







本文主要讲述在standalone模式下,从bin/spark-submit脚本到SparkSubmit类启动应用程序主类的过程。
![]()
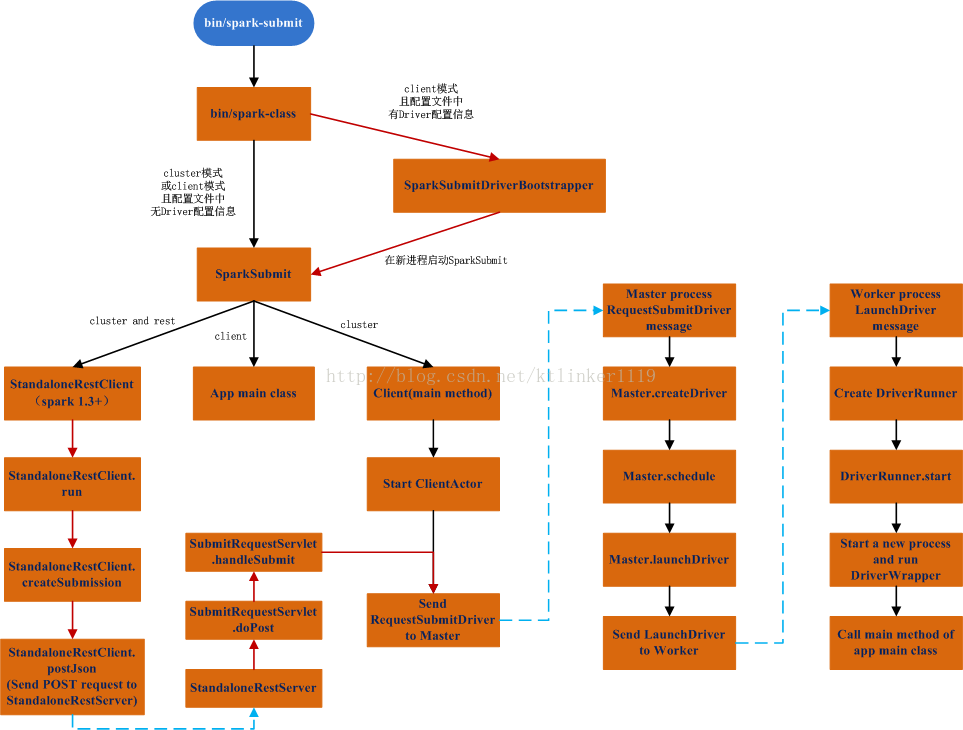
1 调用流程图
2 启动脚本
2.1 bin/spark-submit
# For client mode, the driver will be launched in the same JVM that launches
# SparkSubmit, so we may need to read the properties file for any extra class
# paths, library paths, java options and memory early on. Otherwise, it will
# be too late by the time the driver JVM has started.
if [[ "$SPARK_SUBMIT_DEPLOY_MODE" == "client" && -f "$SPARK_SUBMIT_PROPERTIES_FILE" ]]; then
# Parse the properties file only if the special configs exist
contains_special_configs=$(
grep -e "spark.driver.extra*\|spark.driver.memory" "$SPARK_SUBMIT_PROPERTIES_FILE" | \
grep -v "^[[:space:]]*#"
)
if [ -n "$contains_special_configs" ]; then
export SPARK_SUBMIT_BOOTSTRAP_DRIVER=1
fi
fi
exec "$SPARK_HOME"/bin/spark-class org.apache.spark.deploy.SparkSubmit "${ORIG_ARGS[@]}"
(1)在client模式,且spark属性配置文件中包含spark.driver*等配置信息,则export SPARK_SUBMIT_BOOTSTRAP_DRIVER=1;
(2)调用bin/spark-class;
2.2 bin/spark-class
# In Spark submit client mode, the driver is launched in the same JVM as Spark submit itself.
# Here we must parse the properties file for relevant "spark.driver.*" configs before launching
# the driver JVM itself. Instead of handling this complexity in Bash, we launch a separate JVM
# to prepare the launch environment of this driver JVM.
if [ -n "$SPARK_SUBMIT_BOOTSTRAP_DRIVER" ]; then
# This is used only if the properties file actually contains these special configs
# Export the environment variables needed by SparkSubmitDriverBootstrapper
export RUNNER
export CLASSPATH
export JAVA_OPTS
export OUR_JAVA_MEM
export SPARK_CLASS=1
shift # Ignore main class (org.apache.spark.deploy.SparkSubmit) and use our own
exec "$RUNNER" org.apache.spark.deploy.SparkSubmitDriverBootstrapper "$@"
else
# Note: The format of this command is closely echoed in SparkSubmitDriverBootstrapper.scala
if [ -n "$SPARK_PRINT_LAUNCH_COMMAND" ]; then
echo -n "Spark Command: " 1>&2
echo "$RUNNER" -cp "$CLASSPATH" $JAVA_OPTS "$@" 1>&2
echo -e "========================================\n" 1>&2
fi
exec "$RUNNER" -cp "$CLASSPATH" $JAVA_OPTS "$@"
fi
(1)如果$SPARK_SUBMIT_BOOTSTRAP_DRIVER不为空,则从参数列表中移除SparkSubmit,启动SparkSubmitDriverBootstrapper;SparkSubmitDriverBootstrapper最终会调用SparkSubmit;
(2)直接启动SparkSubmit;
3 应用程序主类的启动方式
应用程序主类有三种启动方式:
(1)有SparkSubmit直接启动;
(2)在Worker节点创建新进程DriverWrapper,由它来启动应用程序主类;
(3)通过StandaloneRestClient向StandaloneRestServer消息,后面的步骤同第2中方式(这种方式是spark1.3新增)。
4 SparkSubmit
4.1 main
def main(args: Array[String]): Unit = {
val appArgs = new SparkSubmitArguments(args)
if (appArgs.verbose) {
printStream.println(appArgs)
}
appArgs.action match {
case SparkSubmitAction.SUBMIT => submit(appArgs)
case SparkSubmitAction.KILL => kill(appArgs)
case SparkSubmitAction.REQUEST_STATUS => requestStatus(appArgs)
}
}
(1)创建SparkSubmitArguments对象,并解析参数来初始化对象成员;
(2)这里只分析submit过程。
4.2 SparkSubmitArguments
此类封装了Spark参数。
// Set parameters from command line arguments
parseOpts(args.toList)
// Populate `sparkProperties` map from properties file
mergeDefaultSparkProperties()
// Use `sparkProperties` map along with env vars to fill in any missing parameters
loadEnvironmentArguments()
validateArguments()
(1)解析命令行参数;
(2)合并属性文件(默认为spark-defaults.conf)中配置的参数;
(3)loadEnvironmentArguments方法会设置action参数,默认为SUBMIT;
// Action should be SUBMIT unless otherwise specified
action = Option(action).getOrElse(SUBMIT)
(4)验证参数,不同的action有不同的验证方法;
/** Ensure that required fields exists. Call this only once all defaults are loaded. */
private def validateArguments(): Unit = {
action match {
case SUBMIT => validateSubmitArguments()
case KILL => validateKillArguments()
case REQUEST_STATUS => validateStatusRequestArguments()
}
}4.3 Spark属性参数优先级
spark提供了多种设置属性的方式(优先级从高到底):
(1)在应用程序中设置属性参数;
(2)在命令行中设置参数;
(3)在配置文件中设置参数(默认为spark-defaults.conf);
(4)Spark提供的默认属性值。
4.4 SparkSubmit.submit
val (childArgs, childClasspath, sysProps, childMainClass) = prepareSubmitEnvironment(args)
def doRunMain(): Unit = {
if (args.proxyUser != null) {
......
} else {
runMain(childArgs, childClasspath, sysProps, childMainClass, args.verbose)
}
}
// In standalone cluster mode, there are two submission gateways:
// (1) The traditional Akka gateway using o.a.s.deploy.Client as a wrapper
// (2) The new REST-based gateway introduced in Spark 1.3
// The latter is the default behavior as of Spark 1.3, but Spark submit will fail over
// to use the legacy gateway if the master endpoint turns out to be not a REST server.
if (args.isStandaloneCluster && args.useRest) {
try {
printStream.println("Running Spark using the REST application submission protocol.")
doRunMain()
} catch {
// Fail over to use the legacy submission gateway
case e: SubmitRestConnectionException =>
printWarning(s"Master endpoint ${args.master} was not a REST server. " +
"Falling back to legacy submission gateway instead.")
args.useRest = false
submit(args)
}
// In all other modes, just run the main class as prepared
} else {
doRunMain()
}
(1)prepareSubmitEnvironment其中一个职责就是设置childMainClass,它决定了应用程序主类的调用方式;
(2)调用doRunMain内部方法,它将调用runMain方法。
4.4.1 SparkSubmit.prepareSubmitEnvironment
(0)设置应用程序部署方式:
// Set the deploy mode; default is client mode
var deployMode: Int = args.deployMode match {
case "client" | null => CLIENT
case "cluster" => CLUSTER
case _ => printErrorAndExit("Deploy mode must be either client or cluster"); -1
}
(1)将childMainClass设置为应用程序主类名:
// In client mode, launch the application main class directly
// In addition, add the main application jar and any added jars (if any) to the classpath
if (deployMode == CLIENT) {
childMainClass = args.mainClass
if (isUserJar(args.primaryResource)) {
childClasspath += args.primaryResource
}
if (args.jars != null) { childClasspath ++= args.jars.split(",") }
if (args.childArgs != null) { childArgs ++= args.childArgs }
}
(2)将childMainClass设置为StandaloneRestClient或Client:
// In standalone cluster mode, use the REST client to submit the application (Spark 1.3+).
// All Spark parameters are expected to be passed to the client through system properties.
if (args.isStandaloneCluster) {
if (args.useRest) {
childMainClass = "org.apache.spark.deploy.rest.StandaloneRestClient"
childArgs += (args.primaryResource, args.mainClass)
} else {
// In legacy standalone cluster mode, use Client as a wrapper around the user class
childMainClass = "org.apache.spark.deploy.Client"
if (args.supervise) { childArgs += "--supervise" }
Option(args.driverMemory).foreach { m => childArgs += ("--memory", m) }
Option(args.driverCores).foreach { c => childArgs += ("--cores", c) }
childArgs += "launch"
childArgs += (args.master, args.primaryResource, args.mainClass)
}
if (args.childArgs != null) {
childArgs ++= args.childArgs
}
}
(3)将
childMainClass设置为org.apache.spark.deploy.yarn.Client:
// In yarn-cluster mode, use yarn.Client as a wrapper around the user class
if (isYarnCluster) {
childMainClass = "org.apache.spark.deploy.yarn.Client"
......4.4.2 SparkSubmit.runMain
(0)方法签名:
private def runMain(
childArgs: Seq[String],
childClasspath: Seq[String],
sysProps: Map[String, String],
childMainClass: String,
verbose: Boolean): Unit
(1)可在命令行中设置verbose参数,将runMain的参数输出到控制台:
if (verbose) {
printStream.println(s"Main class:\n$childMainClass")
printStream.println(s"Arguments:\n${childArgs.mkString("\n")}")
printStream.println(s"System properties:\n${sysProps.mkString("\n")}")
printStream.println(s"Classpath elements:\n${childClasspath.mkString("\n")}")
printStream.println("\n")
}
(2)加载jar
for (jar <- childClasspath) {
addJarToClasspath(jar, loader)
}
(3)将Spark属性参数设置为系统属性(很多地方采用从System属性中获取参数):
for ((key, value) <- sysProps) {
System.setProperty(key, value)
}
(4)创建childMainClass的类对象:
try {
mainClass = Class.forName(childMainClass, true, loader)
} catch {
...
}
(5)获取main方法对象:
val mainMethod = mainClass.getMethod("main", new Array[String](0).getClass)
(6)调用main方法:
try {
mainMethod.invoke(null, childArgs.toArray)
} catch {
case t: Throwable =>
throw findCause(t)
}
到此,就已经调用prepareSubmitEnvironment方法设置的childMainClass类了。
childMainClass值为:
- 应用程序主类名;
- org.apache.spark.deploy.rest.StandaloneRestClient;
- org.apache.spark.deploy.Client;
- org.apache.spark.deploy.yarn.Client。















 197
197











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









