







 k-means是一种常见的无监督学习算法,用于将相似样本聚类在一起。它通过迭代寻找使样本点到其所在簇质心距离平方和最小化的划分。算法流程包括随机选择初始质心,然后不断迭代更新质心和样本分配,直到质心不再改变。然而,k-means易受初始质心选择影响,可能导致局部最优,并且确定最佳k值是个挑战。
k-means是一种常见的无监督学习算法,用于将相似样本聚类在一起。它通过迭代寻找使样本点到其所在簇质心距离平方和最小化的划分。算法流程包括随机选择初始质心,然后不断迭代更新质心和样本分配,直到质心不再改变。然而,k-means易受初始质心选择影响,可能导致局部最优,并且确定最佳k值是个挑战。
1.算法简述
分类是指分类器(classifier)根据已标注类别的训练集,通过训练可以对未知类别的样本进行分类。分类被称为监督学习(supervised learning)。如果训练集的样本没有标注类别,那么就需要用到聚类。聚类是把相似的样本聚成一类,这种相似性通常以距离来度量。聚类被称为无监督学习(unspervised learning)。
k-means是聚类算法中常用的一种,其中k的含义是指有k个cluster。由聚类的定义可知,一个样本应距离其所属cluster的质心是最近的(相较于其他k-1个cluster)。实际上,k-means的本质是最小化目标函数:
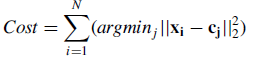

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 2061
2061

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











