









一. 环境:
apache-nutch-1.8
solr-4.7.0
二. nutch配置提示:
1. 配置 nutch-site.xml
<property> <name>http.agent.name</name> <value>MySpider</value> </property> <property> <name>http.robots.agents</name> <value>MySpider,*</value> </property>http.agent.name 必填
http.robots.agents 选填,若不填,fetch开始时会提示,但不影响运行
2. 修改bin/nutch 权限
chmod +x bin/nutch
3. deploy 目录只有以部署二进制包的形式安装nutch,才会出现
4. regex-urlfilter.txt 分析
# skip file: ftp: and mailto: urls
-^(file|ftp|mailto):^表示开头
file|ftp|mailto 表示要过滤掉开头是file,ftp,mailto的urls
三. solr配置提示:
-
cp ${NUTCH_RUNTIME_HOME}/conf/schema.xml ${APACHE_SOLR_HOME}/example/solr/conf/
- vim ${APACHE_SOLR_HOME}/example/solr/conf/schema.xml
-
Copy exactly in 351 line: <field name="_version_" type="long" indexed="true" stored="true"/> (collection1/conf 中已有此项)
-
restart Solr with the command “java -jar start.jar” under ${APACHE_SOLR_HOME}/example
master上配置好nutch及solr后,移植到其他slave上。
1. scp 两个文件夹过去
2. scp /etc/profile
3. source /etc/profile
4. 注意,若hadoop已经移植过去,那么若之后master上配置有改,记得同步到其他slave上。
5. 注意权限问题。具体要给那些加上权限...不太记得了。可能用到的都附上权限吧。。
四. 排错:
1. 运行nutch提示后退出:Generator: 0 records selected for fetching, exiting ...
bin/nutch readdb data/crawldb -stats可以查看CrawlDB的信息
hadoop@master:~/apache-nutch-1.8$ bin/nutch readdb data/crawldb -stats
CrawlDb statistics start: data/crawldb
Statistics for CrawlDb: data/crawldb
TOTAL urls: 1
retry 1: 1
min score: 1.0
avg score: 1.0
max score: 1.0
status 1 (db_unfetched): 1
CrawlDb statistics: done
db_unfetched 为1,但是retry也为1,所以是抓取失败了。
2. Job failed
command
bin/crawl urls/seed.txt data http://localhost:8983/solr/ 2error
Indexer: java.io.IOException: Job failed!
at org.apache.hadoop.mapred.JobClient.runJob(JobClient.java:1357)
at org.apache.nutch.indexer.IndexingJob.index(IndexingJob.java:114)
at org.apache.nutch.indexer.IndexingJob.run(IndexingJob.java:176)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:65)
at org.apache.nutch.indexer.IndexingJob.main(IndexingJob.java:186)
solr log
org.apache.solr.common.SolrException: ERROR: [doc=http://www.163.com/] unknown field 'host'
nutch log
org.apache.solr.common.SolrException: Bad Request
Bad Request
request: http://localhost:8080/solr/update?wt=javabin&version=2解决
修改 ${APACHE_SOLR_HOME}/example/solr/collection1/conf/schema.xml
在<fields> 与 <fields> 中间增加
<field name="host" type="string" stored="false" indexed="true"/>
<field name="digest" type="string" stored="true" indexed="false"/>
<field name="segment" type="string" stored="true" indexed="false"/>
<field name="boost" type="float" stored="true" indexed="false"/>
<field name="tstamp" type="date" stored="true" indexed="false"/>效果
检索抓取到的内容,用浏览器打开 http://localhost:8983/solr/#/collection1/query
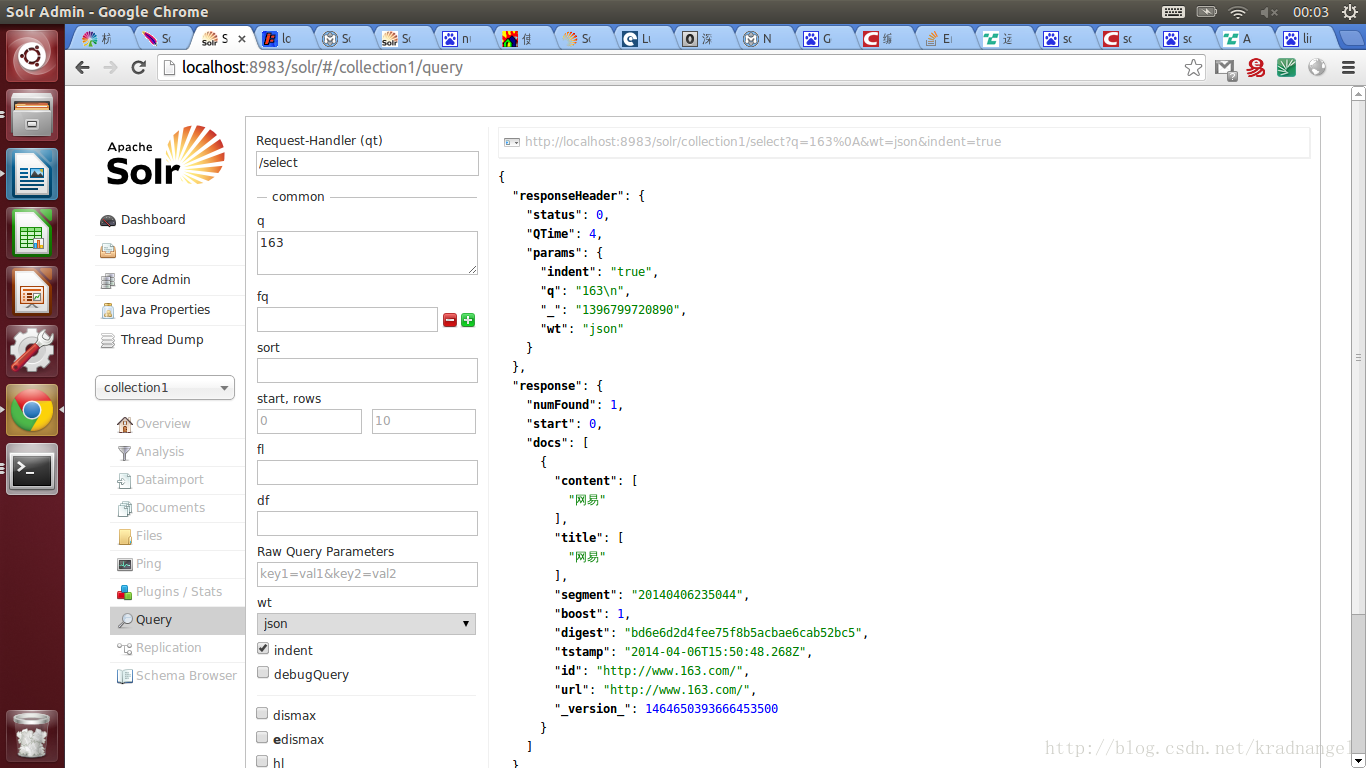
http://stackoverflow.com/questions/13429481/error-while-indexing-in-solr-data-crawled-by-nutch
http://blog.csdn.net/panjunbiao/article/details/12171147
3. Warning: $HADOOP_HOME is deprecated.
在/etc/profile中加
export HADOOP_HOME_WARN_SUPPRESS=14. nutch在hadoop上跑时出错:
14/04/08 12:28:07 INFO mapred.JobClient: Map output records=1
14/04/08 12:28:07 INFO crawl.Generator: Generator: finished at 2014-04-08 12:28:07, elapsed: 00:00:51
ls: 无法访问data/segments/: 没有那个文件或目录
Operating on segment :
Fetching :解决:见我另一篇博文:
nutch on hadoop 遇到 ls: 无法访问data/segments: 没有那个文件或目录
五. 待解决:
1. 压力测试
http://blog.csdn.net/shirdrn/article/details/7055355
2. anchor
org.apache.solr.common.SolrException: ERROR: [doc=http://baike.baidu.com/] unknown field 'anchor'怀疑是中文分词之类的问题
http://www.163.com/ 没问题
http://www.baidu.com http://www.renren.com 有问题
http://nutch.apache.org/ http://hadoop.apache.org/ http://lucene.apache.org/ 没问题
3. Generator:0 records selected for fetching,
怀疑是url数量不够,增加url之后,问题解决。
六. 附录:
观察nutchcrawl的每一步
Solr配置文件:schema.xml
深入Solr实战
Lucene/ Solr开发经验
NutchTutorial
Hadoop Shell命令
DataNode节点上数据块的完整性——DataBlockScannerhadoop nutch solr 环境搭建手册
Solr调研总结
Nutch的命令详解
Nutch 插件系统浅析














 1211
1211











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









