之前,还是得忍一下。
vmax.f32 q0, q0, q15
vmax.f32 q1, q1, q15
vmax.f32 q2, q2, q15
vmax.f32 q3, q3, q15
vmax.f32 q4, q4, q15
vmax.f32 q5, q5, q15
vmax.f32 q6, q6, q15
vmax.f32 q7, q7, q15
基本流程
1、梳理代码,设计实现方案,提炼出核心的运算部分,先用C实现一遍,保证正确
2、32位汇编代码初步实现,保证功能正确
3、汇编代码优化:这一步优化只做循环展开和指令重排,如果有更好的计算方案,先退回 C 重新写
4、64位的也支持一下:替换一下寄存器名和指令名(可以写脚本完成),然后微调一下函数前后读参数、入出栈与返回的地方
(可选)64位的进一步优化一下,毕竟寄存器多了一倍
Procedure Call Standard【函数调用标准】
函数调用标准是写纯汇编时一定要掌握的,不然会出现很多莫名奇妙的错误
详细的文档参见arm官网
http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.ihi0042f/index.html
我这里简单总结了一下
ARM 32(v7a)

用完恢复是指相应的寄存器在函数返回前必须恢复进入时的值,比如我们要在代码中用 q4,就必须在函数前写一句
vpush {q4}
函数返回前写一句:
vpop {q4}
这里面写的不能用的寄存器,如果仔细看了 call standard,会发现其实还是能使用的。但建议没完全搞懂前,最好别用,一般也不需要用那么多。
ARM 64(v8)
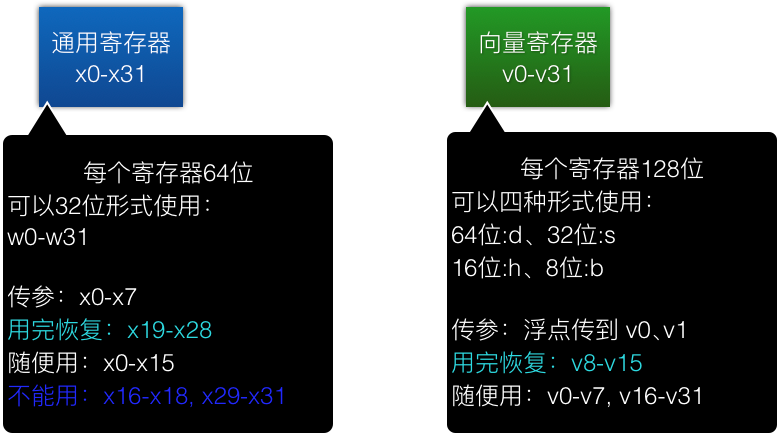
值得注意的是,arm64 的传参为浮点时,会传到 v0.s[0], v0.s[1] …… 而非通用寄存器,这个很坑,建议不要用浮点传参
汇编优化实例
C的Relu 代码
void ReluForward(float* dst, const float* src, size_t sizeDiv4)
{
for (int i=0; i<4*sizeDiv4; ++i)
{
dst[i] = src[i] >0 ? src[i] : 0;
}
}
有些同学想必会看循环内的 4sizeDiv4 不顺眼,心想:这不应该在前面写个 int size = 4sizeDiv4,免得每次循环时都计算么? 这里是特地这么写的:
1、4*sizeDiv4 这个表达式由于 4 及 sizeDiv4 在循环时未发生改变,-O2之后编译器是不会重复生成计算该表达式的语句的,请停止你的优化强迫症。
2、C++的代码主要就是让你明白这函数干嘛用的,别关注性能,写汇编时再抠。
c-neon
void ReluCNeon(float* dst, const float* src, size_t sizeDiv4)
{
float32x4_t limit = vdupq_n_f32(0.0f);
for (int i=0; i<sizeDiv4; ++i)
{
float32x4_t value = vld1q_f32(src);
value = vmaxq_f32(value, limit);
vst1q_f32(dst, value);
dst+=4;
src+=4;
}
}
基础汇编
由于ios和android上面函数编译的符号不一致,这里引入一个头文件,定义一个函数声明宏,去屏蔽这种差异:
ArmAsmGlobal.h
.macro asm_function fname
#ifdef __APPLE__
.globl _\fname
_\fname:
#else
.global \fname
\fname:
#endif
//汇编:ReluBasic
#include "ArmAsmGlobal.h"
asm_function ReluBasic
//按照 arm32 的 函数调用标准,以下变量由调用方传至寄存器
//r0: dst, r1: src, r2: sizeDiv4
push {lr}
vmov.i32 q15, #0
cmp r2, #0
beq End //跳转:beq 表示 r2 等于0时跳转
Loop://标志,供跳转用
vld1.32 {q0}, [r1]!
vmax.f32 q0, q0, q15
vst1.32 {q0}, [r0]!
subs r2, r2, #1// 这一句 相当于 sub r2, r2, #1 && cmp r2, #0
bne Loop //跳转:bne 表示 r2 不等于0时跳转
End:
pop {pc}
汇编优化
我们注意到循环主体,语句前后有较强依赖关系:
vld1.32 {q0}, [r1]!
vmax.f32 q0, q0, q15 //q0 依赖于 前一行的读
vst1.32 {q0}, [r0]! //q0 依赖于前一行的算
ARM 的CPU一般都有双通道发射能力(跟多核多线程不是同一个概念),在执行如下类型的语句时,可以并发执行,提升效率:
vld1.32 {q0}, [r1]!
vmax.f32 q1, q1, q15 //不使用 q0,无依赖关系
为了让我们的汇编代码解除语句前后的依赖关系,先进行一次循环展开:
//汇编:ReluUnroll
#include "ArmAsmGlobal.h"
asm_function ReluUnroll
vmov.i32 q15, #0
push {lr}
L4:
cmp r2, #3
ble L1
L4Loop:
vld1.32 {q0, q1}, [r1]!
vld1.32 {q2, q3}, [r1]!
vmax.f32 q0, q0, q15
vmax.f32 q1, q1, q15
vmax.f32 q2, q2, q15
vmax.f32 q3, q3, q15
vst1.32 {q0, q1}, [r0]!
vst1.32 {q2, q3}, [r0]!
sub r2, r2, #4
cmp r2, #4
bge L4Loop
L1:
cmp r2, #0
beq End
L1Loop:
vld1.32 {q0}, [r1]!
vmax.f32 q0, q0, q15
vst1.32 {q0}, [r0]!
subs r2, r2, #1
bne L1Loop
End:
pop {pc}
展开之后,L4Loop 内部的语句已经大部分解除了依赖,但还不完全,为了完全解除,我们需要用个小技巧【汇编重点技巧】:
//汇编:ReluUnrollReorder
#include "ArmAsmGlobal.h"
asm_function ReluUnrollReorder
push {lr}
vmov.i32 q15, #0
L4:
cmp r2, #3
ble L1
vld1.32 {q0, q1}, [r1]!
vmax.f32 q0, q0, q15
vld1.32 {q2, q3}, [r1]!
vmax.f32 q1, q1, q15
sub r2, r2, #4
cmp r2, #3
ble L4End
L4Loop:
vst1.32 {q0, q1}, [r0]!
vmax.f32 q2, q2, q15
vld1.32 {q0, q1}, [r1]!
vmax.f32 q3, q3, q15
vst1.32 {q2, q3}, [r0]!
vmax.f32 q0, q0, q15
vld1.32 {q2, q3}, [r1]!
sub r2, r2, #4
vmax.f32 q1, q1, q15
cmp r2, #4
bge L4Loop
L4End:
vst1.32 {q0, q1}, [r0]!
vmax.f32 q2, q2, q15
vmax.f32 q3, q3, q15
vst1.32 {q2, q3}, [r0]!
L1:
cmp r2, #0
beq End
L1Loop:
vld1.32 {q0}, [r1]!
vmax.f32 q0, q0, q15
vst1.32 {q0}, [r0]!
subs r2, r2, #1
bne L1Loop
End:
pop {pc}
这个技巧就是将循环主体代码拆成两半,原先的 Loop[AB] 就变成了 A->Loop[BA]->B,然后 BA 由于顺序颠倒,可以实现错排并发。
性能对比
魅蓝 mental 上测试
sizeDiv4 = 100000,连续跑10000次(由于 relu 是一个十分简单的op,跑大批量的才能看到效果)
C-neon Cost time : 4856.960449 ms
汇编ReluBasic Cost time : 4716.672363 ms
汇编ReluUnroll Cost time : 2814.848145 ms
汇编ReluUnrollReorder Cost time : 2359.424072 ms
可以看到:
1、最简单的汇编和用 neon api 的 C差不大多
2、同样是汇编,ReluUnrollReorder较ReluBasic足足提升了100%

















 164
164

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









