







c 内存分配
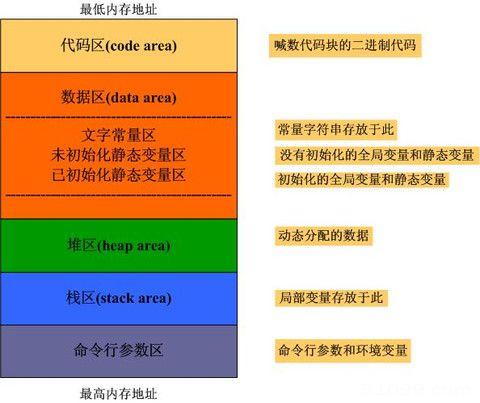
1、程序代码区:存放函数体的二进制代码。
2、全局区数据区:全局数据区划分为三个区域。
全局变量和静态变量的存储是放在一块的。初始化的全局变量和静态变量在一块区域,未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。常量数据存放在另一个区域里。这些数据在程序结束后由系统释放。我们所说的BSS段(bss segment)通常是指用来存放程序中未初始化的全局变量的一块内存区域。BSS是英文Block Started by Symbol的简称。
3、栈区:由编译器自动分配释放,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
4、堆区:一般由程序员分配释放,若程序员不释放,程序结束时可能由OS回收。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表,呵呵。
5、命令行参数区:存放命令行参数和环境变量的值。
关于局部的字符串常量是存放在全局的常量区还是栈区,不同的编译器有不同的实现。可以通过汇编语言察看一下。不过vc环境下,局部常量就像局部变量一样存储于栈中,全局常量、字符常量存储于文字常量区。TC在常量区。
例子:
int a = 0; //静态存储区(初始化区域)
char *p1; //静态存储区(未初始化区域)
void example()
{
int b; //栈
char s[] = “abc”; //栈
char *p2; //栈
static int c =0; //静态存储区(初始化区域)
//分配得来的10和20字节的区域就在堆上
p1 = (char *)malloc(10);
p2 = (char *)malloc(20);
}
在嵌入式系统中有ROM和RAM两类内存,程序被固化进ROM,变量和堆栈设在RAM中,用const定义的常量也会被放入ROM。
注:用const定义常量可以节省空间,避免不必要的内存分配。
#define PI 3.14159//常量宏
const double g_pi = 3.14159;//此时并未将g_pi放入ROM中
......
double a = g_pi;//此时为g_pi分配内存,以后不再分配!
double b = PI;//编译期间进行宏替换,分配内存
double c = g_pi;//没有内存分配
double d = PI;//再进行宏替换,又一次分配内存!
在linux下:可以通过参数-c来编译生成汇编文件。如:
gcc -c *.c
gcc *.o -Map test.txt -o test.elf
用文本编辑器查看test.txt文件,你就看到那些bss段,data段,text段等信息了,但是没有堆栈段相关信息,用objdump命令查看.o文件的反汇编后的信息,或者用gcc -S *.c,查看各个.S文件就明白了。
文章二、内存的规划种类
1)常规内(Conventional Memory)在内存分配表中占用最前面的位置,从0KB到640KB(地址000000H~109FFFFH),共占640KB的容量。因为它在内存的最前面并且在DOS可管理的内存区,我们又称之为Low Dos Memory(低DOS内存),或称为基本内存(Base Memory),使用此空间的程序有BIOS、DOS操作系统、外围设备的驱动程序、中断向量表、一些常驻的程序、空闲可用的内存空间、以及一般的应用软件都可在此空间执行。
2)高位内存(UM)是英文Upper Memory的缩写,是常规内存上面的一层内存(640KB~1024KB)。 3)高端内存区(HMA)是英文High Memory Area的缩写。它是1024KB至1088KB之间的64KB内存,管为高端内存区,其地址为100000H~10FFEFH或以上,CPU在实地址模式下以Segment:OFFSET(段地址:偏移量)方式来寻址,其寻址的最大逻辑内存空间为(FFFF:FFFF),即10FFEFH。
4)EMB是英文Extended Memory Block(扩展内存块)的缩写,早期采用的扩充存储器(EPM)必须遵循EMS规范(如使用EMM386.exe),后来使用的扩展存储器(EXM)必须遵循XMS规范(如使用Himem.sys)。扩展内存是指1MB以上的内存空间,其地址是从100000H开始,连续不断向上扩展的内存,扩展内存取决于CPU的寻址能力。
1、内存分配方式
内存分配方式有三种:
(1)从静态存储区域分配。内存在程序编译的时候就已经分配好,这块内存在程序的整个运行期间都存在。例如全局变量,static变量。
(2)在栈上创建。在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。
(3) 从堆上分配,亦称动态内存分配。程序在运行的时候用malloc或new申请任意多少的内存,程序员自己负责在何时用free或delete释放内存。动态内存的生存期由我们决定,使用非常灵活,但问题也最多。
2、常见的内存错误及其对策
发生内存错误是件非常麻烦的事情。编译器不能自动发现这些错误,通常是在程序运行时才能捕捉到。而这些错误大多没有明显的症状,时隐时现,增加了改错的难度。有时用户怒气冲冲地把你找来,程序却没有发生任何问题,你一走,错误又发作了。 常见的内存错误及其对策如下:
* 内存分配未成功,却使用了它。
编程新手常犯这种错误,因为他们没有意识到内存分配会不成功。常用解决办法是,在使用内存之前检查指针是否为NULL。如果指针p是函数的参数,那么在函数的入口处用assert(p!=NULL)进行检查。如果是用malloc或new来申请内存,应该用if(p==NULL) 或if(p!=NULL)进行防错处理。
* 内存分配虽然成功,但是尚未初始化就引用它。
犯这种错误主要有两个起因:
一是没有初始化的观念;
二是误以为内存的缺省初值全为零,导致引用初值错误(例如数组)。内存的缺省初值究竟是什么并没有统一的标准,尽管有些时候为零值,我们宁可信其无不可信其有。所以无论用何种方式创建数组,都别忘了赋初值,即便是赋零值也不可省略,不要嫌麻烦。
* 内存分配成功并且已经初始化,但操作越过了内存的边界。
例如在使用数组时经常发生下标“多1”或者“少1”的操作。特别是在for循环语句中,循环次数很容易搞错,导致数组操作越界。
* 忘记了释放内存,造成内存泄露。
含有这种错误的函数每被调用一次就丢失一块内存。刚开始时系统的内存充足,你看不到错误。终有一次程序突然死掉,系统出现提示:内存耗尽。
动态内存的申请与释放必须配对,程序中malloc与free的使用次数一定要相同,否则肯定有错误(new/delete同理)。
* 释放了内存却继续使用它。
有三种情况:
(1)程序中的对象调用关系过于复杂,实在难以搞清楚某个对象究竟是否已经释放了内存,此时应该重新设计数据结构,从根本上解决对象管理的混乱局面。
(2)函数的return语句写错了,注意不要返回指向“栈内存”的“指针”或者“引用”,因为该内存在函数体结束时被自动销毁。
(3)使用free或delete释放了内存后,没有将指针设置为NULL。导致产生“野指针”。
【规则1】用malloc或new申请内存之后,应该立即检查指针值是否为NULL。防止使用指针值为NULL的内存。
【规则2】不要忘记为数组和动态内存赋初值。防止将未被初始化的内存作为右值使用。
【规则3】避免数组或指针的下标越界,特别要当心发生“多1”或者“少1”操作。
【规则4】动态内存的申请与释放必须配对,防止内存泄漏。
【规则5】用free或delete释放了内存之后,立即将指针设置为NULL,防止产生“野指针”。
3、指针与数组的对比
C /C程序中,指针和数组在不少地方可以相互替换着用,让人产生一种错觉,以为两者是等价的。
数组要么在静态存储区被创建(如全局数组),要么在栈上被创建。数组名对应着(而不是指向)一块内存,其地址与容量在生命期内保持不变,只有数组的内容可以改变。
指针可以随时指向任意类型的内存块,它的特征是“可变”,所以我们常用指针来操作动态内存。指针远比数组灵活,但也更危险。
下面以字符串为例比较指针与数组的特性。
3.1 修改内容
示例3-1中,字符数组a的容量是6个字符,其内容为hello。a的内容可以改变,如a[0]= ‘X’。指针p指向常量字符串“world”(位于静态存储区,内容为world),常量字符串的内容是不可以被修改的。从语法上看,编译器并不觉得语句 p[0]= ‘X’有什么不妥,但是该语句企图修改常量字符串的内容而导致运行错误。
3.2 内容复制与比较
不能对数组名进行直接复制与比较。示例7-3-2中,若想把数组a的内容复制给数组b,不能用语句 b = a ,否则将产生编译错误。应该用标准库函数strcpy进行复制。同理,比较b和a的内容是否相同,不能用if(b==a) 来判断,应该用标准库函数strcmp进行比较。
语句p = a 并不能把a的内容复制指针p,而是把a的地址赋给了p。要想复制a的内容,可以先用库函数malloc为p申请一块容量为strlen(a) 1个字符的内存,再用strcpy进行字符串复制。同理,语句if(p==a) 比较的不是内容而是地址,应该用库函数strcmp来比较。 示例3.2 数组和指针的内容复制与比较
3.3 计算内存容量
用运算符sizeof可以计算出数组的容量(字节数)。示例7-3-3(a)中,sizeof(a)的值是12(注意别忘了’’)。指针p指向a,但是 sizeof(p)的值却是4。这是因为sizeof(p)得到的是一个指针变量的字节数,相当于sizeof(char*),而不是p所指的内存容量。 C /C语言没有办法知道指针所指的内存容量,除非在申请内存时记住它。
注意当数组作为函数的参数进行传递时,该数组自动退化为同类型的指针。示例7-3-3(b)中,不论数组a的容量是多少,sizeof(a)始终等于sizeof(char *)。 示例3.3(a) 计算数组和指针的内存容量 示例3.3(b) 数组退化为指针
4、指针参数是如何传递内存的?
如果函数的参数是一个指针,不要指望用该指针去申请动态内存。示例7-4-1中,Test函数的语句GetMemory(str, 200)并没有使str获得期望的内存,str依旧是NULL,为什么? 示例4.1 试图用指针参数申请动态内存
毛病出在函数GetMemory中。编译器总是要为函数的每个参数制作临时副本,指针参数p的副本是 _p,编译器使 _p = p。如果函数体内的程序修改了_p的内容,就导致参数p的内容作相应的修改。这就是指针可以用作输出参数的原因。在本例中,_p申请了新的内存,只是把 _p所指的内存地址改变了,但是p丝毫未变。所以函数GetMemory并不能输出任何东西。事实上,每执行一次GetMemory就会泄露一块内存,因为没有用free释放内存。
如果非得要用指针参数去申请内存,那么应该改用“指向指针的指针”,见示例4.2。 示例4.2用指向指针的指针申请动态内存
由于“指向指针的指针”这个概念不容易理解,我们可以用函数返回值来传递动态内存。这种方法更加简单,见示例4.3。 示例4.3 用函数返回值来传递动态内存
用函数返回值来传递动态内存这种方法虽然好用,但是常常有人把return语句用错了。这里强调不要用return语句返回指向“栈内存”的指针,因为该内存在函数结束时自动消亡,见示例4.4。 示例4.4 return语句返回指向“栈内存”的指针
用调试器逐步跟踪Test4,发现执行str = GetString语句后str不再是NULL指针,但是str的内容不是“hello world”而是垃圾。
如果把示例4.4改写成示例4.5,会怎么样? 示例4.5 return语句返回常量字符串
函数Test5运行虽然不会出错,但是函数GetString2的设计概念却是错误的。因为GetString2内的“hello world”是常量字符串,位于静态存储区,它在程序生命期内恒定不变。无论什么时候调用GetString2,它返回的始终是同一个“只读”的内存块。
5、杜绝“野指针”
“野指针”不是NULL指针,是指向“垃圾”内存的指针。人们一般不会错用NULL指针,因为用if语句很容易判断。但是“野指针”是很危险的,if语句对它不起作用。 “野指针”的成因主要有两种:
(1)指针变量没有被初始化。任何指针变量刚被创建时不会自动成为NULL指针,它的缺省值是随机的,它会乱指一气。所以,指针变量在创建的同时应当被初始化,要么将指针设置为NULL,要么让它指向合法的内存。例如 (2)指针p被free或者delete之后,没有置为NULL,让人误以为p是个合法的指针。
(3)指针操作超越了变量的作用范围。这种情况让人防不胜防,示例程序如下: 函数Test在执行语句p->Func()时,对象a已经消失,而p是指向a的,所以p就成了“野指针”。但奇怪的是我运行这个程序时居然没有出错,这可能与编译器有关。
6、有了malloc/free为什么还要new/delete?
malloc与free是C /C语言的标准库函数,new/delete是C 的运算符。它们都可用于申请动态内存和释放内存。
对于非内部数据类型的对象而言,光用maloc/free无法满足动态对象的要求。对象在创建的同时要自动执行构造函数,对象在消亡之前要自动执行析构函数。由于malloc/free是库函数而不是运算符,不在编译器控制权限之内,不能够把执行构造函数和析构函数的任务强加于malloc/free。
因此C 语言需要一个能完成动态内存分配和初始化工作的运算符new,以及一个能完成清理与释放内存工作的运算符delete。注意new/delete不是库函数。我们先看一看malloc/free和new/delete如何实现对象的动态内存管理,见示例6。 示例6 用malloc/free和new/delete如何实现对象的动态内存管理
类Obj的函数Initialize模拟了构造函数的功能,函数Destroy模拟了析构函数的功能。函数UseMallocFree中,由于 malloc/free不能执行构造函数与析构函数,必须调用成员函数Initialize和Destroy来完成初始化与清除工作。函数 UseNewDelete则简单得多。
所以我们不要企图用malloc/free来完成动态对象的内存管理,应该用new/delete。由于内部数据类型的“对象”没有构造与析构的过程,对它们而言malloc/free和new/delete是等价的。
既然new/delete的功能完全覆盖了malloc/free,为什么C 不把malloc/free淘汰出局呢?这是因为C 程序经常要调用C函数,而C程序只能用malloc/free管理动态内存。
如果用free释放“new创建的动态对象”,那么该对象因无法执行析构函数而可能导致程序出错。如果用delete释放“malloc申请的动态内存 ”,理论上讲程序不会出错,但是该程序的可读性很差。所以new/delete必须配对使用,malloc/free也一样。
7、内存耗尽怎么办?
如果在申请动态内存时找不到足够大的内存块,malloc和new将返回NULL指针,宣告内存申请失败。通常有三种方式处理“内存耗尽”问题。
(1)判断指针是否为NULL,如果是则马上用return语句终止本函数。例如: (2)判断指针是否为NULL,如果是则马上用exit(1)终止整个程序的运行。例如: (3)为new和malloc设置异常处理函数。例如Visual C 可以用_set_new_hander函数为new设置用户自己定义的异常处理函数,也可以让malloc享用与new相同的异常处理函数。详细内容请参考C 使用手册。
上述(1)(2)方式使用最普遍。如果一个函数内有多处需要申请动态内存,那么方式(1)就显得力不从心(释放内存很麻烦),应该用方式(2)来处理。
很多人不忍心用exit(1),问:“不编写出错处理程序,让操作系统自己解决行不行?”
不行。如果发生“内存耗尽”这样的事情,一般说来应用程序已经无药可救。如果不用exit(1) 把坏程序杀死,它可能会害死操作系统。道理如同:如果不把歹徒击毙,歹徒在老死之前会犯下更多的罪。
有一个很重要的现象要告诉大家。对于32位以上的应用程序而言,无论怎样使用malloc与new,几乎不可能导致“内存耗尽”。我在Windows 98下用Visual C 编写了测试程序,见示例7。这个程序会无休止地运行下去,根本不会终止。因为32位操作系统支持“虚存”,内存用完了,自动用硬盘空间顶替。我只听到硬盘嘎吱嘎吱地响,Window 98已经累得对键盘、鼠标毫无反应。
我可以得出这么一个结论:对于32位以上的应用程序,“内存耗尽”错误处理程序毫无用处。这下可把Unix和Windows程序员们乐坏了:反正错误处理程序不起作用,我就不写了,省了很多麻烦。
我不想误导读者,必须强调:不加错误处理将导致程序的质量很差,千万不可因小失大。 示例7试图耗尽操作系统的内存
8、malloc/free 的使用要点
函数malloc的原型如下: 用malloc申请一块长度为length的整数类型的内存,程序如下: 我们应当把注意力集中在两个要素上:“类型转换”和“sizeof”。
* malloc返回值的类型是void *,所以在调用malloc时要显式地进行类型转换,将void * 转换成所需要的指针类型。
* malloc函数本身并不识别要申请的内存是什么类型,它只关心内存的总字节数。我们通常记不住int, float等数据类型的变量的确切字节数。例如int变量在16位系统下是2个字节,在32位下是4个字节;而float变量在16位系统下是4个字节,在32位下也是4个字节。最好用以下程序作一次测试: 在malloc的“()”中使用sizeof运算符是良好的风格,但要当心有时我们会昏了头,写出 p = malloc(sizeof(p))这样的程序来。
* 函数free的原型如下: 为什么free 函数不象malloc函数那样复杂呢?这是因为指针p的类型以及它所指的内存的容量事先都是知道的,语句free(p)能正确地释放内存。如果p是 NULL指针,那么free对p无论操作多少次都不会出问题。如果p不是NULL指针,那么free对p连续操作两次就会导致程序运行错误。
9、new/delete 的使用要点
运算符new使用起来要比函数malloc简单得多,例如: 这是因为new内置了sizeof、类型转换和类型安全检查功能。对于非内部数据类型的对象而言,new在创建动态对象的同时完成了初始化工作。如果对象有多个构造函数,那么new的语句也可以有多种形式。例如 如果用new创建对象数组,那么只能使用对象的无参数构造函数。例如 不能写成 在用delete释放对象数组时,留意不要丢了符号‘[]’。例如 后者相当于delete objects[0],漏掉了另外99个对象。
10、一些心得体会
我认识不少技术不错的C /C程序员,很少有人能拍拍胸脯说通晓指针与内存管理(包括我自己)。我最初学习C语言时特别怕指针,导致我开发第一个应用软件(约1万行C代码)时没有使用一个指针,全用数组来顶替指针,实在蠢笨得过分。躲避指针不是办法,后来我改写了这个软件,代码量缩小到原先的一半。
我的经验教训是:
(1)越是怕指针,就越要使用指针。不会正确使用指针,肯定算不上是合格的程序员。
(2)必须养成“使用调试器逐步跟踪程序”的习惯,只有这样才能发现问题的本质。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









