







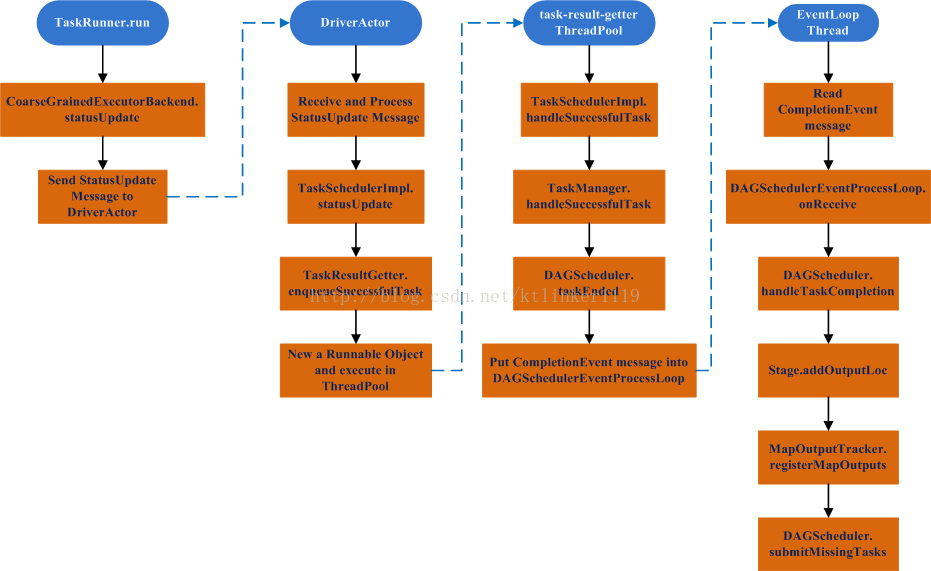
当ShuffleMapTask或ResultTask执行完成后,其结果会传递给Driver。
![]()
1. 返回流程
返回流程涉及Executor和Driver。
2. TaskRunner.run
override def run() {
......
try {
......
// Run the actual task and measure its runtime.
taskStart = System.currentTimeMillis()
val value = task.run(taskAttemptId = taskId, attemptNumber = attemptNumber)
val taskFinish = System.currentTimeMillis()
// If the task has been killed, let's fail it.
if (task.killed) {
throw new TaskKilledException
}
val resultSer = env.serializer.newInstance()
val beforeSerialization = System.currentTimeMillis()
val valueBytes = resultSer.serialize(value)
val afterSerialization = System.currentTimeMillis()
......
val directResult = new DirectTaskResult(valueBytes, accumUpdates, task.metrics.orNull)
val serializedDirectResult = ser.serialize(directResult)
val resultSize = serializedDirectResult.limit
// directSend = sending directly back to the driver
val serializedResult = {
if (maxResultSize > 0 && resultSize > maxResultSize) {
logWarning(s"Finished $taskName (TID $taskId). Result is larger than maxResultSize " +
s"(${Utils.bytesToString(resultSize)} > ${Utils.bytesToString(maxResultSize)}), " +
s"dropping it.")
ser.serialize(new IndirectTaskResult[Any](TaskResultBlockId(taskId), resultSize))
} else if (resultSize >= akkaFrameSize - AkkaUtils.reservedSizeBytes) {
val blockId = TaskResultBlockId(taskId)
env.blockManager.putBytes(
blockId, serializedDirectResult, StorageLevel.MEMORY_AND_DISK_SER)
logInfo(
s"Finished $taskName (TID $taskId). $resultSize bytes result sent via BlockManager)")
ser.serialize(new IndirectTaskResult[Any](blockId, resultSize))
} else {
logInfo(s"Finished $taskName (TID $taskId). $resultSize bytes result sent to driver")
serializedDirectResult
}
}
execBackend.statusUpdate(taskId, TaskState.FINISHED, serializedResult)
} catch {
......
} finally {
......
}
}
}
(1)调用Task.run开始Task计算,ShuffleMapTask的返回结果为MapStatus对象。MapStatus有两个实现:
CompressedMapStatus和HighlyCompressedMapStatus。MapStatus用于获取Map输出结果所在的BlockManager,以及各个输出分区的大小。两个实现类主要用来对输出分区大小进行压缩处理。
(2)将Task执行结果进行序列化处理;
(3)创建DirectTaskResult对象,封装序列化后的Task结果;
(4)序列化
DirectTaskResult对象;
(5)依据序列化
DirectTaskResult对象的大小,对序列化结果做不同处理。如果结果大小超过maxResultSize,则丢弃;如果结果大小超过akka的FrameSize,则将结果作为一个Block存储在BlockManager中
(6)调用CoarseGrainedExecutorBackend的statusUpdate方法,该方法将向DriverActor发送StatusUpdate消息。
3. DriverActor处理StatusUpdate消息
case StatusUpdate(executorId, taskId, state, data) =>
scheduler.statusUpdate(taskId, state, data.value)
if (TaskState.isFinished(state)) {
executorDataMap.get(executorId) match {
case Some(executorInfo) =>
executorInfo.freeCores += scheduler.CPUS_PER_TASK
makeOffers(executorId)
case None =>
// Ignoring the update since we don't know about the executor.
logWarning(s"Ignored task status update ($taskId state $state) " +
"from unknown executor $sender with ID $executorId")
}
}
(1)调用TaskSchedulerImpl.statusUpdate方法;
(2)修改状态。
4. TaskSchedulerImpl.statusUpdate
activeTaskSets.get(taskSetId).foreach { taskSet =>
if (state == TaskState.FINISHED) {
taskSet.removeRunningTask(tid)
taskResultGetter.enqueueSuccessfulTask(taskSet, tid, serializedData)
} else if (Set(TaskState.FAILED, TaskState.KILLED, TaskState.LOST).contains(state)) {
taskSet.removeRunningTask(tid)
taskResultGetter.enqueueFailedTask(taskSet, tid, state, serializedData)
}
}
调用TaskResultGetter.enqueueSuccessfulTask方法,该方法将创建Runnable对象,交由线程池来执行。Runnable对象的主要工作是获取Task计算的结果,然后调用TaskSchedulerImpl.handleSuccessfulTask方法。
从流程中看出,Runnable对象执行线程会创建CompletionEvent对象,并压入DAGSchedulerEventProcessLoop的消息队列,由事件循环线程读取该消息并调用DAGSchedulerEventProcessLoop.onReceive方法进行消息分发。
5. DAGSchedulerEventProcessLoop.onReceive
override def onReceive(event: DAGSchedulerEvent): Unit = event match {
......
case completion @ CompletionEvent(task, reason, _, _, taskInfo, taskMetrics) =>
dagScheduler.handleTaskCompletion(completion)
.......
}
调用DAGScheduler.handleTaskCompletion处理CompletionEvent消息。
6. DAGScheduler.handleTaskCompletion
只看task执行成功的情况,分为两种Task结果。
6.1. ResultTask结果
case rt: ResultTask[_, _] =>
stage.resultOfJob match {
case Some(job) =>
if (!job.finished(rt.outputId)) {
......
// taskSucceeded runs some user code that might throw an exception. Make sure
// we are resilient against that.
try {
job.listener.taskSucceeded(rt.outputId, event.result)
} catch {
case e: Exception =>
// TODO: Perhaps we want to mark the stage as failed?
job.listener.jobFailed(new SparkDriverExecutionException(e))
}
}
case None =>
logInfo("Ignoring result from " + rt + " because its job has finished")
}
(1)修改状态;
(2)调用JobWaiter.taskSucceeded方法,通知JobWaiter任务完成。
6.2. ShuffleMapTask结果
case smt: ShuffleMapTask =>
......
if (failedEpoch.contains(execId) && smt.epoch <= failedEpoch(execId)) {
logInfo("Ignoring possibly bogus ShuffleMapTask completion from " + execId)
} else {
stage.addOutputLoc(smt.partitionId, status)
}
if (runningStages.contains(stage) && stage.pendingTasks.isEmpty) {
markStageAsFinished(stage)
logInfo("looking for newly runnable stages")
logInfo("running: " + runningStages)
logInfo("waiting: " + waitingStages)
logInfo("failed: " + failedStages)
if (stage.shuffleDep.isDefined) {
// We supply true to increment the epoch number here in case this is a
// recomputation of the map outputs. In that case, some nodes may have cached
// locations with holes (from when we detected the error) and will need the
// epoch incremented to refetch them.
// TODO: Only increment the epoch number if this is not the first time
// we registered these map outputs.
mapOutputTracker.registerMapOutputs(
stage.shuffleDep.get.shuffleId,
stage.outputLocs.map(list => if (list.isEmpty) null else list.head).toArray,
changeEpoch = true)
}
clearCacheLocs()
if (stage.outputLocs.exists(_ == Nil)) {
// Some tasks had failed; let's resubmit this stage
// TODO: Lower-level scheduler should also deal with this
logInfo("Resubmitting " + stage + " (" + stage.name +
") because some of its tasks had failed: " +
stage.outputLocs.zipWithIndex.filter(_._1 == Nil).map(_._2).mkString(", "))
submitStage(stage)
} else {
val newlyRunnable = new ArrayBuffer[Stage]
for (stage <- waitingStages) {
logInfo("Missing parents for " + stage + ": " + getMissingParentStages(stage))
}
for (stage <- waitingStages if getMissingParentStages(stage) == Nil) {
newlyRunnable += stage
}
waitingStages --= newlyRunnable
runningStages ++= newlyRunnable
for {
stage <- newlyRunnable.sortBy(_.id)
jobId <- activeJobForStage(stage)
} {
logInfo("Submitting " + stage + " (" + stage.rdd + "), which is now runnable")
submitMissingTasks(stage, jobId)
}
}
}
}
(1)调用Stage.addOutputLoc方法记录map输出结果;
(2)判断Stage是否执行完,若是则执行下面的操作;
(3)标记Stage为结束状态;
(4)调用MapOutputTracker.registerMapOuputs记录Stage的所有map输出结果;
(5)若Stage包含失败的Task,则重新提交Stage;
(6)否则开始从waitingStages获取可执行的Stages,并循环调用DAGScheduler.submitMissingTasks提交每个Stage。














 973
973











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









