









1、引言
在进行自然语言处理(NLP)处理的时候,基本的操作无外乎分词、分类、聚类、命名实体识别、规则过滤、摘要提取、关键字提取、词性标注、拼音标注等。
分类通用的做法就是根据提供的语言库自学习识别成对应的分类。现有的复旦大学提供的语料库有20种分类。(参考:http://www.nlpir.org/?action-viewnews-itemid-103),网上也有提供更多种分类的。
分词网上比较NB的几个实验室有:
1)、背景理工大学张华平副教授的 nlp 自然语言处理与信息共享检索平台http://ictclas.nlpir.org/nlpir/。
2)、哈工大“语言云” 以哈工大社会计算与信息检索研究中心研发的 “语言技术平台(LTP)” http://www.ltp-cloud.com/demo/。
(本段摘自网络)文本分类语料库(复旦)测试语料由复旦大学李荣陆提供。answer.rar为测试语料,共9833篇文档;train.rar为训练语料,共9804篇文档,分为20个类别。训练语料和测试语料基本按照1:1的比例来划分。收集工作花费了不少人力和物力,所以请大家在使用时尽量注明来源(复旦大学计算机信息与技术系国际数据库中心自然语言处理小组)。文件较大(训练测试各50多兆)。
实际项目中需要根据自己的需要进行定制处理。
2、需求点
结合口头需求,我整理出下面的两个核心需求点。
需求1:以中文形式输出语料库中包含的全部文件类型到一个类型文件outtype.txt。
需求2:将预料库中的所有文件以[EndEnd]结尾并合并,导出到数据文件outdata.txt。
其中文件路径和文件个数如下,累计文件综合近1.3GB。
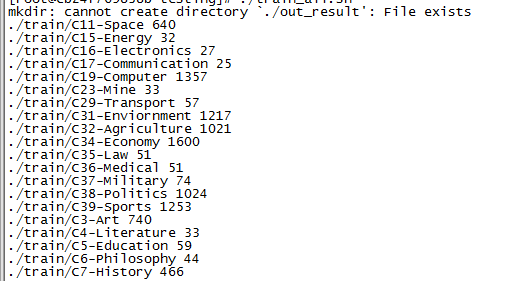
第一列为文件类型,第二列为文件的个数。
3、需求分析
需求1:
1)每个类别命名的文件夹下存放的就是该类别的文件。统计下该类别下文件的个数cnt。
2)内层循环cnt次,文件名追加输出到一个文件。
3)外层循环20次(一共20类预料)即可。
需求2:
1)每个文件末尾追加[EndEnd];
2) 便利每个路径下的文件合成一个文件。
细节注意事项:需求1的类别和需求2的以[EndEnd]结束的文件要一一对应,一旦对应偏了,整个工作都会白费。
4、脚本实现
#author:http://blog.csdn.net/laoyang360
#date:20160304 pm22:38
#version:V0.1
#!/bin/bash
#the dir for use
DIR_NAME=./train
OUT_RESULT=./out_result
CNT_FILE=files_cnt.txt
NAME_FILE=all_file_dir.txt
TOTAL_TYPES_FILE=$OUT_RESULT/outtype.txt
TOTAL_TYPES_BAK_FILE=total_types_bak.txt
TOTAL_OUTFILE=$OUT_RESULT/outdata.txt
#clear the existing contents
function initialize()
{
mkdir $OUT_RESULT
cat /dev/null > $CNT_FILE
cat /dev/null > $NAME_FILE
cat /dev/null > $TOTAL_TYPES_FILE
cat /dev/null > $TOTAL_OUTFILE;
}
#list all files and stat file cnts
function list_all_files()
{
for file in ` ls $1 | sort`
do
if [ -d $1"/"$file ]
then
file_cnt=`ls $1"/"$file | wc -l`
echo $1"/"$file $file_cnt >> $CNT_FILE
list_all_files $1"/"$file
else
echo $1"/"$file >> $NAME_FILE
fi
done
}
#construct files sort by types
function constrcut_type_files()
{
line_cnt=1;
mkdir ./out_put
cat $CNT_FILE | while read line
do
CNT_NO_FILE=${CNT_FILE}_${line_cnt}
#echo "linecnt="$line_cnt;
echo $line > ./out_put/$CNT_NO_FILE;
#first column of every line
type_name=` awk '{print $1}' ./out_put/$CNT_NO_FILE `
#sencond column of every line, nums for print
type_cnt=` awk '{print $2}' ./out_put/$CNT_NO_FILE `
echo $type_name $type_cnt
#construct files
for((curnum=0;curnum<$type_cnt;curnum++))
{
echo $type_name >> $TOTAL_TYPES_FILE
}
line_cnt=$((line_cnt+1));
done;
rm -rf ./out_put
}
#format types_files
function typefile_format()
{
#bak for source
cp -f $TOTAL_TYPES_FILE $TOTAL_TYPES_BAK_FILE
sed -i 's#./train/##g' $TOTAL_TYPES_FILE;
sed -i 's#C4-Literature#文学#g' $TOTAL_TYPES_FILE; #17
sed -i 's#C5-Education#教育#g' $TOTAL_TYPES_FILE; #18
sed -i 's#C6-Philosophy#哲学#g' $TOTAL_TYPES_FILE; #19
sed -i 's#C15-Energy#能源#g' $TOTAL_TYPES_FILE; #2
sed -i 's#C16-Electronics#电子#g' $TOTAL_TYPES_FILE; #3 1240
sed -i 's#C17-Communication#通讯#g' $TOTAL_TYPES_FILE; #4
sed -i 's#C29-Transport#运输#g' $TOTAL_TYPES_FILE; #7
sed -i 's#C35-Law#法学#g' $TOTAL_TYPES_FILE; #11
sed -i 's#C36-Medical#医学#g' $TOTAL_TYPES_FILE; #12
sed -i 's#C37-Military#军事#g' $TOTAL_TYPES_FILE; #13
#sed -i 's#C3-Art#艺术#g' $TOTAL_TYPES_FILE; #16 763
#sed -i 's#C7-History#历史#g' $TOTAL_TYPES_FILE #20
#sed -i 's#C11-Space#空间#g' $TOTAL_TYPES_FILE; #1
#sed -i 's#C19-Computer#电脑#g' $TOTAL_TYPES_FILE; #5
#sed -i 's#C23-Mine#矿#g' $TOTAL_TYPES_FILE; #6
#sed -i 's#C31-Enviornment#环境#g' $TOTAL_TYPES_FILE; #8
#sed -i 's#C32-Agriculture#农业#g' $TOTAL_TYPES_FILE; #9
#sed -i 's#C34-Economy#经济#g' $TOTAL_TYPES_FILE; #10 1623
#sed -i 's#C38-Politics#政治#g' $TOTAL_TYPES_FILE; #14 1047
#sed -i 's#C39-Sports#体育#g' $TOTAL_TYPES_FILE; #15
}
#GBK2UTF8, ./train changed to utf-8 format
function GBK2UTF8()
{
#for all files in ./train
` find $DIR_NAME -type d -exec mkdir -p utf/{} \; `
` find $DIR_NAME -type f -exec iconv -f GBK -t UTF-8 {} -o utf/{} >/dev/null 2>&1 \; `
rm -rf $DIR_NAME;
mv utf/* ./;
}
#new and "[EndEnd]" at the end of every file
function allfiles_addend()
{
icnt=0;
cat $NAME_FILE | while read line
do
echo "[EndEnd]" >> $line;
icnt=$((icnt+1));
#echo "icnt ="$icnt;
done;
}
#Merage all files together
function merge_all_files()
{
#find $DIR_NAME -type f -exec cat {} \;>all_files_together.txt
icnt=0;
cat $NAME_FILE | while read line
do
cat $line >> $TOTAL_OUTFILE;
icnt=$((icnt+1));
echo "icnt ="$icnt;
done;
}
#executing for use
initialize;
list_all_files $DIR_NAME;
constrcut_type_files;
typefile_format;
GBK2UTF8;
allfiles_addend;
merge_all_files;5、小结
1)Shell脚本写的多了也就熟悉了。
2)今天起包括后期,所有工程式的Shell脚本都归档、整理思路,形成《懒人Shell脚本》系列文章。前面已经有一篇:
http://blog.csdn.net/laoyang360/article/details/49834859
3)Shell脚本有明显C、C++语言的痕迹,慢慢过渡。脚本毕竟简练为妙!
4)近期浏览blog也发现了Python在爬虫方面的优势,有时间的话会学习整理。
6、GitHub下载地址:
https://github.com/laoyang360/corpus_process
2016-3-4 pm 22:55 思于家中床前
作者:铭毅天下
转载请标明出处,原文地址:http://blog.csdn.net/laoyang360/article/details/50806028
如果感觉本文对您有帮助,请点击‘顶’支持一下,您的支持是我坚持写作最大的动力,谢谢!
















 217
217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











