







1. 感知器算法(两类)
基本思想:用训练模式检验初始的或迭代中的增广权矢量w的合理性,当不合理时,对齐进行校正。
算法实质:最优化技术中的梯度下降法。也是人工神经网络理论中的线性阈值神经元学习方法。
如果训练模式是线性可分的,感知器训练算法是在有限次迭代后便可以收敛到正确的解矢量\(w^*\)
代码实现:
初始化和释放:
int init_data()
{
int i, j;
int *data;
mat_point = cvCreateMat(COUNT, 4, CV_32SC1);
cvSetZero(mat_point);
srand(time(NULL));
for (i = 0; i< mat_point->height; i++)
{
data = (int *)(mat_point->data.ptr + i * mat_point->step);
data[0] = RANDOM_X;
data[1] = RANDOM_Y;
data[2] = 1;
if (data[0] < 200)
data[3] = 1;
else
data[3] = -1;
}
mat_weight = cvCreateMat(1, 4, CV_64FC1);
cvSetZero(mat_weight);
return 0;
}
int release_data()
{
cvReleaseMat(&mat_point);
cvReleaseMat(&mat_weight);
return 0;
}int compute(int *point, double *weight)
{
double sum =0.0;
int i;
for (i = 0; i < 3; ++i)
{
sum += point[i] * weight[i];
}
if(sum > 0.0)
return 1;
else
return -1;
}int main()
{
bool bLearningOK = false;
int count = 0;
int *point;
double *weight;
//感知器学习算法
init_data();
while(!bLearningOK)
{
bLearningOK = true;
for (int i = 0 ; i < COUNT ; ++i)
{
point = (int *)(mat_point->data.ptr + mat_point->step * i);
weight = mat_weight->data.db;
int output = compute(point,weight);
if(output!= point[3])
{
for(int w = 0 ; w <3 ; ++w)
{
weight[w] += alpha * point[3] * point[w];
}
bLearningOK = false;
}
}
count++;
// cout<<count<<endl;
// show_update(50);
}
show_update(0);
release_data();
return 0;
}
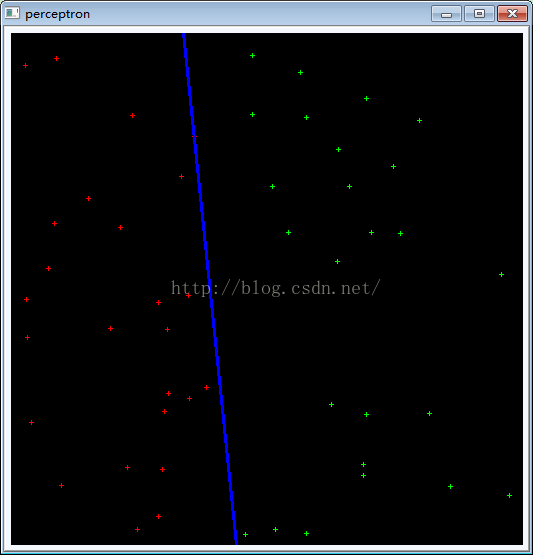
代码下载:http://download.csdn.net/detail/k_shmily/9598341
2.一次准则函数及梯度下降法
采用最优化技术求解线性判别函数中的增广权矢量时,首先构造准则函数,负梯度方向是函数下降最快的方向。
构造准则行数:\( J(w)=k( |w^T x| - w^T x)\) (k>0)
当 \(w^T x<0 \)时 J(w)>0
当 \(w^T x>=0 \)时 J(w)=0 \(J(w)\)有极小值 \(J_{min}(w)=0\)
准则函数的梯度:\( \bigtriangledown J(w) = \frac{\partial J }{\partial w } = \frac{1}{2} [x\, sng( w^T x)- x]\)
由梯度下降法,增广权矢量的修正迭代公式为
\(w(k+1) = w(k) - \rho_k \bigtriangledown J(w(k))\)
\(w(k+1) =\left\{\begin{matrix} k(x) & w^T (k)x_k > 0 \\ k(x)+\rho_k x_k & w^T (k)x_k <= 0, \rho_k>0 \end{matrix}\right. \)
3.感知器训练算法在多类问题中的应用
建立c个判别函数 \( d_i(x) = w_i^T x_i\) (i=1,2,...c)
如果 \( x\in w_i\), 则有 \( w_i^T x> w_j^T x\,\,\,\,(\forall j\neq i)\)
具体步骤:
(1)初始化c个权矢量
(2)输入已知类别的增广训练模式,计算c个判别函数
(3)修正权矢量(对应样本的判别函数值为最大时,不用修正)














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









