









[分词]
单机跑,耗时: 68分钟
[ 训练 ]
$ time ./word2vec -train /data/sogou/sohunews_segmented_1line.txt -output /data/sogou/vectors_sohunews.bin -cbow 0 -size 200 -window 5 -negative 0 -hs 1 -sample 1e-3 -threads 30 -binary 1
Starting training using file /data/sogou/sohunews_segmented_1line.txt
Vocab size: 575479 (非重复的词典单词个数 57 万)
Words in train file: 688085439 (数据文件词个数 6.8 亿)
线程数: 30
预计 12.8小时跑完。
训练出来的文件: vectors.bin 450M
[ 数据来源 ]
ftp://ftp.labs.sog
[几个结果]
上图========>
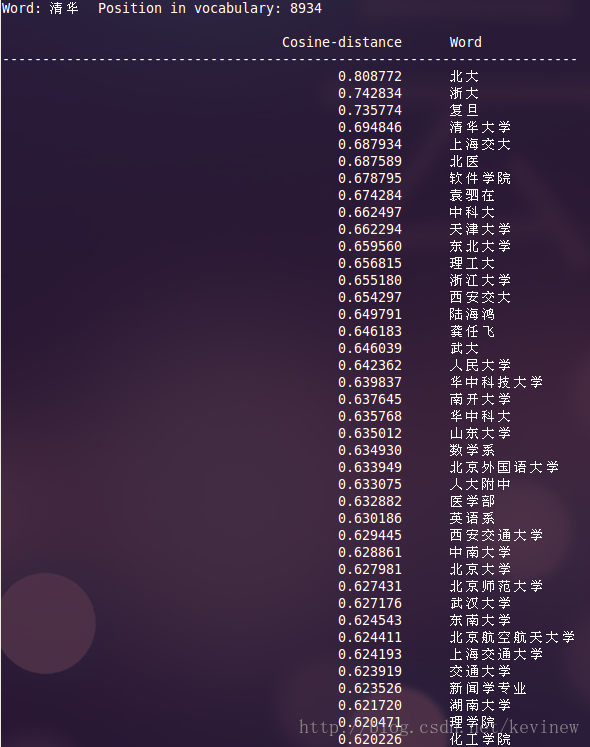
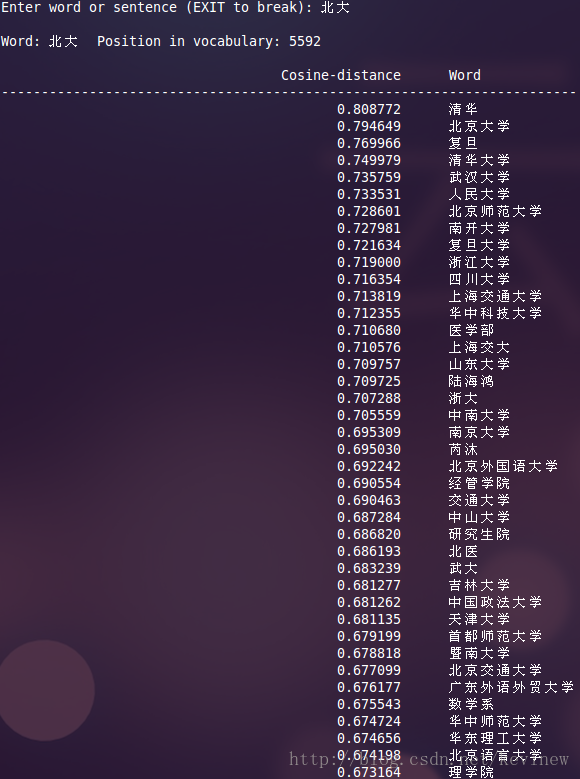
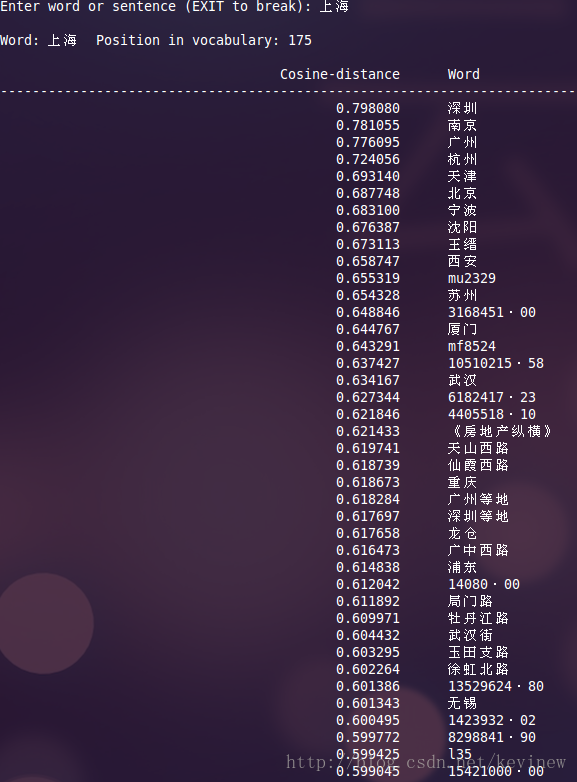
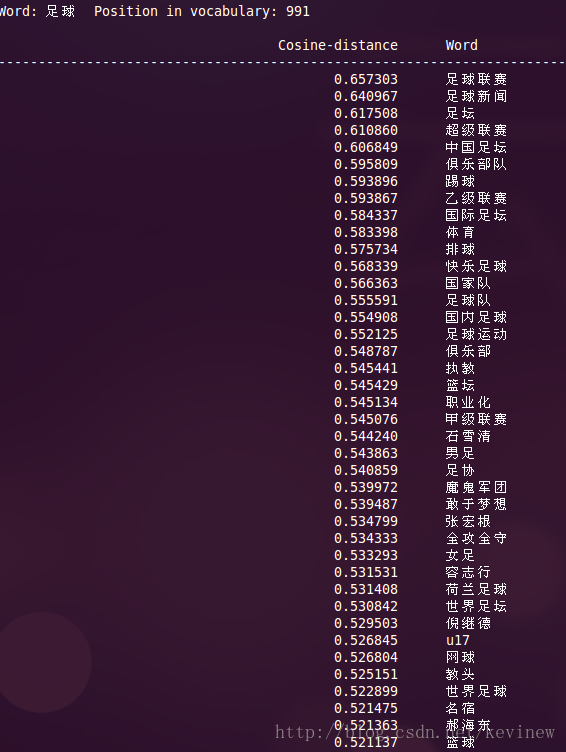
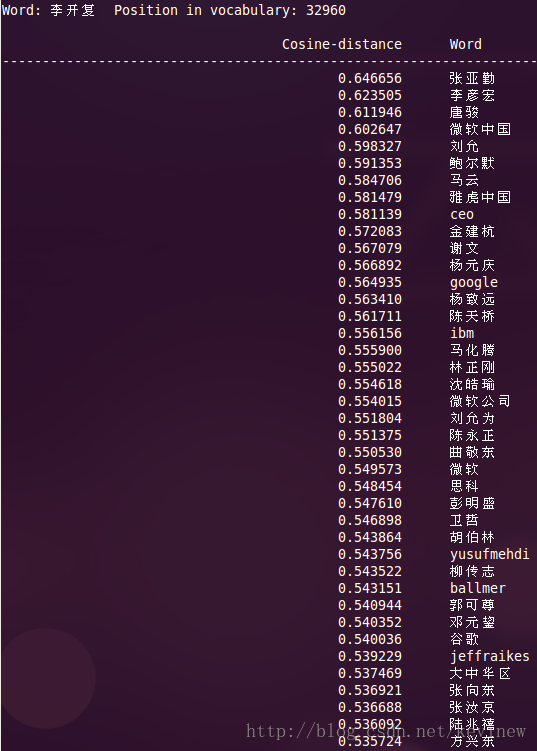
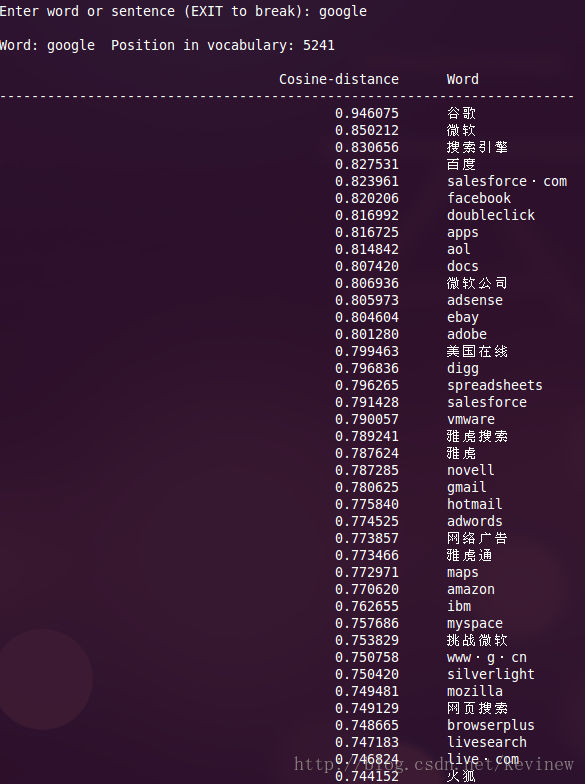
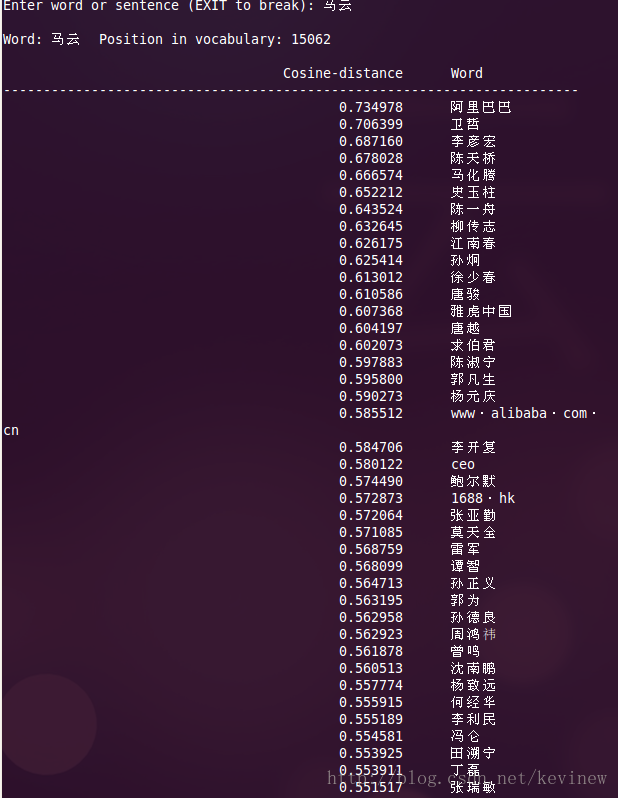

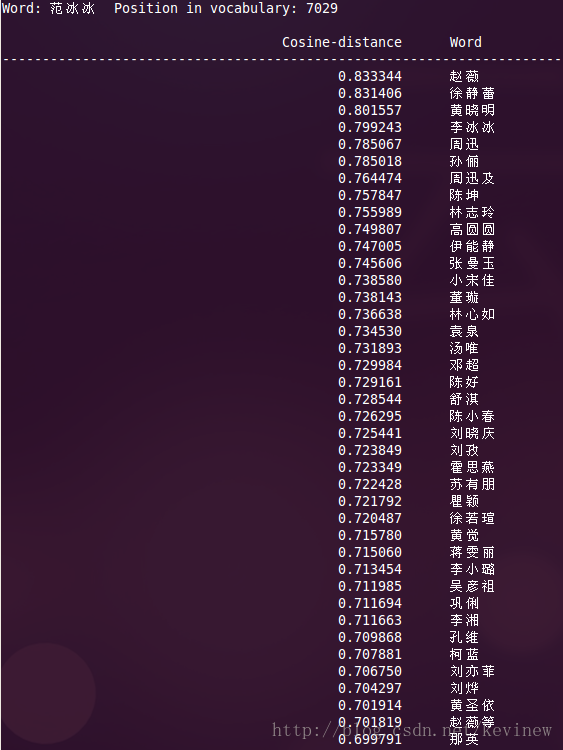

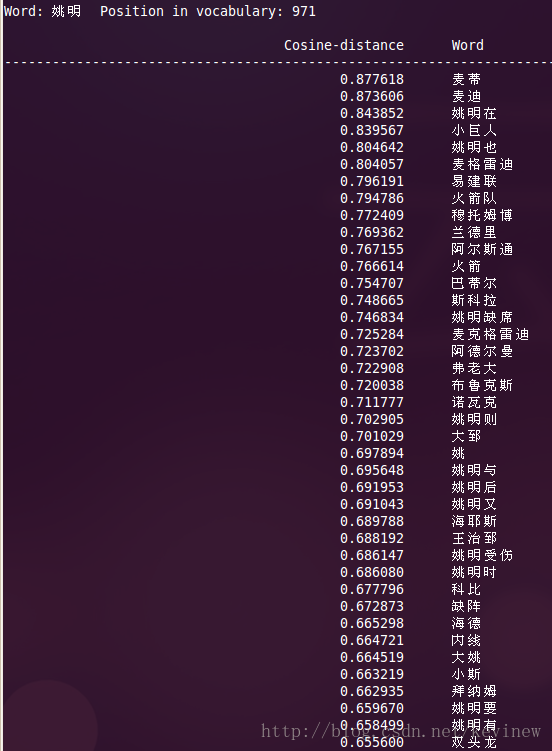
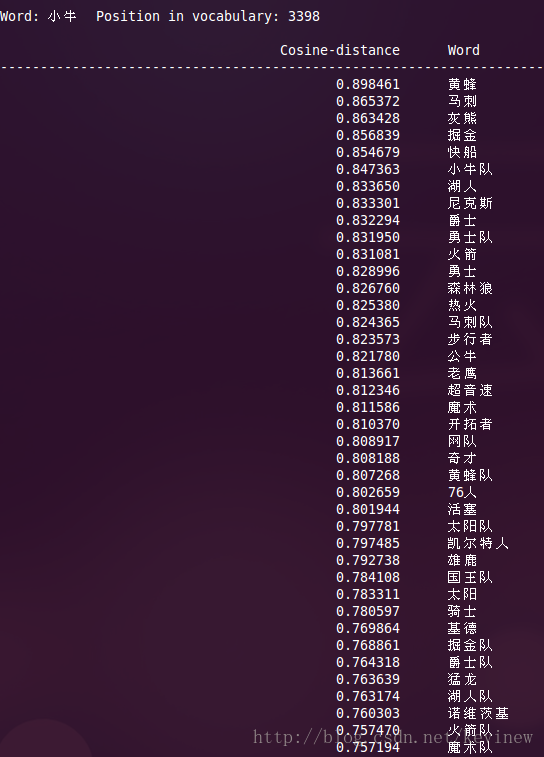
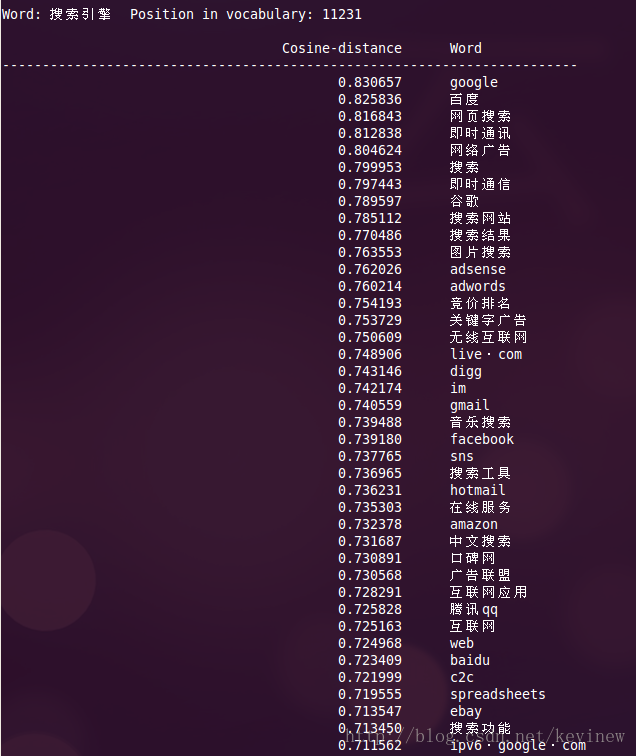
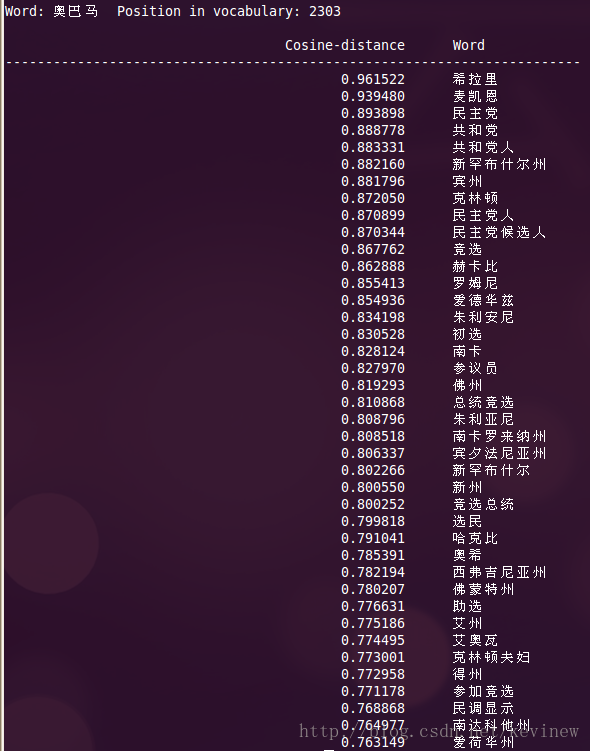
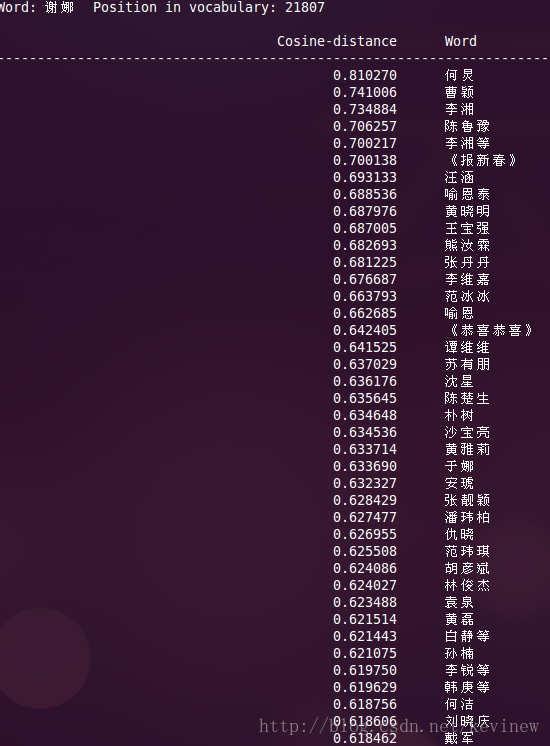
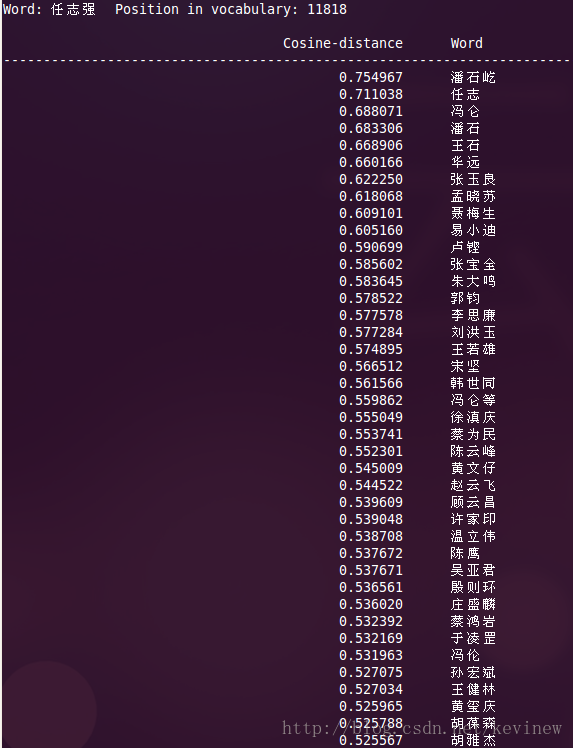
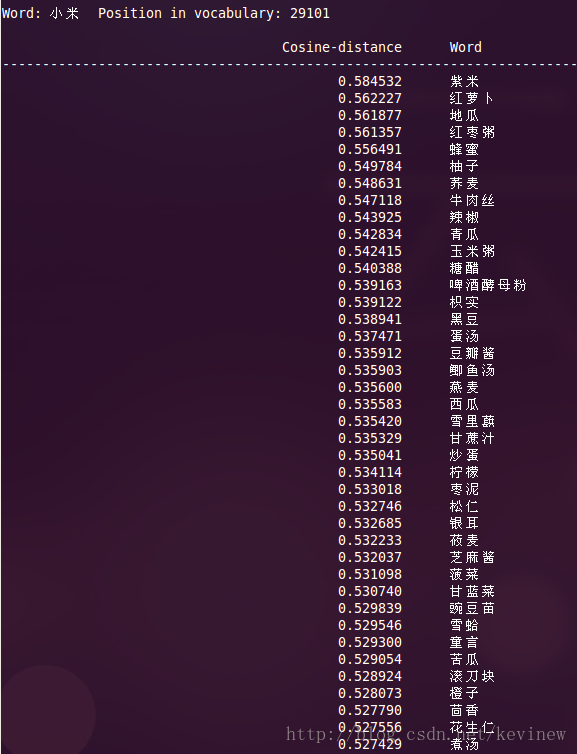
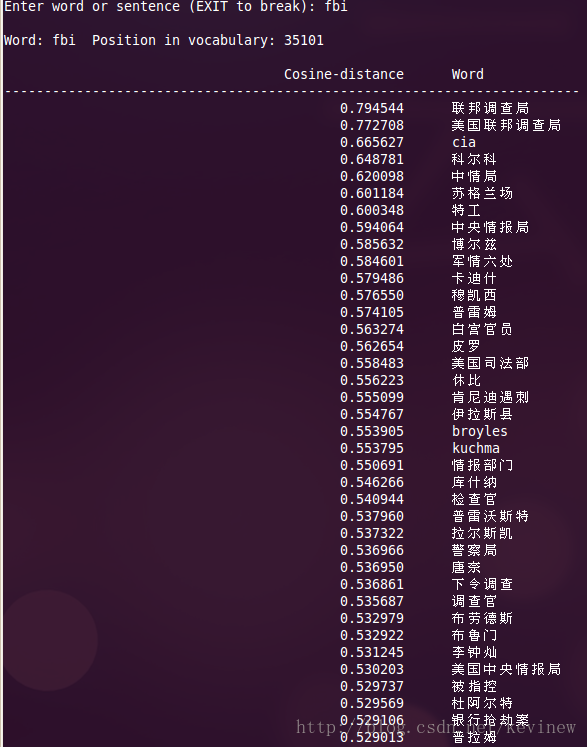
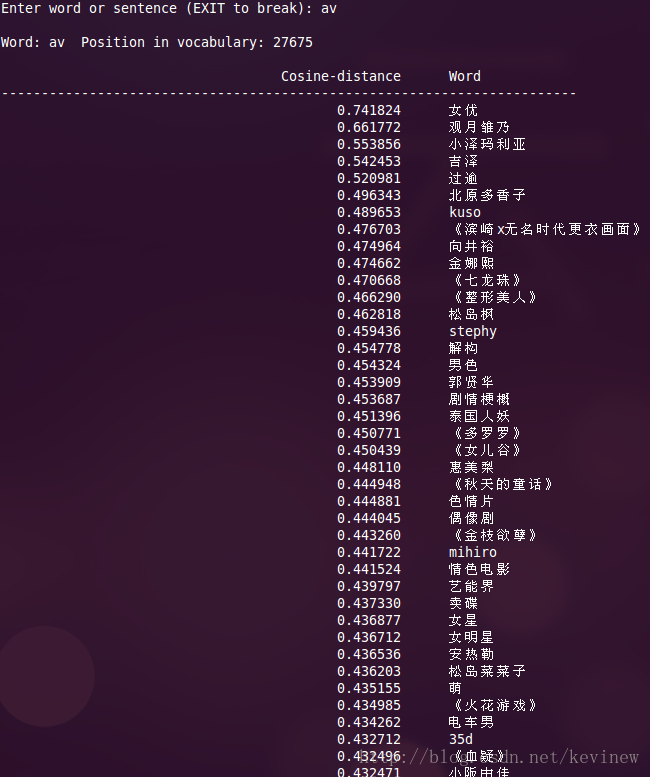
语料加大后,整体的效果还是好了很多,但是多出了一些奇怪的数字,这个在实用的时候需要对分词后结果做下清洗就行。














 645
645











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









