







作者: 大树先生
博客: http://blog.csdn.net/koala_tree
知乎:https://www.zhihu.com/people/dashuxiansheng
GitHub:https://github.com/KoalaTree
2017 年 10 月 11 日
以下为在Coursera上吴恩达老师的DeepLearning.ai课程项目中,第二部分《改善深层神经网络:超参数调试、正则化以及优化》第二周课程“优化算法”关键点的笔记。因为这节课每一节的知识点都很重要,所以本次笔记几乎涵盖了全部小视频课程的记录。同时在阅读以下笔记的同时,强烈建议学习吴恩达老师的视频课程,视频请至 Coursera 或者 网易云课堂。
同时我在知乎上开设了关于机器学习深度学习的专栏收录下面的笔记,方便在移动端的学习。欢迎关注我的知乎:大树先生。一起学习一起进步呀!_
改善深层神经网络:超参数调试、正则化以及优化 —优化算法
1. Mini-batch 梯度下降法
对整个训练集进行梯度下降法的时候,我们必须处理整个训练数据集,然后才能进行一步梯度下降,即每一步梯度下降法需要对整个训练集进行一次处理,如果训练数据集很大的时候,如有500万或5000万的训练数据,处理速度就会比较慢。
但是如果每次处理训练数据的一部分即进行梯度下降法,则我们的算法速度会执行的更快。而处理的这些一小部分训练子集即称为Mini-batch。
算法核心:

对于普通的梯度下降法,一个epoch只能进行一次梯度下降;而对于Mini-batch梯度下降法,一个epoch可以进行Mini-batch的个数次梯度下降。
####不同size大小的比较
普通的batch梯度下降法和Mini-batch梯度下降法代价函数的变化趋势,如下图所示:
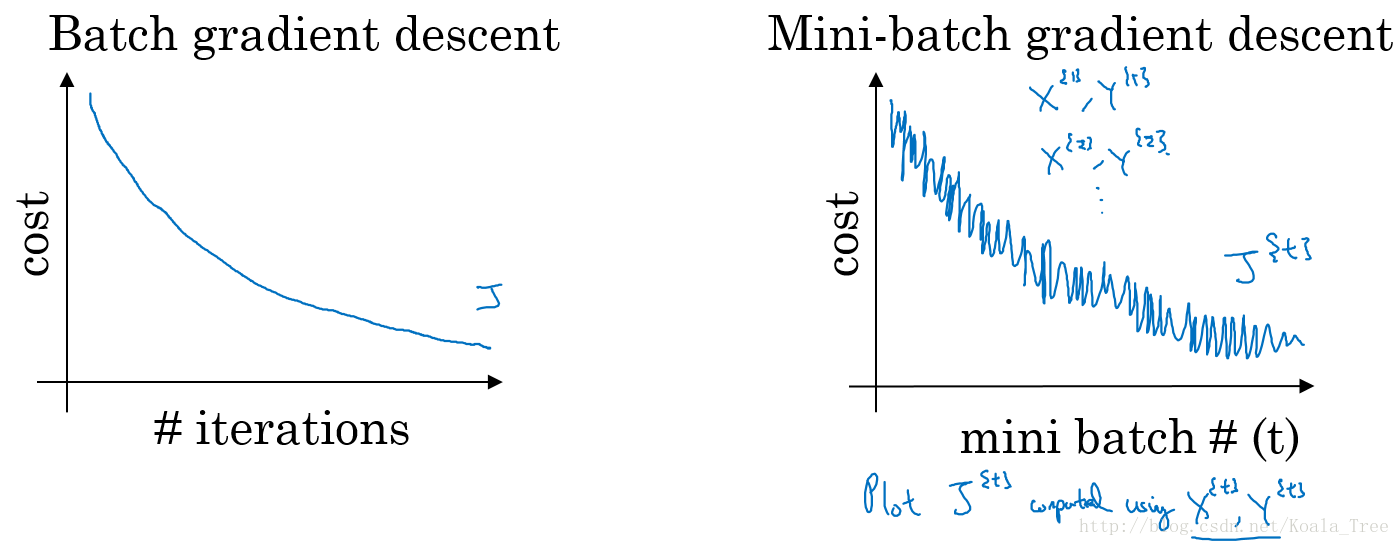
- batch梯度下降:
- 对所有m个训练样本执行一次梯度下降,每一次迭代时间较长;
- Cost function 总是向减小的方向下降。
- 随机梯度下降:
- 对每一个训练样本执行一次梯度下降,但是丢失了向量化带来的计算加速;
- Cost function总体的趋势向最小值的方向下降,但是无法到达全局最小值点,呈现波动的形式。
- Mini-batch梯度下降:
- 选择一个 1 < s i z e < m 1<size<m 1<size<m 的合适的size进行Mini-batch梯度下降,可以实现快速学习,也应用了向量化带来的好处。
- Cost function的下降处于前两者之间。

Mini-batch 大小的选择
- 如果训练样本的大小比较小时,如 m ⩽ 2000 m\leqslant 2000 m⩽2000时 ------ 选择batch梯度下降法;
- 如果训练样本的大小比较大时,典型的大小为:
2 6 、 2 7 、 ⋯ 、 2 10 2^{6}、2^{7}、\cdots、2^{10} 26、27、⋯、210; - Mini-batch的大小要符合CPU/GPU内存。
2. 指数加权平均
指数加权平均的关键函数:
v t = β v t − 1 + ( 1 − β ) θ t v_{t} = \beta v_{t-1}+(1-\beta)\theta_{t} vt=βvt−1+(1−β)θt
下图是一个关于天数和温度的散点图:
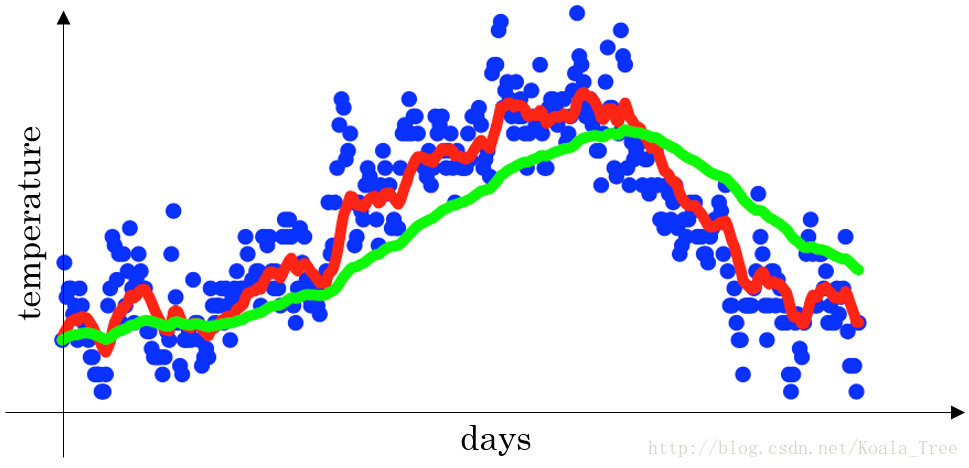
- 当 β = 0.9 \beta =0.9 β=0.9时,指数加权平均最后的结果如图中红色线所示;
- 当 β = 0.98 \beta =0.98 β=0.98时,指数加权平均最后的结果如图中绿色线所示;
- 当 β = 0.5 \beta =0.5 β=0.5时,指数加权平均最后的结果如下图中黄色线所示;
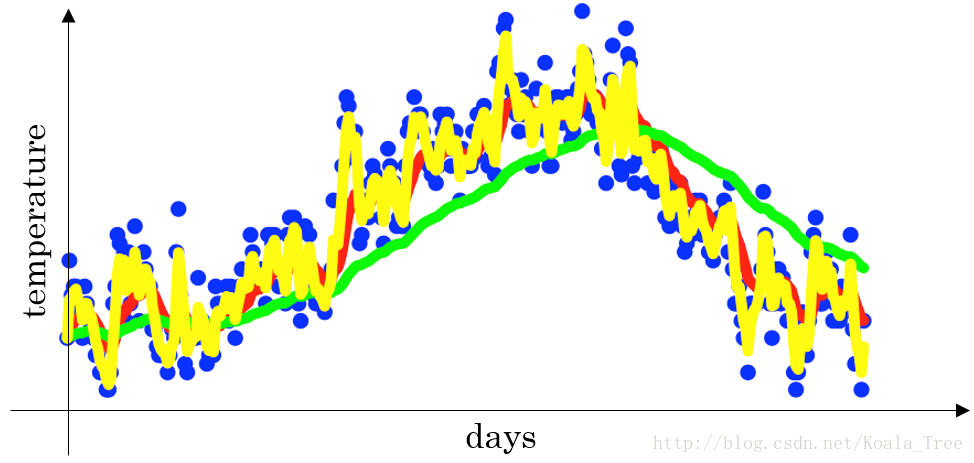
理解指数加权平均
例子,当 β = 0.9 \beta =0.9 β=0.9时:
v 100 = 0.9 v 99 + 0.1 θ 100 v 99 = 0.9 v 98 + 0.1 θ 99 v 98 = 0.9 v 97 + 0.1 θ 98 … v_{100} = 0.9v_{99}+0.1\theta_{100}\\v_{99} = 0.9v_{98}+0.1\theta_{99}\\v_{98} = 0.9v_{97}+0.1\theta_{98}\\ \ldots v100=0.9v99+0.1θ100v99=0.9v98+0.1θ99v98=0.9v97+0.1θ98…
展开:
v 100 = 0.1 θ 100 + 0.9 ( 0.1 θ 99 + 0.9 ( 0.1 θ 98 + 0.9 v 97 ) ) = 0.1 θ 100 + 0.1 × 0.9 θ 99 + 0.1 × ( 0.9 ) 2 θ 98 + 0.1 × ( 0.9 ) 3 θ 97 + ⋯ v_{100}=0.1\theta_{100}+0.9(0.1\theta_{99}+0.9(0.1\theta_{98}+0.9v_{97}))\\=0.1\theta_{100}+0.1\times0.9\theta_{99}+0.1\times(0.9)^{2}\theta_{98}+0.1\times(0.9)^{3}\theta_{97}+\cdots v100=0.1θ100+0.9(0.1θ99+0.9(0.1θ98+0.9v97))=0.1θ100+0.1×0.9θ99+0.1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









