







一个例子入门
某位母亲给自己闺女物色了个男朋友,于有了下面这段对话:
女儿:多大年纪了?
母亲:26。
女儿:长得帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算特别高,中等情况吧。
女儿:是不是公务员?
母亲:是,在税务局上班。
女儿:那好,见个面吧。
- 决策过程
这个女孩的决策过程就是典型的分类决策过程。相当于通过年龄,长相,收入和是否是公务员将男人分成两类:见和不见。假设这个女孩对男人的要求是:30岁以下,长相中等,高收入或者中等收入的公务员,那么可以用下图来表示女孩的决策逻辑:

先说优缺点
优点
- 简单易用。
- 决策过程与人的思维习惯接近。
- 能很清楚的图形化模型
缺点
- 容易产生过拟合
- 不支持在线学习,有新样本来的时候,需要重新建决策树。
开始构造决策树
学习构造决策树需要数据,我们就以李航《统计学习方法》中P59的数据作为学习数据。如下:
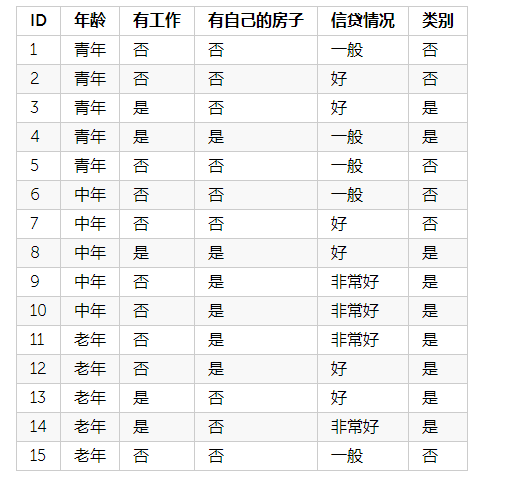
决策树是通过不断的进行特征选择,来减少数据所属类别的不确定性,最终确定一组分类规则。一颗决策树的结点有两种类型。1、非叶节点:特征。2、叶节点:类别。构建一颗决策树大概需要三步:1、特征选择。2、决策树的生成。3、剪枝。下面详细说明三个过程。
第一步:特征选择
问题1:当数据集存在多个特征的条件下,我们应该优先选择哪些特征作为当前的分类规则。
答:通常特征选择的准则是信息增益和信息增益比。它们都是基于熵。
问题2:特征选择为什么基于熵?
答:熵: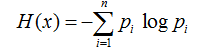
Pi是类出现的概率,log(pi)表示了携带的信息,概率为1信息为0。越是不确定的事情,携带的信息越高。
因为熵可以表示随机变量不确定的度量。所以可以用来作为选择特征的一个指标。
- 信息增益g(D,A)
公式:
H(D):数据集D的熵:表示给定的数据集D属于哪一类的不确定性。
H(D/A):表在特征A给定的情况下对数据集D进行分类的不确定性。
即g(D,A) :表示由于特征A而使得对数据集的不确定性减少的程度。
类似贪心的思想,我们选择当前最优的即不确定性减少程度最大的作为当前特征。下面来谈谈具体的计算。我们以上图的数据为例子。
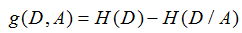

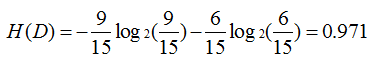
再看特征A={年龄(A1)、有工作(A2)、有自己的房子(A3)、信贷情况(A4)}
下面求H(D/A1)

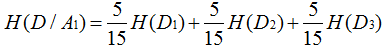
有数据得:
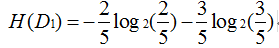
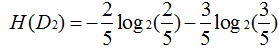
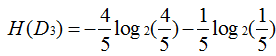
即可求:
g(D,A1)=0.083
同理:
g(D,A2)=0.324
g(D,A3)=0.0.420
g(D,A4)=0.363由于A3(有自己的房子信息增益最大),所以选择A3作为最优特征。
- 利用信息增益存在的问题:
以信息增益作为划分训练数据集的特征,存在偏向于选择取值较多的特征的问题。

问题:取值越多是否就一定会导致信息增益越大?
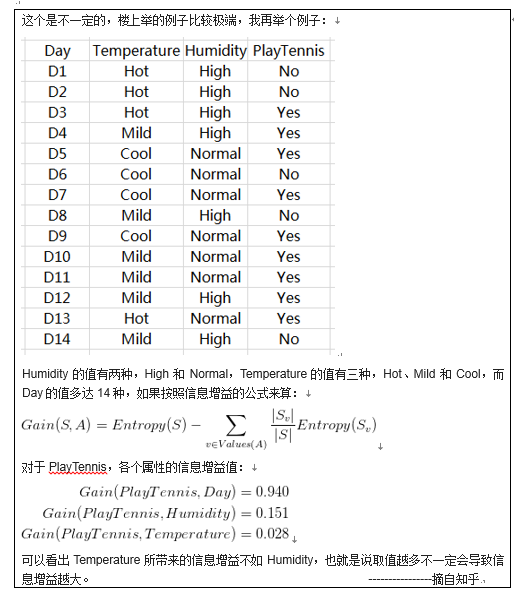
总结:以信息增益作为划分训练数据集的特征,存在偏向于选择取值较多的特征的问题(数据存在这样的趋势,但不是全是这样)。解决办法:信息增益比。
- 信息增益比
n是特征A取值的个数。
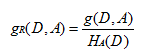
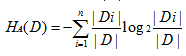
问题:为什么Ha(D)可以控制信息增益的问题。
1、假设数据均匀散开(这不是我们想要的结果)
即每个取值概率约为1/n。此时 Ha(D)的值约为log2(n),n越大Ha(D)越大。正好可以控制。从熵的不确定性角度来看,这种情况随n的增大不确定性增大。
2、 假设数据虽然分散,但大部分集中于一个部分。(这是我们想要的)
这个我们从熵的不确定性角度考虑,虽然n很大,但是熵的不确定性依然很小,即Ha(D)依然很小,这样就保留了我们想要的结果。
综上,Ha(D能很好的控制n很大的情况。
第二步:决策树生成
- ID3算法
输入:训练数据集D,特征集A,阈值e
输出:决策树T
1.若D中所有样本属于同一类Ck,则T为单节点树,并将类Ck作为该节点的类标记,返回T;
2.A为空集,T为单节点树,将D中实例数最大的类Ck作为该节点的类标记,返回T;
3.否则,计算A中各特征对D的信息增益,选择信息增益最大的特征值Ag;
4.如果Ag小于e,则置T为单节点树, 将D中实例数最大的类Ck作为该节点的类标记,返回T;
5.否则,对Ag的每一个可能的取值ai,依Ag=ai将D分割为若干非空子集Di,将Di中实例数最大的类作为标记,构建子节点,由节点及其子节点构成树T,返回T;
6.对第i个子节点,以Di为训练集,以 A-{Ag}为特征集,递归调用1~5步,得到子树Ti,返回Ti。
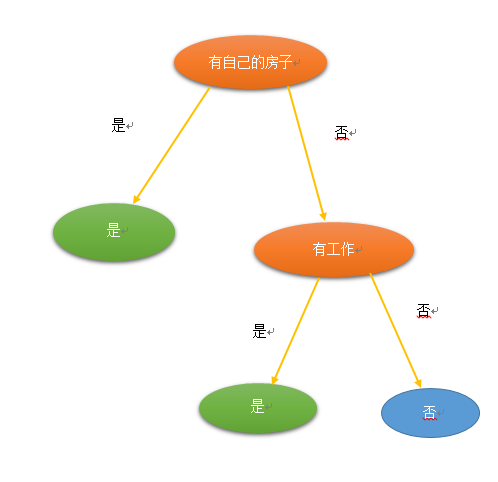
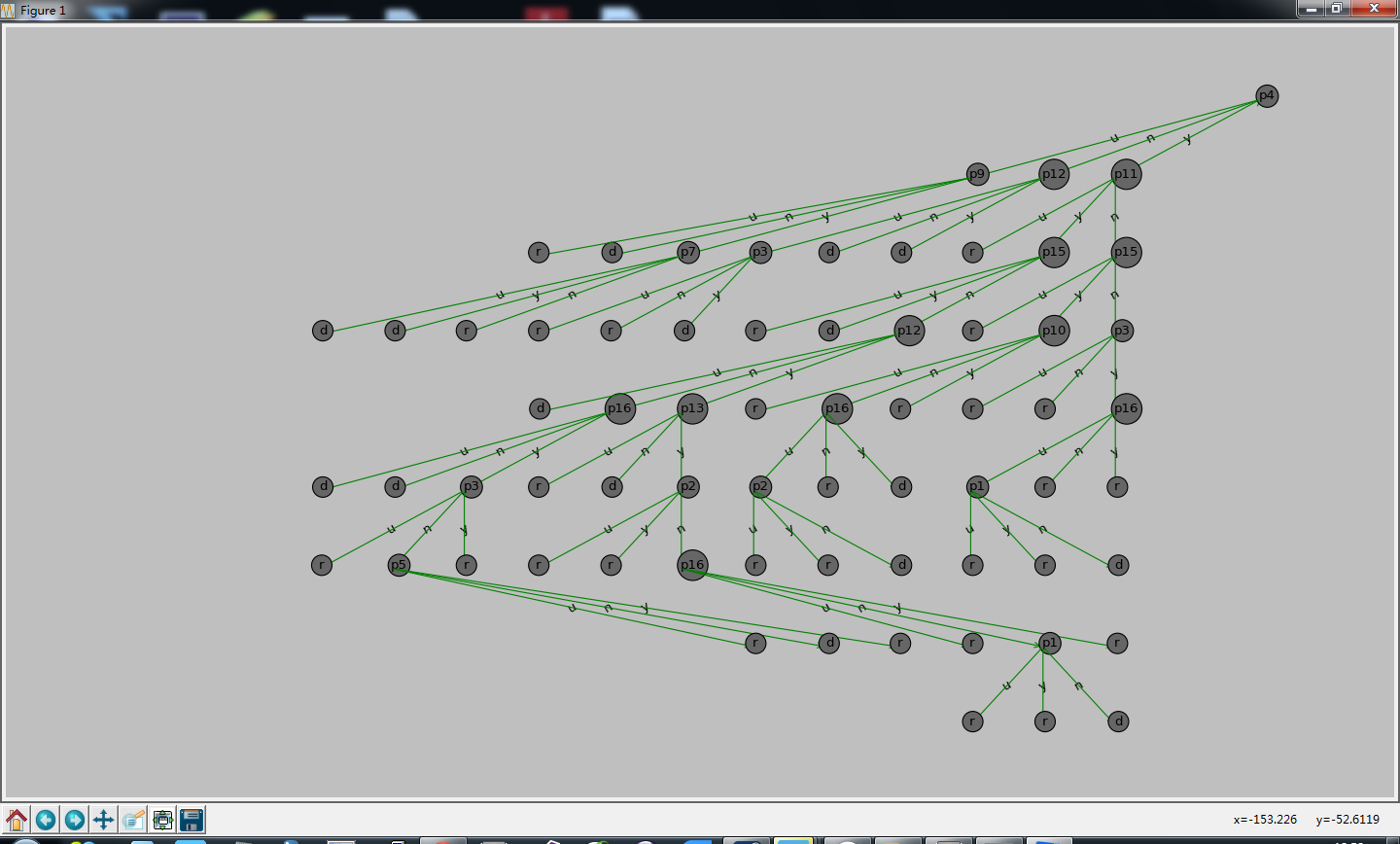
最终生成的决策树。利用图2的数据,最终生成的决策树,如下:
- C4.5算法
C4.5算法与ID3算法的不同点。
1、 在于特征选择用的是信息增益率。
2、 支持对连续数据的处理。
因为算法流程与ID3基本一样,所以这里不再赘述。
主要说下它对连续数据的处理。

第三步:剪枝
剪枝是用来解决过拟合的问题。就是由于数据对样本数据的拟合程度过高,导致对训练数据的判别存在误差。
预剪枝
先剪枝就是设置一定的参数,作为算法结束的条件,来控制树的生成。
一般有几种参数的设置。
1、 最大信息增益低于某个门限值,就停止。
2、 设置树的深度达到一定深度,就停止。
3、 叶节点样本数。当叶节点样本数小于某个值就停止。
参数的选取是要根据实验区测。后剪枝
思想是计算在子树变成节点前后损失函数大小的变化。
把子树变成一个叶节点(类别为样本中的最多类别)后,如果损失函数变小,则剪枝,否则保留原子树。
树的剪枝算法如下:
输入:生成算法产生的整个树T,参数e。
输出:修剪后的子树Te。
(1) 计算每个节点的经验熵。
(2) 递归从树的叶节点向上回缩。设一组叶节点回缩到其父结点之前与之后的整体树分别为Tb与Ta。其对应的损失函数值分别为Ce(Tb)与Ce(Ta),如果 Ce(Tb)>=Ce(Ta),则进行剪枝,即将父结点变成新的子结点。
(3) 返回(2),直至不能继续为止,得到损失函数最小的子树Te。
损失函数定义:
其中经验熵为:
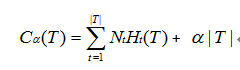
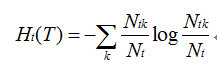
CART算法
这部分后续更新
结果
源码
地址:
https://github.com/zhu-dq/Machine-Learning/tree/master/Decision%20Tree
我实现的是ID3算法。















 3971
3971

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









