







1、Python编码转换
在python2.7中,一般我们在编辑代码时默认的是utf-8编码方式,但是我们如果希望输出中文的话就需要做相应的处理。我们通过以下的例子来说明:
例如: 我们要打印输出“我爱中国”这四个字
# -*- coding:utf-8 -*-
#我们先这样写
print('我爱中国')执行代码之后我们会发现是这样的结果:
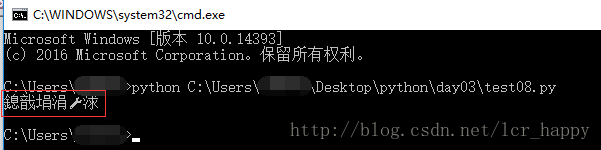
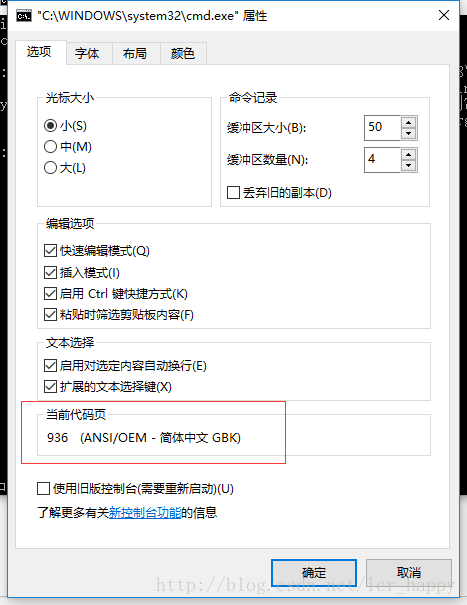
原因是因为在解释器下采用的是GBK编码方式,我们可以在cmd界面下单击右键点击属性查看。
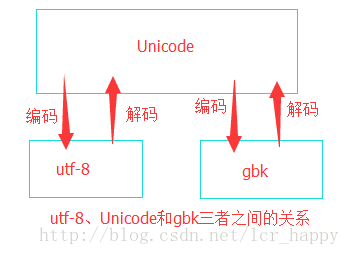
因此我们要做些改动。事实上,utf-8,unicode和gbk三者的关系是这样。
改动之后的代码是这样:
# -*- coding:utf-8 -*-
#默认为utf-8格式
temp = "我爱中国"
#把utf-8格式解码到Unicode格式
temp_unicode = temp.decode('utf-8')
#上一句实现的是将temp解码(decode)为Unicode格式,括号里面utf-8表示的是temp的格式
#再把Unicode格式编码成gbk格式
temp_gbk=temp_unicode.encode('gbk')
#上一句实现的是将temp_unicode编码成gbk格式,括号里面的gbk代表的是要转化成的格式
print(temp_gbk)输出结果为:

这里需要注意的还有两点:
- 对于Python 2.7来说,可以直接将Unicode给终端,微软系统会自动识别Unicode并将其转化成gbk再打印输出。
# -*- coding:utf-8 -*-
#默认为utf-8格式
temp = "我爱中国"
#把utf-8格式解码到Unicode格式
temp_unicode = temp.decode('utf-8')
print(temp_unicode)- 对于Python 3.5来说,可以直接从utf-8格式编码到gbk格式,这就相当于Python3.5内部自动将utf-8格式转化成Unicode再转化成gbk格式,因而在Python 3.5中,Unicode这一格式已经被移除了。
# -*- coding:utf-8 -*-
#默认为utf-8格式
temp = "我爱中国"
#系统内部自动实现从utf-8>-unicode>-gbk的转换
temp_gbk = temp.encode('utf-8')
print(temp_gbk)














 4073
4073

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









