







 本文详细介绍了Flume的性能优化策略,包括Source、Channel和Sink三个组件的关键参数调整,如Spooling Directory Source的batchSize和inputCharset,Memory Channel的transactionCapacity和byteCapacity,以及Sink的数据输出性能优化。此外,还强调了组件间数据传输速度一致性的重要性,以及整体架构的灵活设计和Java内存配置,为保证Flume系统的稳定性和高效运行提供了指导。
本文详细介绍了Flume的性能优化策略,包括Source、Channel和Sink三个组件的关键参数调整,如Spooling Directory Source的batchSize和inputCharset,Memory Channel的transactionCapacity和byteCapacity,以及Sink的数据输出性能优化。此外,还强调了组件间数据传输速度一致性的重要性,以及整体架构的灵活设计和Java内存配置,为保证Flume系统的稳定性和高效运行提供了指导。
flume 性能优化
flume的整体基础架构包括三个,分别是source,chanel, sink. 下面是官网的截图:
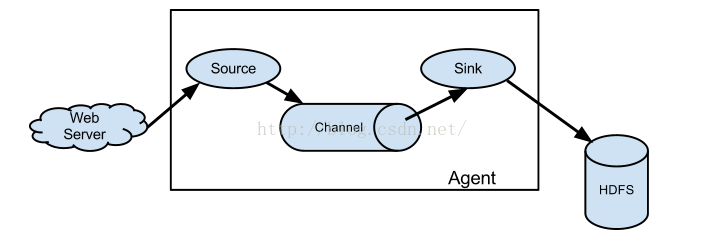
因此,优化要从三个组件的角度去分别优化。
1、source
sources是flume日志采集的起点,监控日志文件系统目录。其中最常用的是 Spooling Directory Source , Exec Source 和 Avro Source 。
关键参数讲解:
(1)batchSize: 这个参数当你采用的是 Exec Source 时,含义是一次读入channel的数据的行数,当你采用Spooling Directory Source含义是 Granularity(粒度) at which to batch transfer to the channel ,据我分析应该是events(flume最小处理数据单元)的数量。
这个参数一般 会设置比较大,一般的数值跟每秒要处理的数值相当。
(2)inputCharset 这个很重要,就是文本文件的编码,默认是flume按照utf-8处理,如果文本数据是gbk,则要增加此参数,
(3)interceptors flume自带的拦截器,可以根据正则表达式去过滤数据,但是据我实际经验总结,这个配置很影响入库性能,因此这部分工作我基本都在sink代码里面做。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 336
336

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









