







免责声明:本文章来源网站各种博客汇总,所有内容都注明出处
1,首先要了解SEL的简单使用
SEL就是对方法的一种包装。包装的SEL类型数据它对应相应的方法地址,找到方法地址就可以调用方法。在内存中每个类的方法都存储在类对象中,每个方法都有一个与之对应的SEL类型的数据,根据一个SEL数据就可以找到对应的方法地址,进而调用方法。
以下转载:http://mobile.51cto.com/hot-431728.htm
- @interface Person : NSObject
- + (void)test1;
- - (void)test2;
- @end
- // 根据.h文件中定义的Person类和方法 执行完这行代码 在内存中如下
- Person *person = [[Person alloc] init];
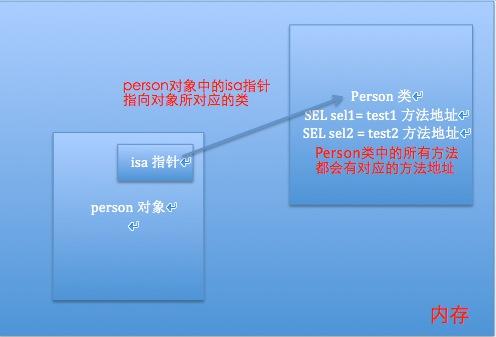
SEL就是对方法的一种包装。包装的SEL类型数据它对应相应的方法地址,找到方法地址就可以调用方法
1.方法的存储位置
- 在内存中每个类的方法都存储在类对象中
- 每个方法都有一个与之对应的SEL类型的数据
- 根据一个SEL数据就可以找到对应的方法地址,进而调用方法
- SEL类型的定义: typedef struct objc_selector *SEL
2.SEL对象的创建
- SEL s1 = @selector(test1); // 将test1方法包装成SEL对象
- SEL s2 = NSSelectorFromString(@"test1"); // 将一个字符串方法转换成为SEL对象
3.SEL对象的其他用法
- // 将SEL对象转换为NSString对象
- NSString *str = NSStringFromSelector(@selector(test));
- Person *p = [Person new];
- // 调用对象p的test方法
- [p performSelector:@selector(test)];
- /******************************* Person.h文件 **********************************/
- #import <Foundation/Foundation.h>
- @interface Person : NSObject
- - (void)test1;
- - (void)test2:(NSString *)str;
- @end
- /******************************* Person.m文件 **********************************/
- #import "Person.h"
- @implementation Person
- - (void)test1
- {
- NSLog(@"无参数的对象方法");
- }
- - (void)test2:(NSString *)str
- {
- NSLog(@"带有参数的方法%@",str);
- }
- @end
- /******************************* main.m文件 **********************************/
- #import "Person.h"
- #import <Foundation/Foundation.h>
- /*
- 调用方法有两种方式:
- 1.直接通过方法名来调用
- 2.间接的通过SEL数据来调用
- */
- int main(int argc, const char * argv[])
- {
- Person *person = [[Person alloc] init];
- // 1.执行这行代码的时候会把test2包装成SEL类型的数据
- // 2.然后根据SEL数据找到对应的方法地址(比较耗性能但系统会有缓存)
- // 3.在根据方法地址调用对应的方法
- [person test1];
- // 将方法直接包装成SEL数据类型来调用 withObject:传入的参数
- [person performSelector:@selector(test1)];
- [person performSelector:@selector(test2:) withObject:@"传入参数"];
- return 0;
- }
以下转载:
http://www.cnblogs.com/studentdeng/archive/2011/10/06/2199873.html
object c 里面有一个非常有趣的设计,如果之前了解过c++的家伙们,对object c 中的把传统的调用函数变成了向这个类发送消息,这个过程总是令人琢磨不透,在实际过程中遇到的crash也很难调试清楚。这篇就要详细的解释消息这个家伙。当然,消息这个涉及的东西实在是太多了。这篇先简单介绍一下。
message(消息):message的具体定义很难说,因为并没有真正的代码描述,简单的讲message 是一种抽象,包括了函数名+参数列表,他并没有实际的实体存在。
method(方法):method是真正的存在的代码。如:- (int)meaning { return 42; }
selector: selector 通过SEL类型存在,描述一个特定的method or message。在实际编程中,可以通过selector来检索函数等操作。
我不知道上面这种描述有多少人可以明白,因为我觉得这3个每个人都可以有自己的看法,在了解object c message 的整个过程之后。
让我们从一个简单的例子开始。当我们写好如下的代码时
- (
int
)foo:(
NSString
*)str { ...}
|
编译器事实上转成了下面的样子
int
XXXX_XXXX_foo_(SomeClass *
self
,
SEL
_cmd,
NSString
*str) { ...}
|
当我们写下发送消息的代码如
int
result = [obj foo:@
"hello"
];
|
实际上变成了
int
result = ((
int
(*)(
id
,
SEL
,
NSString
*))objc_msgSend)(obj,
@selector
(foo:), @
"hello"
);
|
而 objc_msgSend 是一个我们非常熟悉的C函数定义 id objc_msgSend(id self, SEL _cmd,...);
那么,object c 发送消息就变成了一个表面上看似容易理解的C函数调用了,这里有必要解释一下几个名词
id:很多地方说id是一个void *的指针。事实上,id 其实是这样子的
typedef
struct
objc_object {
Class isa;
} *
id
;
|
也就是说。id其实是一个可以指向任何一个object指针(只要结构体中包含isa 指针) 。
SEL:SEL 如果很粗鲁(我不知道改用什么其他词汇更容易描述)的讲,就是一个char * 的指针。因为你可以这样简单粗暴的测试
SEL
selector =
@selector
(message);
//@selector不是函数调用,只是给这个坑爹的编译器的一个提示
NSLog
(@
"%s"
, (
char
*)selector);
//print message
|
注:这里之所以说粗鲁,是因为,这个的定义和object runtime 的具体实现息息相关,未来很可能改变,而这些定义也是没有文档化的,后面还会详细介绍SEL的具体实现。因为这里有不少为了提高效率而做的优化。
不知道有没有人惊呼这个问题。特别是如果之前从事C++的家伙们。传统的C++ 编译器在处理函数上,为了支持函数重载。使用了一种函数别名的方式如
int
foo(
int
a);
|
变成了 XXX_1_foo_int (具体的形式没有意义,核心在于,编译器生成的函数签名包括函数名,参数类型,参数个数)。
但我们的SEL 仅仅是函数名而已。
有了这些知识做铺垫,原谅我在把这个东东再搬出来
int
result = ((
int
(*)(
id
,
SEL
,
NSString
*))objc_msgSend)(obj,
@selector
(foo:), @
"hello"
);
|
那么,作为程序员,我们就为这个而疯狂了,因为编译器无法根据id 和SEL 获得完整的函数签名,编译器对参数个数和类型,完全不知道。那么他如何能过做到识别这些并找到正确的代码呢?
事实上这个头痛的问题,编译器做了一个非常坑爹的事情,就是“ it cheats” ,他假装能够通过函数名,就能确定正确的代码。通过扫描之前的函数声明来做,如果没有找到,编译器就认为这是一个运行时(runtime)的函数而直接略过。而这也就导致了object c 在处理有相同函数名和参数个数但类型不同的函数时,非常的弱。如
-(
void
)setWidth:(
int
)width;
-(
void
)setWidth:(
double
)width;
|
这样的函数则被认为是一种编译错误,而这最终导致了一个非常非常奇怪的object c 特色的函数命名
-(
void
)setWidthIntValue:(
int
)width;
-(
void
)setWidthDoubleValue:(
double
)width;
|
注:这样的函数命名的好坏,只能说是因人而异的,站在我的角度来讲。object c 的这种命名实在是太臃肿了,这种冗长的名字让人感到作呕而没有任何美感。当然,这样的命名的确可以避免很多的错误,比如因C++ 函数重载而引起的人为上的小失误,而且减少了理解函数的负担。总有利弊,需要平衡:P,不过,我还是不喜欢object c 编译器,因为他彻底阻挡了你的想法,至于为什么这样设计,我的理解是为了runtime,在这里为了性能而做了妥协,具体原因,后面再讲。
popup our brain stack
objc_msgSend 这里传入了 class 指针 self 函数名SEL 已经后面通过C的不定参数传入的参数。通过这些条件。就像之前的C++函数那样,需要查表,并找到相应函数的位置,然后call xxxxx。那么。object c 是如何找到这些函数的真实地址呢? 之前有篇简单描述C++类函数布局的,有兴趣的可以对比的看。
为了解释这些这个过程,我们有需要介入一些名词了。
object c 2 的
typedef
struct
method_list_t {
uint32_t entsize_NEVER_USE;
// low 2 bits used for fixup markers
uint32_t count;
struct
method_t first;
} method_list_t;
typedef
struct
method_t {
SEL
name;
const
char
*types;
IMP imp;
} method_t;
|
method就是这么简单, 一个函数名SEL 一个包括的参数类型和返回类型的type 最后加一个IMP 而IMP 就是一个函数指针,指向我们真正的代码位置
typedef
id
(*IMP)(
id
,
SEL
, ...);
|
那么objc_msgSend 做的事情,就是通过我们传入的self 指针,找到class 的method_list 然后根据SEL 做比较,没有的话,就在super class 找,如此往复。直到找到匹配的SEL,然后,call imp。
那么,我们就发现了。如果object c 这样设计,调用函数的成本实在是太高了,相对传统的C函数调用。那么编译器和runtime又做了那些优化呢?有意思的事情开始了。
1、字符串比较
我们发现了SEL 就是简单的一个char* 字符串。那么,光是比较这一串字符,就可以让object c 慢的让人作呕了。那么我们就需要再认识一下我们的SEL了。
runtime 在实现selector是,实现了一个很大的Set,简单的说就是一个经过了杠杠优化过的hash表。而Set的特点就是唯一,也就是SEL是唯一的。那么对于字符串的比较仅仅需要比较他们的地址就可以了。犀利,速度上无语伦比,但是,有一个问题,就是数量增多会增大hash冲突而导致的性能下降(或是没有冲突,因为也可能用的是perfect hash)。但是不管使用什么样的方法加速,如果能够将总量减少,那将是最犀利的方法。那么,我们就不难理解,为什么SEL仅仅是函数名了。这样如
class A 有一个这样的method -(void)setWidth:(int)width;
而 classB 有一个这样的method -(void)setWidth:(double)width;
那么的selector 将指向同一个地方,使用同一个selector,如果真的需要在类中定义类似重载时,只能使用不同的函数名了。
但是,这样的优化,依然不能让人满意,因为,根据二八原则,我们真正执行的只是少数代码。那么。就有
2、cache
cache的原则就是缓存那些可能要执行的函数地址,那么下次调用的时候,速度就可以快速很多。这个和CPU的各种缓存原理相通。好吧,说了这么多了,再来认识几个名词
struct
objc_cache {
uintptr_t mask;
/* total = mask + 1 */
uintptr_t occupied;
cache_entry *buckets[1];
};
typedef
struct
{
SEL
name;
// same layout as struct old_method
void
*unused;
IMP imp;
// same layout as struct old_method
} cache_entry;
|
看这个结构,有没有搞错又是hash table。
objc_msgSend 首先在cache list 中找SEL 没有找到就在class 找,super class 找(当然super class 也有cache list)。
而cache的机制则非常复杂了,由于object c 是动态语言。所以,这里面还有很多的多线程同步问题,而这些锁又是效率的大敌,相关的内容已经远远超过本文讨论的范围。
popup our brain stack
有了上面的粗略的介绍,是时候让我们看看objc_msgSend 的真面目了,当然,对于这个家伙是和性能息息相关的东西,没有任何缘由的是用汇编来写的。这里面贴出x86的,原谅我已经把arm汇编忘记了(主要原因是arm汇编是老师教得,x86是自学的,没有听学校老师的 :P)。
/********************************************************************
*
* id objc_msgSend(id self, SEL _cmd,...);
*
********************************************************************/
ENTRY _objc_msgSend
CALL_MCOUNTER LP0
movl
self
(%esp), %eax
// check whether receiver is nil
testl %eax, %eax
je LMsgSendNilSelf
// receiver is non-nil: search the cache
CacheLookup WORD_RETURN, MSG_SEND, LMsgSendCacheMiss
movl $kFwdMsgSend, %edx
// flag word-return for _objc_msgForward
jmp *%eax
// goto *imp
// cache miss: go search the method lists
LMsgSendCacheMiss:
MethodTableLookup WORD_RETURN, MSG_SEND
movl $kFwdMsgSend, %edx
// flag word-return for _objc_msgForward
jmp *%eax
// goto *imp
// message sent to nil object: call optional handler and return nil
LMsgSendNilSelf:
EXTERN_TO_REG(__objc_msgNil,%eax)
movl 0(%eax), %eax
// load nil message handler
testl %eax, %eax
je LMsgSendDone
// if NULL just return and don't do anything
call *%eax
// call __objc_msgNil
xorl %eax, %eax
// Rezero $eax just in case
LMsgSendDone:
ret
LMsgSendExit:
END_ENTRY _objc_msgSend
|
注释非常的详细+代码本身自解释,不做赘述,汇编的可读性都比我写的强,牛到不需要解释的代码。
MethodTableLookup 跳到__class_lookupMethodAndLoadCache
/***********************************************************************
* lookUpMethod.
* The standard method lookup.
* initialize==NO tries to avoid +initialize (but sometimes fails)
* cache==NO skips optimistic unlocked lookup (but uses cache elsewhere)
* Most callers should use initialize==YES and cache==YES.
* May return _objc_msgForward_internal. IMPs destined for external use
* must be converted to _objc_msgForward or _objc_msgForward_stret.
**********************************************************************/
__private_extern__ IMP lookUpMethod(Class cls,
SEL
sel,
BOOL
initialize,
BOOL
cache)
{
Class curClass;
IMP methodPC =
NULL
;
Method meth;
BOOL
triedResolver =
NO
;
// Optimistic cache lookup
if
(cache) {
methodPC = _cache_getImp(cls, sel);
if
(methodPC)
return
methodPC;
}
// realize, +initialize, and any special early exit
methodPC = prepareForMethodLookup(cls, sel, initialize);
if
(methodPC)
return
methodPC;
// The lock is held to make method-lookup + cache-fill atomic
// with respect to method addition. Otherwise, a category could
// be added but ignored indefinitely because the cache was re-filled
// with the old value after the cache flush on behalf of the category.
retry:
lockForMethodLookup();
// Try this class's cache.
self note 这里再次查找cache 是因为有可能cache真的又有了,因为锁的原因
methodPC = _cache_getImp(cls, sel);
if
(methodPC)
goto
done;
// Try this class's method lists.
//self note 这个就是简单的在method 一个线性查找,因为我们仅仅是一个地址比较
meth = _class_getMethodNoSuper_nolock(cls, sel);
if
(meth) {
//我们找到了函数地址,那么添加到cachelist中
log_and_fill_cache(cls, cls, meth, sel);
methodPC = method_getImplementation(meth);
goto
done;
}
// Try superclass caches and method lists.
curClass = cls;
while
((curClass = _class_getSuperclass(curClass))) {
// Superclass cache.
meth = _cache_getMethod(curClass, sel, &_objc_msgForward_internal);
if
(meth) {
if
(meth != (Method)1) {
// Found the method in a superclass. Cache it in this class.
log_and_fill_cache(cls, curClass, meth, sel);
methodPC = method_getImplementation(meth);
goto
done;
}
else
{
// Found a forward:: entry in a superclass.
// Stop searching, but don't cache yet; call method
// resolver for this class first.
break
;
}
}
// Superclass method list.
meth = _class_getMethodNoSuper_nolock(curClass, sel);
if
(meth) {
log_and_fill_cache(cls, curClass, meth, sel);
methodPC = method_getImplementation(meth);
goto
done;
}
}
// No implementation found. Try method resolver once.
if
(!triedResolver) {
unlockForMethodLookup();
_class_resolveMethod(cls, sel);
// Don't cache the result; we don't hold the lock so it may have
// changed already. Re-do the search from scratch instead.
triedResolver =
YES
;
goto
retry;
}
// No implementation found, and method resolver didn't help.
// Use forwarding.
_cache_addForwardEntry(cls, sel);
methodPC = &_objc_msgForward_internal;
done:
unlockForMethodLookup();
// paranoia: look for ignored selectors with non-ignored implementations
assert(!(sel == (
SEL
)kIgnore && methodPC != (IMP)&_objc_ignored_method));
return
methodPC;
}
|
转载:http://www.cnblogs.com/studentdeng/archive/2011/10/16/2214164.html
我们知道Objective-C runtime 在处理selector时,是做一个unique hash set, 那么今天,我们看看这个set 是如何产生的。这篇文章参考了http://www.sealiesoftware.com/blog/archive/2009/09/01/objc_explain_Selector_uniquing_in_the_dyld_shared_cache.html
unique set的好处是,字符串的比较可以非常迅速,但是也带来一个棘手的问题,创建一个这样的集合,真的不容易。虽然我们能够在compiler和 link的时候保证我们程序中唯一,但是这还远远不够,因为我们并不是生活在真空中,我们的程序需要和各种各样的其他程序协同工作,那么如何能够在这种繁杂的各种情况下,保证唯一呢?
简单说,就是在程序A中,有一个@selector(customInit),但在程序A中引入了程序B,而B中也有一个@selector(customInit),那么,显然,我们需要修正这2个selector,使他们指向同一个内存地址,这样才能保证消息发送正确。
好吧,我们程序员又要惊呼了,这是一个非常非常大的开销,因为
1、我们只能在运行时做这些工作。
2、这些工作是不可能不绕过strcmp(创建hash表时,如果发生了冲突,我们为了保证绝对正确,只能strcmp)。
3、当我们修正之后,也意味着,我们浪费了空间,而实际上就是我们创建了一个更大的hashtable(元素越多,发生碰撞的概率越大,空间的开销越大),
4、代码段在被映射到内存地址空间时,都在可读地址空间上,那么修正,意味着我们又多做了copy-on-write,同样意味着更多的空间开销
5、事实上,这样的函数还非常多,那些界面库函数等等,几乎被所有app引用 e.g. init,initWithFrame:。
更多的空间,更多的比较,导致了性能下降,特别是在程序载入时。事实上,runtime 和os 为我们的selector unique 做了下面的优化,大体可以理解成2个部分
1、减少需要修正的selector 集合
之前,我们看到的只有一个hash set,在runtime 载入时创建,但是,现在我们有了2个set(这个set是在Snow Leopard被加入的)。
一个是之前我们知道的,另一个也是一个hash set 当然,特别的是,这是一个perfect hash set。
从之前的5条件中,我们知道了,这些常用的如系统库函数,cocoa.framework中的selector 几乎被所有app引用,而且,我们非常开心的看到了,这些函数,都是可以确定的固定集合。事实上,dyld(dynamic loader and linker),给我们build了一个dyld shared cache,而且是一个perfect hash。而这个被映射到了各种app内存地址空间,并被共享。当我们创建unique selector set 时,我们可以先查找这个perfect hash set,来判断,我们是不是需要动态扩展我们的程序自己的selector hash set。而且,由于是perfect hash,使我们能够拥有在最坏情况下常数时间的开销。
2、延迟加载
对于这个,我们已经不陌生了,不管是windows dll 中的延时加载,还是各种在linux中的动态模块的延时载入,原理都是一样的。这些工作,只有在认为是必要条件时,才被真正的加载并初始化。
说的实在是太空了,让我们来看代码吧。
当类被调用或是说在被发送消息之前,类,需要被初始化一下,做的工作就是一些,运行时必要的空间分配,初始化,修正selector,methodlist, propertylist,categorylist等等的工作,我们这里,只是关注selector部分。
prepareForMethodLookup->realizeClass –> methodizeClass->attachMethodLists->fixupMethodList.
经过一系列的东东,修正我们的methodlist时,我们需要将methodlist中的SEL 修正,而这个过程就是我们关注的select unique。
不知道,大家还记得不记得,上一篇讲的 method结构

typedef struct method_list_t { uint32_t entsize_NEVER_USE; // low 2 bits used for fixup markers uint32_t count; struct method_t first; } method_list_t; typedef struct method_t { SEL name; const char *types; IMP imp; } method_t
static void fixupMethodList(method_list_t *mlist, BOOL bundleCopy) { assert(!isMethodListFixedUp(mlist)); // fixme lock less in attachMethodLists ? sel_lock(); uint32_t m; for (m = 0; m < mlist->count; m++) { //studentdeng note:fixup selector and make sure selector unique method_t *meth = method_list_nth(mlist, m); SEL sel = sel_registerNameNoLock((const char *)meth->name, bundleCopy); meth->name = sel; if (sel == (SEL)kIgnore) { meth->imp = (IMP)&_objc_ignored_method; } } sel_unlock(); setMethodListFixedUp(mlist); }
sel_registerNameNoLock->__sel_registerName
static SEL __sel_registerName(const char *name, int lock, int copy) { SEL result = 0; if (lock) rwlock_assert_unlocked(&selLock); else rwlock_assert_writing(&selLock); if (!name) return (SEL)0; result = _objc_search_builtins(name); //studentdeng note:这里就是查找perfect hash set build by dyld cache if (result) return result; if (lock) rwlock_read(&selLock); if (_objc_selectors) { result = __objc_sel_set_get(_objc_selectors, (SEL)name); //studentdeng note: 这里就是查找我们程序自己的hash set } if (lock) rwlock_unlock_read(&selLock); if (result) return result; // No match. Insert. if (lock) rwlock_write(&selLock); if (!_objc_selectors) { _objc_selectors = __objc_sel_set_create(NUM_NONBUILTIN_SELS); } if (lock) { // Rescan in case it was added while we dropped the lock result = __objc_sel_set_get(_objc_selectors, (SEL)name); } if (!result) { result = (SEL)(copy ? _strdup_internal(name) : name); __objc_sel_set_add(_objc_selectors, result); #if defined(DUMP_UNKNOWN_SELECTORS) printf("\t\"%s\",\n", name); #endif } if (lock) rwlock_unlock_write(&selLock); return result; }
牛b的代码,从来都是自解释的。














 310
310











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









