







 本文深入探讨了MySQL的复制原理,包括binlog日志格式的优缺点、事务与日志实现,以及InnoDB和MyISAM的索引差异。还介绍了Seconds_Behind_Master的含义、MySQL高可用架构方案,并分享了SQL优化的思路和原则,以及Explain的使用。此外,还讲解了MySQL的配置参数,如query_cache_size和innodb_log_buffer_size,以及数据库隔离级别和锁模式。
本文深入探讨了MySQL的复制原理,包括binlog日志格式的优缺点、事务与日志实现,以及InnoDB和MyISAM的索引差异。还介绍了Seconds_Behind_Master的含义、MySQL高可用架构方案,并分享了SQL优化的思路和原则,以及Explain的使用。此外,还讲解了MySQL的配置参数,如query_cache_size和innodb_log_buffer_size,以及数据库隔离级别和锁模式。
MySQL复制原理
三个进程,两种文件。
binlog dump、IO thread、SQL thread
binlog 、relay log
以下图片截取自《高性能MySQL》
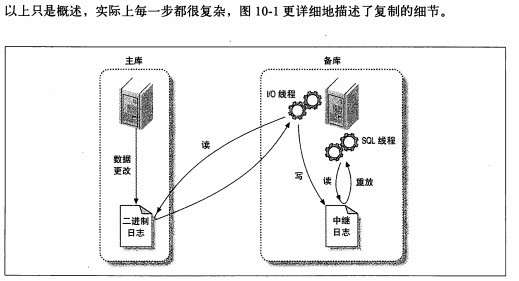
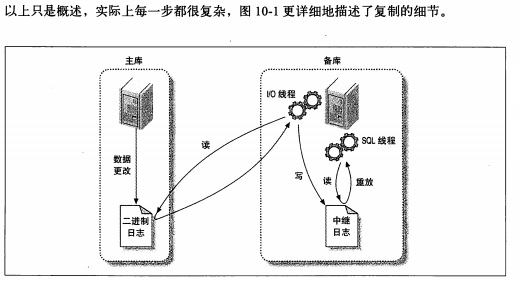


binlog日志格式的种类和优缺点
有三种格式:statement、mixed、row
1.statement:将修改数据的SQL记录在binlog中。
优点:
不需要记录每一行的变化,减少了binlog日志量,节约了IO,提高性能。
缺点:
由于记录的只是执行语句,为了这些语句能在slave上正确运行,因此还必须记录每条语句在执行的时候的一些相关信息,以保证所有语句能在slave得到和在master端执行时候相同的结果。
另外mysql 的复制,像一些特定函数功能,slave可与master上要保持一致会有很多相关问题(如sleep()函数, last_insert_id(),以及user-defined functions(udf)会出现问题)。
2.row:不记录sql语句上下文相关信息,仅保存哪条记录被修改。
优点:
binlog中可以不记录执行的sql语句的上下文相关的信息,仅需要记录那一条记录被修改成什么了。所以row level的日志内容会非常清楚的记录下每一行数据修改的细节。而且不会出现某些特定情况下的存储过程,或function,以及trigger的调用和触发无法被正确复制的问题
缺点:
所有的执行的语句当记录到日志中的时候,都将以每行记录的修改来记录,这样可能会产生大量的日志内容,比如一条update语句,修改多条记录,则binlog中每一条修改都会有记录,这样造成binlog日志量会很大,特别是当执行alter table之类的语句的时候,由于表结构修改,每条记录都发生改变,那么该表每一条记录都会记录到日志中。
3.Mixed:是以上两种level的混合使用,一般的语句修改使用statment格式保存binlog,如一些函数,statement无法完成主从复制的操作,则采用row格式保存binlog,MySQL会根据执行的每一条具体的sql语句来区分对待记录的日志形式,也就是在Statement和Row之间选择一种。
新版本的MySQL中对row level模式也被做了优化,并不是所有的修改都会以row level来记录,像遇到表结构变更的时候就会以statement模式来记录。至于update或者delete等修改数据的语句,还是会记录所有行的变更。
补充:
expire_logs_days= 7 //binlog过期清理时间
max_binlog_size=100m //binlog每个日志文件大小
sync_binlog
innodb事务与日志的实现
参考《MySQL技术内幕 Innodb存储引擎 》
Write-Ahead Logging ,WAL:预写日志方式
【1】Redo Log
在Innodb存储引擎中,事务日志是通过redo和innodb的存储引擎日志缓冲(Innodb log buffer)来实现的。
当开始一个事务的时候,会记录该事务的lsn(log sequence number)号;当事务执行时,会往InnoDB存储引擎的日志的日志缓存里面插入事务日志;当事务提交时,必须将存储引擎的日志缓冲写入磁盘(通过innodb_flush_log_at_trx_commit来控制),也就是写数据前,需要先写日志。
这种方式称为“预写日志方式”,innodb通过此方式来保证事务的完整性。也就意味着磁盘上存储的数据页和内存缓冲池上面的页是不同步的,是先写入redo log,然后写入data file,因此是一种异步的方式。通过 show engine innodb status\G 来观察之间的差距。
innodb_log_group_home_dir=/dbdata/iblogs
innodb_log_files_in_group=3
innodb_log_file_size=50M
【2】Undo
undo的记录正好与redo的相反,insert变成delete,update变成相反的update,redo放在redo file里面。而undo放在一个内部的一个特殊segment上面,存储与共享表空间内(ibdata1或者ibdata2中)。
undo不是物理恢复,是逻辑恢复,因为它是通过执行相反的dml语句来实现的。而且不会回收因为insert和upate而新增加的page页的。
undo页的回收是通过master thread线程来实现的。
在MySQL5.6中开始支持把undo log分离到独立的表空间,并放到单独的文件目录下;这给我们部署不同IO类型的文件位置带来便利,对于并发写入型负载,我们可以把undo文件部署到单独的高速存储设备上。
innodb_undo_tablespaces:用于设定创建的undo表空间的个数,在Install db时初始化后,就再也不能被改动了;默认值为0,表示不独立设置undo的tablespace,默认记录到ibdata中;否则,则在undo目录下创建这么多个undo文件,例如假定设置该值为16,那么就会创建命名为undo001~undo016的undo tablespace文件,每个文件的默认大小为10M。
innodb_undo_logs:用于表示回滚段的个数(早期版本的命名为innodb_rollback_segments),该变量可以动态调整,但是物理上的回滚段不会减少,只是会控制用到的回滚段的个数。
innodb_undo_directory:当开启独立undo表空间时,指定undo文件存放的目录。如果我们想转移undo文件的位置,只需要修改下该配置,并将undo文件拷贝过去就可以了。
当有长时间运行的事务时,可能导致purge操作来不及回收undo空间,进而导致undo空间急剧膨胀;理论上讲,如果做一次干净的shutdown,应该可以安全的将将这些undo文件删除并重新做一次初始化;也许未来的某个MySQL版本可能实现这个功能,这对于某些服务(比如按磁盘空间收费的云计算提供商)是非常有必要的功能。
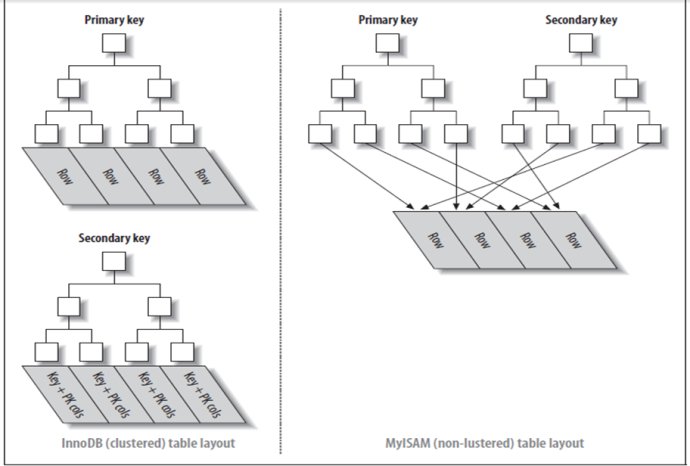
innodb与myisam的索引实现方式
参考文章:http://blog.csdn.net/zuiaituantuan/article/details/5909334
1 MyISAM只把索引载入内存,数据缓存依赖于操作系统,InnoDB把索引和数据都载入内存缓冲 。
2 MyISAM数据库中的数据是按照插入的顺序保存,在每个索引节点中保存对应的数据行的地址,理论上说主键索引和其他索引是一样的,InnoDB数据库中的数据和主键节点保存在一起,所有其他索引节点中保存的是主键索引的值。
3 对于字符串索引,MyISAM默认采用增量保存,例如第一个索引值是’perform’,第二个索引的值是’performance’, 在索引文件中第二个索引被保存为’7,ance’。这样能够减小索引的尺寸。
4 MyISAM保存索引的状态信息在磁盘里,每次执行ANALYZE TABLE会更新这个信息。InnoDB则通过在启动的时候随机读取索引来估计索引的状态信息,所以Show Index的结果对于MyISAM是精准的,但对于InnoDB不是绝对精准。
5 索引长期运行之后会产生碎片,一种碎片是一行数据被保存在不同的数据段,另一种是连续的表空间或行在磁盘上被分散地保存。对于MyISAM两种索引碎片都会出现,对于InnoDB只会出现后一种因为InnoDB不会把短行保存到不同的数据段。要消除索引碎片一种方法是OPTIMIZE TABLE,另一种方法是把数据重新倒入。
针对MyISAM和InnoDB不同的索引结构,要注意以下几点:
1 在InnoDB表中插入数据一定要尽可能按照主键增加的顺序,AUTO_INCREMENT最好,这样插入的速度最快。
2 因为InnoDB索引节点中保存的是主键的值,所以主键的值越简单越好。
3 对于InnoDB表,在查询的时候如果只需要查找索引列,就不要加入其它列,这样速度最快。
索引逻辑结构:左边为innodb,右边为myisam。
Seconds_Behind_Master的确切含义
mysql在binlog中会记录event时间戳。binlog复制到slave节点并通过sql thread应用时,slave节点的时间和binlog中记录的event的时间戳之间的差就是Seconds_Behind_Master。
也就是说,如果slave节点系统时间比master节点系统时间晚一个小时,则每次有binlog event从master传输到slave并应用时,seconds_behind_master至少为3600。
一些MySQL高可用架构方面的言论
关于MySQL-HA,目前有多种解决方案,比如heartbeat、drbd、mmm、共享存储,但是它们各有优缺点。heartbeat、drbd配置较为复杂,需要自己写脚本才能实现MySQL自动切换,对于不会脚本语言的人来说,这无疑是一种脑裂问题;对于mmm,生产环境中很少有人用,且mmm 管理端需要单独运行一台服务器上,要是想实现高可用,就得对mmm管理端做HA,这样无疑又增加了硬件开支;对于共享存储,个人觉得MySQL数据还是放在本地较为安全,存储设备毕竟存在单点隐患。使用MySQL双master+keepalived是一种非常好的解决方案,在MySQL-HA环境中,MySQL互为主从关系,这样就保证了两台MySQL数据的一致性,然后用keepalived实现虚拟IP,通过keepalived自带的服务监控功能来实现MySQL故障时自动切换。
MySQL 高可用架构之MMM
简介
MMM(Master-Master replication manager for MySQL)是一套支持双主故障切换和双主日常管理的脚本程序。MMM使用Perl语言开发,主要用来监控和管理MySQL Master-Master&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 213
213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









