







首先介绍一下主流的数据库有:
大型数据库:oracle,db2
中型数据库:MySql Sql Server
小型数据库:Sqlite,Access
我们使用oracle介绍
使用软件 :OracleXEUniv 这里使用精简版
路径配置:一般安装自己会配置好,如果没有自动配置好,可以使用手动配置
C:\oraclexe\app\oracle\product\10.2.0\server\bin安装过程中一般需要设置口令(密码):我这里设置为root,账号是默认的system
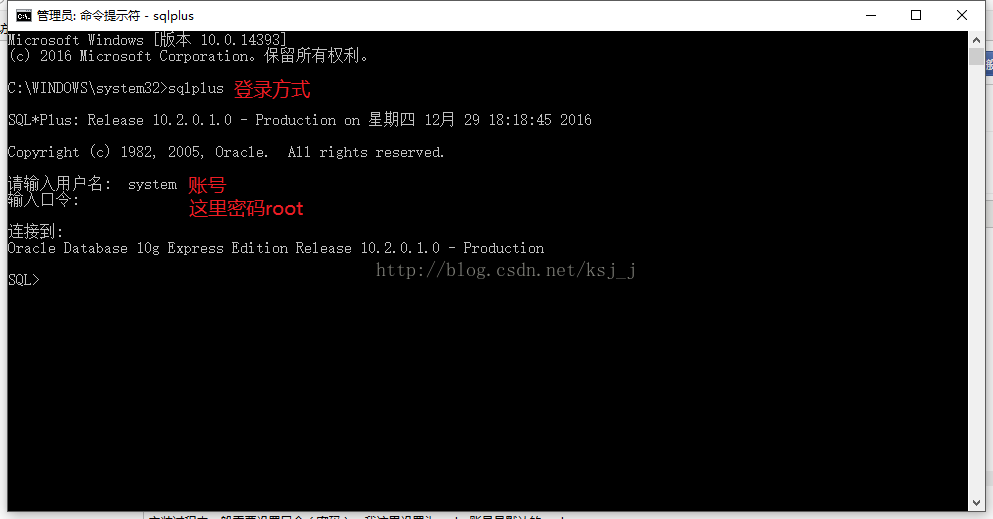
如果以上都完成了就可以打开命令行
登录方式sqlplus回车输入账号密码,还有就是直接sqlplus system/root
创建一个新的用户:user1账号,pwd密码
create user user1 identified by pwd;
注意这样创建的用户是没有登录权限的,接下来赋予权限
grant connect,resource to user1;权限赋予完成后,就可以登录,这里可以选择exit;推出之后在登录,但是有一种直接切换的方式,这里的user1为账号,pwd为密码
切换到新建用户user1
conn user1/pwd那完成了创建用户,权限的赋予后我们就可以操作数据库了,首先要明白这里有一个默认数据库XE,所以我们可以直接创建表,不需要像mysql那样先选择数据库才可以创建表
创建表的语句格式为:create table 表明(字段名 数据类型 约束名);
create table tbl_salary(id number(10) primary key,
name varchar(20) not null,dept_id number(10) not null,
salary number(6) not null); create table tbl_user(id number(8) primary key,
dept_id number(8) references tbl_salary(id),
username varchar(20) not null);
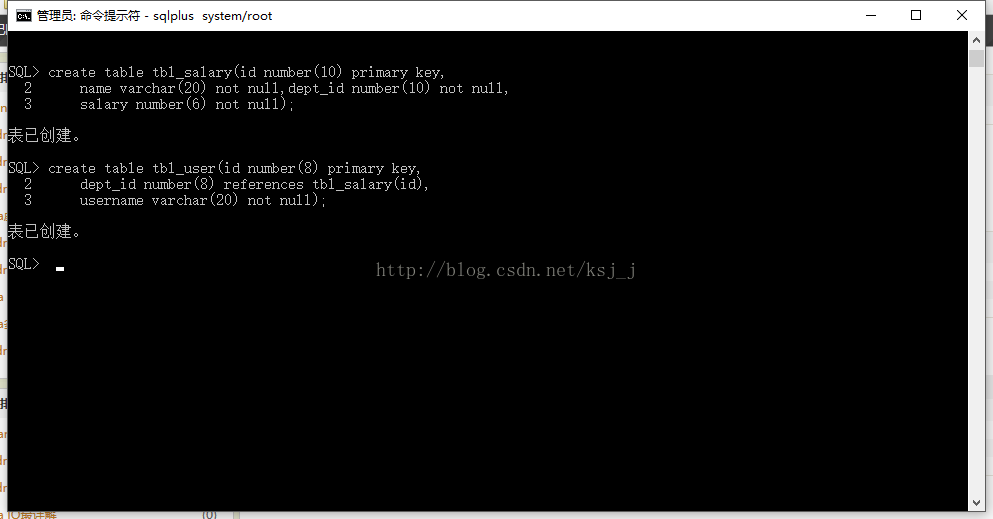
表中的一些关键字什么意思暂时不解释了,反正要明白就是创建了一个名字为tbl_user的表和一个名字为tbl_salary的表
这里在创建好的表,我们将会使用上面两个表作为我测试的实例
在这里我说一下创建表需要规范命名,这是一个良好的习惯
sql关键字
数据类型
number:整型
char:字符型
varchar:字符串型
varchar2:字符串型(只有oracle可用。使用oracle数据可以推荐使用)
date:时间类型
datetime:跟精确的时间(两个使用以情况而定)
常用的就这些,后面带的数据代表可以许可多少位,这里举个特例number(5,2)这里代表5位,有3位整数,2位小数
约束名
primary key:主键声明,主键是唯一的,且非空
references(foreign key):外键的声明,连接其他表的数据
not null:字段值非空
unique:字段值唯一
常用的就这些把,其它的这里就不讲了
查询表结构:
desc tbl_user;删除表:
drop table tbl_user;接下来介绍增删改查:
增加:使用insert语句
insert
into tbl_user
values(1,2,'system');insert
into tbl_user(id,emp_id,username)
values(2,3,'root');这里注意使用单引号,双引号代表转义
修改:使用update语句
update tbl_user
set name = 'bbb';update tbl_user
set name = 'bbb'
where id = 2;
删除:使用delete语句
delete
from tbl_user;delete
from tbl_user
where id = 2;删除表中id=2的数据
查询:使用select语句
这里简单的将select语句分为:
简单查询,条件查询,分组查询,多表查询,子查询
简单查询:
select *
from tbl_user;条件查询:
select *
from tbl_user
where id = 1; 排序查询:
select id,username
from tbl_user
order by id asc;这里asc代表升序,对应的desc代表降序
分组查询:
select avg(salary)
from tbl_salary
group by dept_id;select avg(salary)
from tbl_salary
group by dept_id
having avg(salary) > 100
order by avg(salary) asc;一般使用于运用场景avg max min sum
这里说说having和where的区别:
首先where这里不能使用在分组集合里面,其他场景都是用where
having只能对分组后的数据进行操作,后面跟上的是聚合函数(avg max min sum)
多表查询:
select u.id,s.name
from tbl_user u,tbl_salary s
where u.dept_id = s.id;这里u为tbl_user的别名,s为tbl_salary的别名
首先多表连接很容易照成数据冗余
比如两个集合为a{1,2,3},b{1,2,3},形成笛卡儿积就是两个集合相乘这样就有9条数据
这里使用u.dept = s.id;可以消除笛卡儿积,减少数据冗余
最后在谈一谈commit语句的作用:刚刚学的时候因为这个语句使得我花费很多时间:
commit只针对DML
DML(data manipulation language):需要提交的,比如执行insert,update,delete
DDL(data definition langage):不需要提交,比如执行create,select,alter
当你使用insert,update,delete的时候你立马查询是可以查询到数据的改变的,但是你使用其他方式在登录这个账号进行查询的时候其实是不能查询到的,所以但执行这些操作的时候需要commit操作就可以查询到了。














 6062
6062











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









